
[Spark] 3. RDD Ⅱ

1. RDD Transformation 연산 Ⅱ
- 이전 장의 내용에 이어서 나머지 Transformation 연산에 대해 설명하고자 한다.
1) aggregateByKey
- RDD의 구성요소가 키와 값의 쌍으로 구성된 경우에 사용할 수 있는 메소드이다.
- combineByKey() 와 달리 병합의 초기값을 알기 위해 zeroValue라는 값을 사용한다.
- combineByKey() 에서 createCombiner() 함수로 특정 값 zero를 돌려주는 함수를 사용한 경우로 간주할 수 있음
[Java code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doAggregateByKey(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doAggregateByKey(JavaSparkContext sc) {
List<Tuple2<String, Long>> data = Arrays.asList(new Tuple2("Math", 100L), new Tuple2("Eng", 80L), new Tuple2("Math", 50L), new Tuple2("Eng", 70L), new Tuple2("Eng", 90L));
JavaPairRDD<String, Long> rdd = sc.parallelizePairs(data);
// Java7
Record zero = new Record(0, 0);
Function2<Record, Long, Record> mergeValue = new Function2<Record, Long, Record>() {
@Override
public Record call(Record record, Long v) throws Exception {
return record.add(v);
}
};
Function2<Record, Record, Record> mergeCombiners = new Function2<Record, Record, Record>() {
@Override
public Record call(Record r1, Record r2) throws Exception {
return r1.add(r2);
}
};
JavaPairRDD<String, Record> result = rdd.aggregateByKey(zero, mergeValue, mergeCombiners);
// Java8
JavaPairRDD<String, Record> result2 = rdd.aggregateByKey(zero, (Record record, Long v) -> record.add(v), (Record r1, Record r2) -> r1.add(r2));
System.out.println(result.collect());
System.out.println(result2.collect());
}
}
[결과]
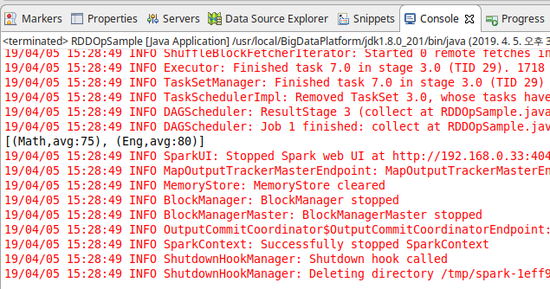
2) pipe
- 데이터 처리과정에서 외부 프로세스를 사용할 때 사용함
[Java code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doPipe(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doPipe(JavaSparkContext sc)
{
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("1,2,3", "4,5,6", "7,8,9"));
JavaRDD<String> result = rdd.pipe("cut -f 1,3 -d ,");
System.out.println(result.collect());
}
}
[결과]
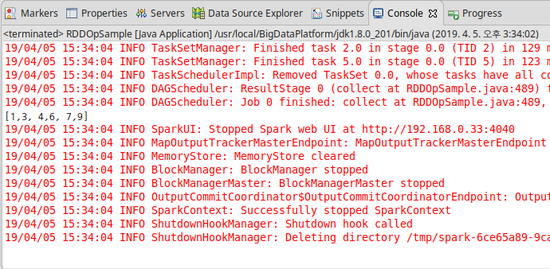
3) coalesce & repartition
- 현재 RDD의 파티션 개수를 조정할 수 있다.
- 모두 파티션의 크기를 나타내는 정수를 인자로 받아 파티션의 수를 조정한다는 공통점이 있으나, repartiton의 경우 파티션 수를 늘리거나 줄이는 것을 모두 할 수 있으며, coalesce는 줄이는 것만 가능하다.
[Java code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doCoalesceAndRepartition(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doCoalesceAndRepartition(JavaSparkContext sc)
{
JavaRDD<Integer> rdd1 = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 0), 10);
JavaRDD<Integer> rdd2 = rdd1.coalesce(5);
JavaRDD<Integer> rdd3 = rdd2.coalesce(10);
System.out.println("partition size:" + rdd1.getNumPartitions());
System.out.println("partition size:" + rdd2.getNumPartitions());
System.out.println("partition size:" + rdd3.getNumPartitions());
}
}
[결과]
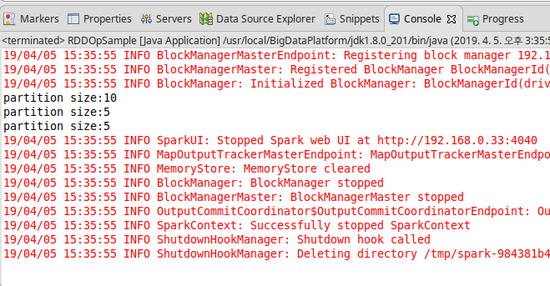
4) partitionBy
- RDD의 구성요소가 키와 값의 쌍으로 구성된 경우에 사용할 수 있는 메소드이다.
- org.apache.spark.Partitioner 클래스의 인스턴스를 인자로 전달해야 사용가능하다.
-
RDD의 파티션 생성 기준을 변경하고 싶다면 직접 Partitioner 클래스를 상속하고 커스터마이징한 뒤 partitionBy() 메소드의 인자로 전달해서 사용한다.
- Partitioner
- 각 요소의 키를 특정 파티션에 할당하는 역할을 수행
- 스파크에서 기본적으로 제공하는 것
- HashPartitioner, RangePartitioner라는 2종류가 있다.
[Java code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doRepartitionAndSortWithinPartitions(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doRepartitionAndSortWithinPartitions(JavaSparkContext sc)
{
List<Integer> data = fillToNRandom(10);
JavaPairRDD<Integer, String> rdd1 = sc.parallelize(data).mapToPair((Integer v) -> new Tuple2(v, "-"));
JavaPairRDD<Integer, String> rdd2 = rdd1.repartitionAndSortWithinPartitions(new HashPartitioner(3));
rdd2.foreachPartition(new VoidFunction<Iterator<Tuple2<Integer, String>>>()
{
@Override
public void call(Iterator<Tuple2<Integer, String>> it) throws Exception
{
System.out.println("==========");
while (it.hasNext())
{
System.out.println(it.next());
}
}
});
}
}
[결과]
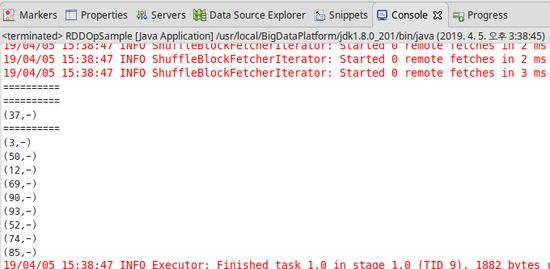
5) filter
- RDD의 요수 중에서 원하는 요소만 남기고원하지 않는 요소는 걸러내는 동작을 하는 메소드이다.
- 동작 방식은 RDD의 어떤 요소가 원하는 조건에 부합하는지 여부를 참, 거짓으로 가려내는 함수를 RDD의 각 요소에 적용해 그 결과가 참인 것을 남기고 거짓인 것은 버리게 된다.
- 보통 filter 연산은 처음 RDD를 생성 후 다른 처리를 수행하기 전에 불필요한 요소를 사전에 제거 하는 것이 목적이다.
- 필터링 연산 후에 파티션 크기를 변경하고자 한다면 이전에 본 coalesce() 메소드 등을 사용해 RDD 파티션 수를 줄어든 크기에 맞춰 조정할 수 있다.
[Java code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doFilter(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doFilter(JavaSparkContext sc)
{
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
JavaRDD<Integer> result = rdd.filter(new Function<Integer, Boolean>()
{
@Override
public Boolean call(Integer v1) throws Exception
{
return v1 > 2;
}
});
System.out.println(result.collect());
}
}
[결과]
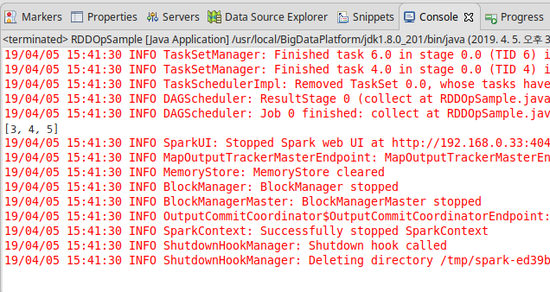
6) sortByKey
- 키 값을 기준으로 요소를 정렬하는 연산이다.
- 사용되는 모든 요소는 키 : 값 형태로 이루어져야 한다.
[Java code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doSortByKey(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doSortByKey(JavaSparkContext sc)
{
List<Tuple2<String, Integer>> data = Arrays.asList(new Tuple2("q", 1), new Tuple2("z", 1), new Tuple2("a", 1));
JavaPairRDD<String, Integer> rdd = sc.parallelizePairs(data);
JavaPairRDD<String, Integer> result = rdd.sortByKey();
System.out.println(result.collect());
}
}
[결과]
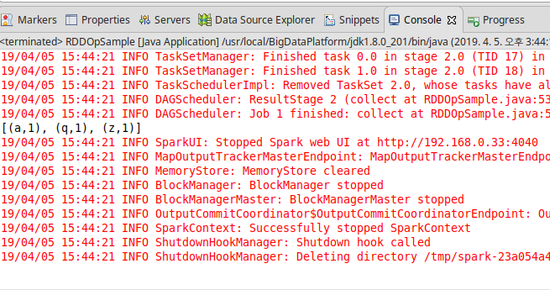
7) sample
- 샘플을 추출해 새로운 RDD를 생성할 수 있다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doSample(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doSample(JavaSparkContext sc)
{
List<Integer> data = fillToN(100);
JavaRDD<Integer> rdd = sc.parallelize(data);
JavaRDD<Integer> result1 = rdd.sample(false, 0.5);
JavaRDD<Integer> result2 = rdd.sample(true, 1.5);
System.out.println(result1.take(5));
System.out.println(result2.take(5));
}
}
[결과]
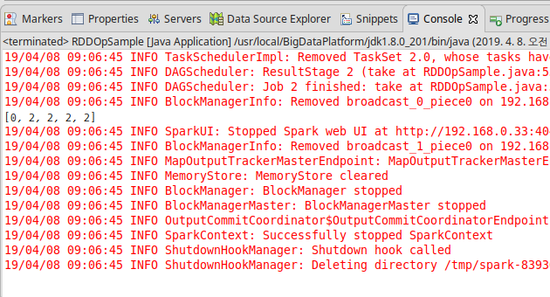
2. RDD 액션
- RDD 메소드 중에서 결과값이 정수, 리스트, 맵이 아닌 다른 타입인 것들을 통칭해서 부르는 용어다.
-
트랜스포메이션 과의 차이점은 결과값이 RDD이고, Lazy Evaluation 방식을 채택하고 있다는 점이다.
- Lazy Evaluation
- 메소드를 호출하는 시점에 바로 실행하는 것이 아니라, 계산에 필요한 정보를 누적해 내포하고 있다가 실제로 계산이 필요할 시에 매번 동일한 수행을 반복하는 형태로 구현된다.
- 주로 트랜스포메이션 연산에 사용되고, 함수형 프로그래밍에서도 많이 사용되는 구조이다.
1) first
- RDD 요소 중 첫 번째 요소를 반환해준다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doFirst(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doFirst(JavaSparkContext sc)
{
List<Integer> data = Arrays.asList(5, 4, 1);
JavaRDD<Integer> rdd = sc.parallelize(data);
int result = rdd.first();
System.out.println(result);
}
}
[결과]
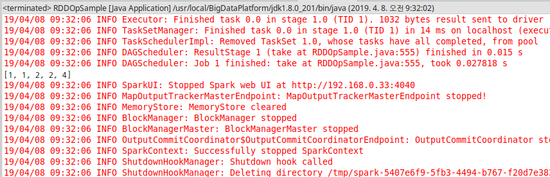
2) take
- RDD의 첫 번째 요소로부터 순서대로 n개를 추출해서 되돌려주는 메소드이다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doSortByKey(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doTake(JavaSparkContext sc)
{
List<Integer> data = fillToN(100);
JavaRDD<Integer> rdd = sc.parallelize(data);
List<Integer> result = rdd.take(5);
System.out.println(result);
}
}
[결과]
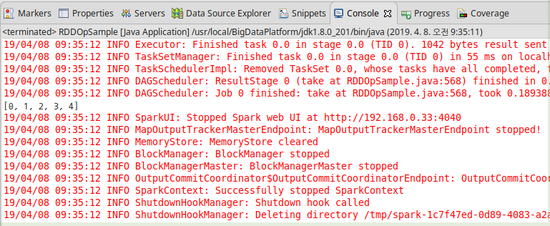
3) takeSample
- RDD 요소 중 지정된 크기의 샘플을 추출하는 메소드이며 sample()과 유사하지만 샘플의 크기를 지정할 수 있다는 점에서 차이가 있다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doTakeSample(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doTakeSample(JavaSparkContext sc) {
List<Integer> data = fillToN(100);
JavaRDD<Integer> rdd = sc.parallelize(data);
List<Integer> result = rdd.takeSample(false, 20);
System.out.println(result.size());
}
}
[결과]
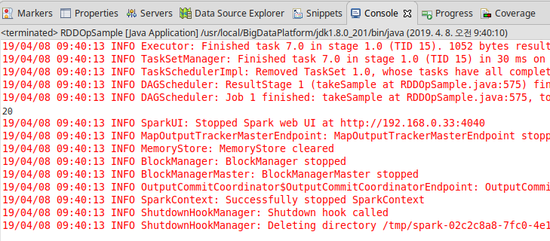
4) countByValue
- RDD에 속하는 각 값들이 나타나는 횟수를 구해서 맵 형태로 돌려주는 메소드로 reduce() 나 fold()를 떠올리기 전에 countByValue()를 적용할 수 있는지 검토해보는 것이 좋다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample {
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doCountByValue(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doCountByValue(JavaSparkContext sc)
{
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 1, 2, 3, 3));
Map<Integer, Long> result = rdd.countByValue();
System.out.println(result);
}
}
[결과]
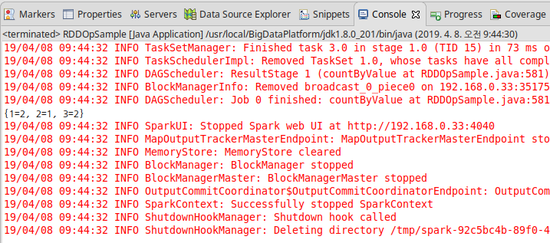
5) reduce
- RDD에 포함된 임의의 값 2개를 하나로 합치는 함수를 이용해 RDD에 포함된 모든 요소를 하나의 값으로 병합하고 결과값을 반환하는 메소드이다.
- 한 가지 주의점으로 스파크 애플리케이션이 클러스터 환경에서 동작하는 분산 프로그램이기 때문에 실제 병합이 첫 번째 요소부터 마지막 요소까지 순서대로 처리되는 것이 아니라 흩어진 파티션 단위로 나눠져서 처리된다는 것이다.
- 따라서 Reduce 메소드 에 적용하는 병합 연산은 RDD에 포함된 모든 요소에 대해 교환, 결합 법칙이 성립되는 경우에만 사용 가능하다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doReduce(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doReduce(JavaSparkContext sc)
{
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> rdd = sc.parallelize(data, 3);
// Java7
int result = rdd.reduce(new Function2<Integer, Integer, Integer>()
{
@Override
public Integer call(Integer v1, Integer v2) throws Exception
{
return v1 + v2;
}
});
// Java8
int result2 = rdd.reduce((Integer v1, Integer v2) -> v1 + v2);
System.out.println(result);
System.out.println(result2);
}
}
[결과]
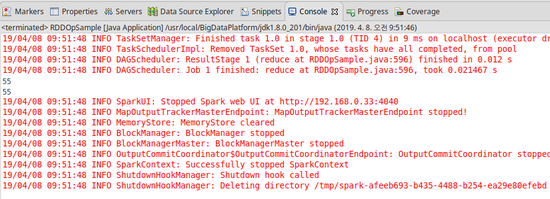
6) fold
- reduce() 와 같이 RDD 내의 모든 요소를 대상으로 교환, 결합법칙이 성립되는 바이너리 함수를 순차 적용해 최종 결과를 구하는 메소드이다.
- reduce() 와의 차이점은 RDD에 포함된 요소만 이용해 병합을 수행하는 반면, fold() 연산은 병합 연산의 초기값을 지정해 줄 수 있다는 점이다.
- 주의사항으로 reduce() 와 마찬가지로 여러 서버에 흩어진 파티션에 대해 병렬로 처리된다는 것이다. 따라서 fold() 메소드에 지정한 초기값은 각 파티션 별로 부분 병합을 수행할 때마다 사용되기 때문에 여러 번 반복해도 문제가 없는 값을 사용해야 한다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doFold(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doFold(JavaSparkContext sc)
{
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> rdd = sc.parallelize(data, 3);
// Java7
int result = rdd.fold(0, new Function2<Integer, Integer, Integer>()
{
@Override
public Integer call(Integer v1, Integer v2) throws Exception
{
return v1 + v2;
}
});
// Java8
int result2 = rdd.fold(0, (Integer v1, Integer v2) -> v1 + v2);
System.out.println(result);
System.out.println(result2);
}
}
[결과]
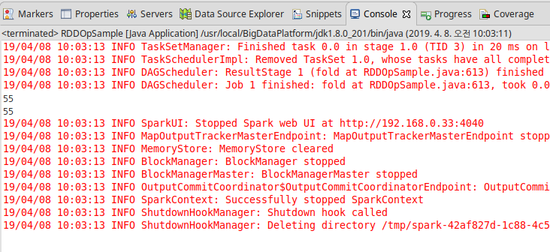
7) aggregate
- reduce() 와 fold() 메소드랑 달리, aggregate()의 경우에는 타입에 대한 제약사항이 없기 때문에 입력과 출력의 타입이 다른 경우에도 사용가능하다.
- 메소드의 인자는 총 3개를 사용하며, 첫 번째로 fold() 와 유사한 초기값을 지정하는 것이고, 두 번째는 각 파티션 단위 부분합을 구하기 위한 병합함수, 마지막으로 파티션 단위로 생성된 부분합을 최종적으로 하나로 합치기 위해 다른 병합함수로 구성된다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doAggregate(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doAggregate(JavaSparkContext sc)
{
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(100, 80, 75, 90, 95), 3);
Record zeroValue = new Record(0, 0);
// Java7
Function2<Record, Integer, Record> seqOp = new Function2<Record, Integer, Record>()
{
@Override
public Record call(Record r, Integer v) throws Exception
{
return r.add(v);
}
};
Function2<Record, Record, Record> combOp = new Function2<Record, Record, Record>()
{
@Override
public Record call(Record r1, Record r2) throws Exception
{
return r1.add(r2);
}
};
Record result = rdd.aggregate(zeroValue, seqOp, combOp);
// Java8
Function2<Record, Integer, Record> seqOp2 = (Record r, Integer v) -> r.add(v);
Function2<Record, Record, Record> combOp2 = (Record r1, Record r2) -> r1.add(r2);
Record result2 = rdd.aggregate(zeroValue, seqOp2, combOp2);
System.out.println(result);
System.out.println(result2);
}
}
[결과]
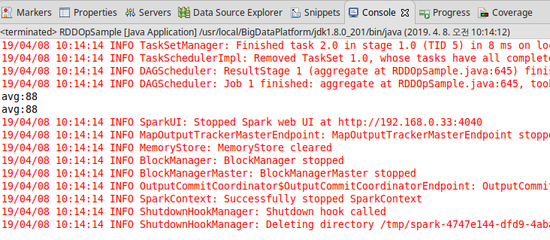
8) sum
- 스파크에서는 RDD를 구성하는 요소의 타입에 따라 좀 더 특화된 편리한 연산을 제공하기 위해 특정 타입의 요소로 구성된 RDD에서만 사용 가능한 메소드를 정의하고 있다.
- sum의 경우 RDD를 구성하는 모든 요소가 double 이나 Long 등 숫자 타입일 경우에만 사용가능하고 전체 요소의 합을 구해준다.
[Java Code]
package com.spark.example;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.*;
import java.util.stream.Collectors;
public class RDDOpSample
{
public static void main(String[] args) throws Exception
{
JavaSparkContext sc = getSparkContext();
doSum(sc);
sc.stop();
}
public static JavaSparkContext getSparkContext()
{
SparkConf conf = new SparkConf().setAppName("RDDOpSample").setMaster("local[*]");
return new JavaSparkContext(conf);
}
public static void doSum(JavaSparkContext sc)
{
List<Double> data = Arrays.asList(1d, 2d, 3d, 4d, 5d, 6d, 7d, 8d, 9d, 10d);
JavaDoubleRDD rdd = sc.parallelizeDoubles(data);
double result = rdd.sum();
System.out.println(result);
}
}
[결과]
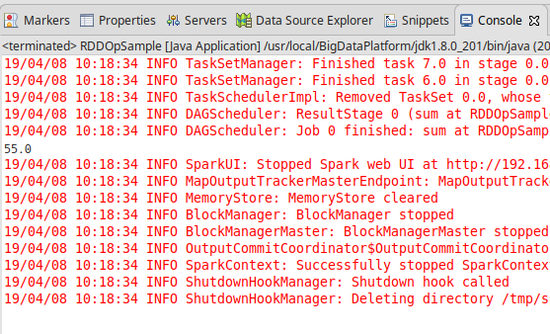
- 이 외에 다른 메소드들이 많지만 내용이 너무 많은 관계로 사용 시에 설명하도록 하겠다.
댓글남기기