
[Spark] 1. Apache Spark 개요 및 설치

1. Apache Spark
- 하둡 기반의 맵리듀스 작업이 가진 단점들을 보완하기 위해서 만들어 진 프레임워크로, 하둡과 달리 인메모리(In-Memory) 기법을 활용한 데이터 저장 방식을 제공함으로써 머신러닝 등 반복적인 데이터 처리가 필요한 분야에서 높은 성능을 보여준다.
- 작업을 실행하기 전에 최적의 처리 흐름을 찾는 과정을 포함하고 있었기 때문에 성능 향상과 더불어 여러 개의 맵리듀스 잡을 직접 순차적으로 실행하는 수고를 덜어줬다.
- 이외에 실시간 스트리밍 데이터를 다루기 위한 스파크 스트리밍과 하이브와 연동도 가능한 스키마 기반 데이터 분석모듈인 스파크 SQL, R과 연동가능한 sparkR 등 데이터 처리 분야에 특화된 라이브러리도 지원해준다.
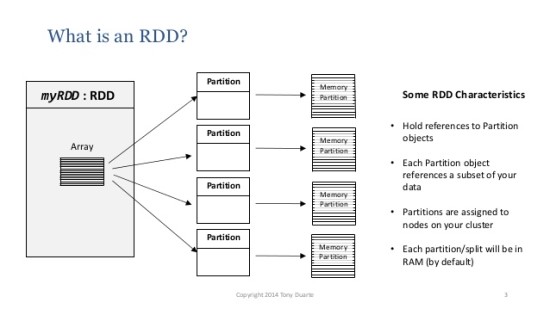
1) RDD(Resilient Distributed Dataset)
- 스파크가 제공하는 일종의 분산 데이터에 대한 모델이자 핵심 데이터 모델로, 다수의 서버에 걸쳐 분산 방식으로 저장된 데이터 요소들의 집합을 의미한다.
- 동시에 병렬로 명령처리가 가능하고 장애가 발생할 경우 스스로 복구될 수 있는 내성을 가지고 있다.
-
스파크에서는 하나의 작업을 수행할 때 파티션 단위로 나눠서 병렬로 처리한다. 또한 작업이 진행되는 동안 재구성되거나 네트워크를 통해 다른 서버로 이동하는 셔플링 현상이 발생할 수 있다.
- 다수의 서버에 나눠져서 처리되기 때문에 유실이 발생할 수 있지만 이를 위해 원래 상태로 복구할 수 있도록 RDD의 생성과정을 기록해 뒀다가 다시 복구해주는 기능을 가지고 있다.
-
또한 문제가 발생 시 전체작업을 처음부터 다시 실행하는 대신 문제가 발생한 RDD를 생성했던 작업만 다시 수행해서 복구를 진행한다.
- 리니지(Lineage): 스파크에서 RDD 생성 작업을 기록해 두는 것을 의미하며, DAG 형태로 저장된다. RDD 를 생성하는 모든 과정이 저장되기 때문에, 메모리에서 데이터가 유실되면, lineage 의 기록에 따라 유실된 RDD를 복구할 수 있다.
(1) 생성 방법
- List, Set 같은 기존 프로그램의 메모리에 생성된 데이터를 이용하는 것을 의미한다.
→ 즉시 테스트해 볼 수 있어 테스트 코드 작성 등에 유용하게 사용됨
ex. Collection 을 이용
[Java Code]
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("a", "b", "c", "d", "e"));
[Scala Code]
val rdd = sc.parallelize(List("a", "b", "c", "d", "e"))
[Python Script]
rdd = sc.parallelize(["a", "b", "c", "d", "e"])
- 로컬 파일시스템이나 하둡의 HDFS 같은 외부 저장소에 저장된 데이터를 읽어서 생성하는 방법 -> 다양한 유형의 데이터 소스로부터 데이터를 읽고 RDD를 생성할 수 있다.
ex. 파일로부터 생성
[Java Code]
JavaRDD<String> rdd = sc.textFile("<path_to_file>");
[Scala Code]
val rdd = sc.textFile("<path_to_file>")
[Python Script]
rdd = sc.textFile("<path_to_file>")
- 기존에 생성돼 있는 RDD로부터 또 다른 RDD를 생성하는 방법으로 연산의 결과를 저장한다.
- createRDD 같은 함수가 제공되는 것은 아니지만 기존 RDD의 모든 요소에 1을 더하는 등의 연산을 적용하면 “한 번 만들어지면 수정불가하다” 는 성질을 이용해 새로운 RDD 가 생성되는 것이다.
ex. 기존 RDD로부터 새로운 RDD 생성
[Java Code]
JavaRDD<String> rdd1 = rdd.map(new Function<String, String>() {
@Override
public String call(String v1) throws Exception {
return v1.toUpperCase();
}
});
- JAVA 8 의 경우 다음과 같이 한다.
[Java Code]
JavaRDD<String> rdd1 = rdd.map(v -> v.toUpperCase());
[Scala Code]
val rdd1 = rdd.map(_.toUpperCase())
[Python Script]
rdd1 = rdd.map(lambda s : s.upper())
(2) 연산
- 크게 Transformation. Action 으로 분류된다.
- Transformatoion
- 어떤 RDD에 변형을 가해 새로운 RDD를 생성하는 연산
- 기존 RDD는 바뀌지 않은 상태에서 변형된 값을 가진 새로운 RDD 가 생성된다.
-> RDD에 대한 생성 계보만 만들면서 쌓아 두고 액션 연산이 호출되면 한꺼번에 수행됨 - 때문에 본격적인 작업 실행 전에 데이터가 어떤 방법과 절차에 따라 변형되어야 하는지 알 수 있다는 장점을 가진다.
- Action
- 해당 연산의 결과로 RDD가 아닌 다른 값을 반환하거나 아예 반환하지 않는 연산을 의미함
- sum(), stddev() 등의 메소드는 RDD 의 모든 요소가 숫자형인 경우에 사용이 가능함
- groupByKey() 메소드의 경우 키와 값싸으로 구성된 RDD 에서만 사용가능
2) DAG(Directed Acyclic Graph)
- 그래프 이론에서 사용되는 용어로 여러 개의 꼭짓점 또는 노드와 그사이를 이어주는 방향성을 지닌 선으로 구성되고 그래프를 구성하는 꼭짓점, 노드 에서 출발하더라도 다시 원래의 꼭짓점으로 돌아오지 않도록 구성된 그래프 모델을 의미한다.
- 스파크에서 각 단계마다 최적화된 작업을 수행하기 위해 사용해야되는 데이터 처리용 라이브러리가 다를 수 있기 때문에 서로 다른 라이브러리를 잘 조합해서 사용할 수 있도록 일련의 작업 흐름을 나타내는 워크 플로우
(1) DAG 스케쥴러
- DAG 생성을 담당하는 부분
- 동작 방식
- 전체 작업을 스테이지라는 단위로 나누어 실행하고 각 스테이지를 다시 여러 개의 태스크로 나누어 실행
- 드라이버의 메인 함수에서 스파크 애플리케이션과 스파크 클러스터의 연동을 담당하는 스파크 컨텍스트라는 객체를 생성하고 이를 이용해 잡을 실행하고 종료하는 역할을 수행한다.
- 스파크컨텍스트를 통해 RDD의 연산 정보를 DAG스케줄러에게 전달하면 스케줄러는 해당 정보를 이용해 실행 계획을 수립한 후 클러스터매니저에게 전달한다.
- 전체 데이터 처리 흐름을 분석해 네트워크를 통한 데이터 이동이 최소화되도록 스테이지를 구성한다.
- 스케줄러의 역할: 대상 데이터의 크기를 줄여 셔플로 인한 부하를 최소화하는 것
(2) 좁은 의존성 vs. 넓은 의존성
- 좁은 의존성: 기존 RDD와 신생 RDD의 관계가 작은 경우를 의미( ex. 1:1 대응인 경우)
- 넓은 의존성: 기존 RDD가 여러 신생 RDD와 관계를 맺는 경우를 의미 (ex. 1:N 대응인 경우)
3) 람다 아키텍쳐
- 네이션 마츠가 제안한 모델로 빅데이터 처리를 위한 시스템을 구성하는 방법 중 하나이다.
- 빅데이터의 활용 분야가 넓어지면서 기존과 같은 대량의 데이터 처리는 몰론, 실시간 로그 분석과 같은 실시간 처리도 매우 중요해지는 상황이기 때문에 이를 만족 시키기 위한 아키텍쳐로 채택됨
-
크게 일괄처리 계층과 속도 계층으로 나뉨
- 과정
- 새로운 데이터는 일괄 처리 계층과 속도 계층 모두에 전달된다.
- 일괄처리 계층은 원본 데이터를 저장하고 일정 주기마다 한 번씩 일괄적으로 가공해서 배치 뷰를 생성한다.
- 속도 계층은 들어오는 데이터를 즉시 또는 매우 짧은 주기로 처리해 실시간 뷰를 생성한다.
- 서빙 계층은 실시간 뷰와 배치 뷰의 결과를 적절히 조합해 사용자에게 데이터를 전달한다.
- 서빙 계층을 거치지않고 배치 뷰 또는 실시간 뷰를 직접 조회할 수도 있다.
-> 일괄 처리 작업을 통해 데이터를 처리하되 아직 배치 처리가 수행되지 않은 부분은 실시간 처리를 통해 보완한다는 개념이다.
-> 이 경우 속도 계층의 처리 결과는 다소 정확하지 않을 수 있지만 추후에 일괄 처리 작업을 통해 다시 보정하는 형태로 운영될 수 있다.
2. Maven 프로젝트로 개발환경 구성하기
1) JDK
- 리눅스의 경우에는, open-jdk를 먼저 제거한 후 http://java.oracle.com 에서 jdk를 다운로드 받는다.
- Java8 의 경우 람다식을 사용하므로 이 후에 다뤄질 예정이기 때문에 Java8 버전이상으로 설치한다. (최신버전의 스파크는 Java 17 버전을 사용함)
- 설치 후 설치 위치(PATH)를 환경 변수에 적용시켜준다.
2) Maven 설치
- 자바 프로젝트 통합 관리 도구로서 자바 개발자에게는 익숙한 도구이다.
- http://maven.apache.org 에서 다운로드 받을 수 있으며 3.x 버전 중 바이너리 파일로 다운로드 받는다.
- 설치 후 설치 위치(PATH)를 환경 변수에 적용시켜준다.
- install new software -> http://alchim31.free.fr/m2e-scala/update-site 에서 설치 진행
- Eclipse 에서 Maven 프로젝트 실행 시 pom.xml 에 추가해야 되는 내용
[pom.xml]
...
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>스칼라 라이브러리 버전</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_코어 버전</artifactId>
<version>스파크 버전</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_스파크SQL 버전</artifactId>
<version>스파크 버전</version>
</dependency>
...
ex.
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.11</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.3</version>
</dependency>
...
- maven 빌드 전에 최신의 상태를 유지하기 위해 repository를 재설치 혹은 업데이트 해준다.
3) Spark 설치
- http://spark.apache.org 에서 다운로드 받을 수 있으며, 설치한 하둡 버전에 맞춰 설치해주면 된다.
- 현 단계에서는 앞서 설정한 Maven 프로젝트를 통해 실행할 때, 정상적으로 실행되는지 확인하기 위한 작업이므로, 별도의 설정파일 수정 없이 실행이 잘 되는지만 확인해 볼 예정이다.
- 설치하게되면 앞선 프로그램들과 마찬가지로 시스템 환경 변수에 설치 경로(PATH)를 저장한다.
- 정상 작동하는지 확인하기위해 간단한 테스트를 시행한다.
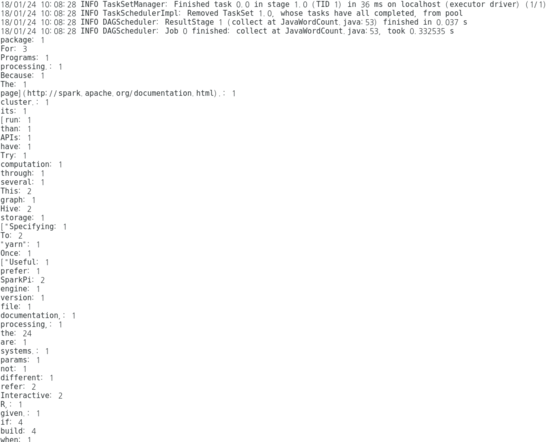
- 추가적으로 ./bin/spark-shell 을 실행시켜본다.
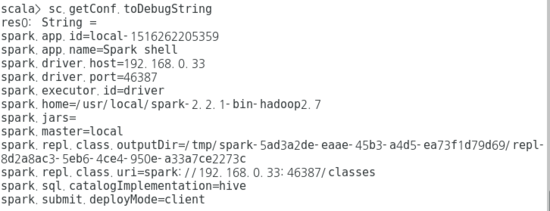
- 아래 결과에 대한 실행 결과는 다음과 같다.
[Scala code]
val file = sc.textFile("file://[스파크 설치 위치(절대경로로 입력할 것!)]/README.md")
val words = file.flatMap(_.split(" "))
val result = words. countByValue
result.get("For"). get
[실행 결과]
res1: Long = 3
- 마지막으로 웹 브라우저에서 [자신의 IP 주소]:4040 으로 환경이 제공되는지 확인한다.
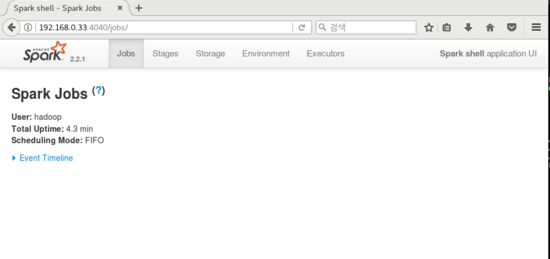
4) 파이썬 설치
- 스파크에서는 파이썬 2.6 / 3.4 이상의 버전을 지원한다.
- https://www.anaconda.com/download/ 에서 다운로드 받을 수 있다.
- 설치 이후 환경변수에 설치 경로를 추가시킨다.
5) 스칼라 IDE 설치
- 스파크는 스칼라, 파이썬, R 을 지원한다. 그 중 스칼라는 eclipse를 기반으로 IDE 가 제공된다. 현재 환경에서는 스칼라와 스칼라IDE 모두 설치한다.
- https://www.scala-lang.org/download/2.11.8.html 와 http://scala-ide.org/ 에서 설치가 가능하다.
6) 파이썬 플러그인 설치
- Help - Install New Software - Add - Name 에 “PyDev” 입력 - PyDev 플러그인 설치
- Preference - PyDev - Interpreters - Python Interpreter 에서 새로운 인터프리터를 설치
- 바로 아래의 Libraries 탭을 눌러 스파크 라이브러리를 추가한다.
- New Egg/Zip(s)-[python 설치 경로]/lib/py4j-0.10.4-src.zip 을 설치한다.
- 마지막으로 Environment 에서 SPARK_HOME과 PYSPARK_PYTHON 변수를 생성한다.
SPARK_HOME 은 스파크 설치 위치, PYSPARK-PYTHON은 파이썬 설치 위치를 입력한다.
3. 설정파일 수정하기
- Spark 는 크게 StandAlone 모드와 Cluster 모드 방식으로 동작한다고 볼 수 있다.
- 이번 장에서는 StandAlone 모드에서 Cluster 모드 순으로 설정파일을 어떻게 수정하는 지를 설명할 예정이며, 사용 유형에 따라 불필요한 부분은 넘어가도 좋다.
1) StandAlone 모드로 수정하기
- 다음으로 설정파일을 수정해주기로 하자.
- 아래 나오는 설정은 Master 기준이며, Datanode 의 경우 .bashrc 에서 Python, Maven, Scala는 지정하지 않아도 된다.
[~/.bashrc]
export JAVA_HOME=/usr/local/BigDataPlatform/jdk1.8.0_161
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/BigDataPlatform/hadoop-2.8.3
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_CONF_DIR
export SCALA_HOME=/usr/local/BigDataPlatform/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
export MAVEN_HOME=/usr/local/BigDataPlatform/apache-maven-3.5.2
export PATH=$PATH:$MAVEN_HOME/bin
export PYTHON_HOME=/usr/local/BigDataPlatform/anaconda3
export PATH=$PATH:$PYTHON_HOME/bin
export SPARK_HOME=/usr/local/BigDataPlatform/spark-2.3.0-bin-hadoop2.7
export SPARK_CONF_DIR=/usr/local/BigDataPlatform/spark-2.3.0-bin-hadoop2.7/conf
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_CONF_DIR
....
[conf/spark-env.sh]
export HADOOP_CONF_DIR=${HADOOP}/etc/hadoop
export PSPARK_PYTHON=[파이썬 설치 경로]/bin/python
...
[conf/slaves]
datanode1
datanode2
[conf/spark-defaults.conf]
spark.yarn.am.memory=1g
spark.executor.instances=3
2) datanode 에 배포
root 계정으로 spark 설치 위치에서 다음 명령 수행
# $ rsync -av . [도메인] : [설치 경로]
ex. $rsync -av . hadoop@datanode1:/usr/local/BigDataPlatform/spark-2.3.0-bin-hadoop2.7
3) 실행
master : [스파크 경로]/sbin/start-master.sh
datanode : [스파크 경로]/sbin/start-slave.sh spark://master:7077
* 중지 는 start -> stop으로 변경하면 됨
- 실행 시, start-all.sh 명령어로 실행하면 전체 실행이 가능하다.
- ```shell
[스파크 경로]/sbin/start-all.sh
## 2) 모드에 따른 spark-submit
### (1) Client mode (기본값)
```shell
$ ./bin/spark-submit --class com.spark.WordCount \
--master spark://master:7077 \
~/workspace/deploy/WordCount.jar \
hdfs://master:9000/sample/README.md \
hdfs://master:9000/sample/output/
(2) Cluster mode
- 수행 조건 : .jar 파일이 모든 노드에 존재해야한다(Cluster 모드 의 정의)
-
배포 방법
1) scp , rsync 를 사용해 master 및 datanode 노드에 배포한다.
2) .jar 파일을 HDFS 에 업로드 한 후 명령어 옵션에서 파일 위치를 HDFS에 업로드한 위치로 변경한다.$ ./bin/spark-submit --class com.spark.WordCount \ --master spark://master:6066 \ --deploy-mode cluster \ hdfs://master:9000/sample/WordCount.jar \ hdfs://master:9000/sample/README.md \ hdfs://master:9000/sample/output1/
3) Cluster 모드로 수정하기 (Spark On Yarn)
- Cluster 구성은 MasterNode 1대 , DataNode 2대 기준으로 설정한 내용임
[spark-env.sh]
* PSPARK_PYTHON, SCALA_HOME 내용은 Master만 (datanode에는 적용 안해도 됨)
export PSPARK_PYTHON=/usr/local/BigDataPlatform/anaconda3/bin/python
export SCALA_HOME=/usr/local/BigDataPlatform/scala-2.11.8
export JAVA_HOME=/usr/local/BigDataPlatform/jdk1.8.0_161
export SPARK_HOME=/usr/local/BigDataPlatform/spark-2.3.0-bin-hadoop2.7
export HADOOP_HOME=/usr/local/BigDataPlatform/hadoop-2.8.3
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_URI=hdfs://master:9000/spark-2.3.0-bin-hadoop2.7.tgz
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
[spark-default.conf]
spark.master spark://master:7077
spark.driver.memory 5g
spark.yarn.am.memory 1g
spark.yarn.access.hadoopFileSystems=hdfs://master:9000,webhdfs://master:50070
spark.yarn.archive hdfs://master:9000/spark-yarn/spark-libs.jar
spark.executor.instances 2
spark.executor.extraJavaOptions -Dlog4j.configuration=file:/usr/local/BigDataPlatform/spark-2.3.0-bin-hadoop2.7/conf/log4j.properties
spark.driver.extraJavaOptions -Dlog4j.configuration=file:/usr/local/BigDataPlatform/spark-2.3.0-bin-hadoop2.7/conf/log4j.properties
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/spark-logs
spark.history.fs.logDirectory hdfs://master:9000/spark-logs // 실행 전에 해당 폴더는 생성해주어야한다.
spark.acls.enable false
[log4j.properties]
# 아래 부분 찾아서 다음과 같이 변경해줄 것
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
log4j.logger.org.apache.spark.repl.Main=INFO
[slaves]
datanode1
datanode2
- 기본 설정파일 이외에 추가적으로 “metrics.properties” 파일 생성
- metrics.properties.templete 설정 해제
- $SPARK_HOME/yarn/spark-<스파크버전>-yarn-shuffle.jar
-> 각 노드의 $HADOOP_HOME/share/hadoop/yarn/lib로 복사
4) 히스토리 서버 실행
./sbin/start-history-server.sh
- 정상적으로 실행되는지 확인을 위해 아래 URL에서 조회
http://master:18080
5) spark-libs.jar 파일 생성 및 HDFS 업로드
- spark에서 사용되는 jar 파일은 $SPARK_HOME/jars 안에 위치한다.
- 아래의 명령어를 사용하여 새로운 jar 파일을 생성하자.
jar cv0f spark-libs.jar -C $SPARK_HOME/jars/ .
- 실행이 완료가 되면 현재 작업한 디렉터리에 spark-libs.jar 파일이 생성되었을 것이다.
- HDFS 에 업로드 하기 위해 다음의 명령어를 실행시킨다.
hadoop fs -put ./spark-libs.jar [spark.yarn.archive 에 정의한 위치]
6) shuffle 서비스 실행
- 파티션 간의 물리적인 데이터 이동을 할 수 있도록 셔플링(Shuffling) 서비스를 실행한다.
$ ./sbin/start-shuffle-service.sh
$ ./bin/spark-shell --master yarn
[실행 결과]
[hadoop@master spark-2.1.0-bin-hadoop2.7]$ yarn application -list
18/04/13 16:23:57 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.33:8035
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1523603667406_0001 Spark shell SPARK hadoop default RUNNING UNDEFINED 10% http://masterIP:4040
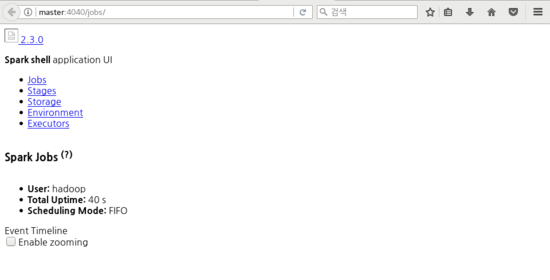
- 위의 설정대로 실행한 결과 WebUI (master:4040)은 정상적으로 열리지만 위의 사진과 같이 그래픽적인 요소는 보이지 않는다. 따라서 반드시 히스토리 서버를 같이 열어주고 spark-shell 종료시 생성된 Job을 확인할 수 있도록 한다.
7) Spark Dynamic Allocation 설정
- 설정 이유
- Spark Shell 이나 웹 기반의 애플리케이션인 경우와 같이 장시간 동작하면서 사람 혹은 외부 프로세스가 제공하는 이벤트가 있을 때만 작업을 처리하는 형태의 애플리케이션인 경우 명령을 대기하는 동안 자원적으로 손실이 발생할 수 있다.
- 작업을 수행하는 동안에만 동작시키는 것이 할당 측면에서 유리하며, 해당 작업이 대기하는 동안 해당 자원을 회수해서 자원이 부족한 다른 애플리케이션에 추가로 할당해주는 것이 더 합리적이다.
[yarn-site.xml]
...
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
....
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
...
<property>
<name>spark.yarn.shuffle.stopOnFailure</name>
<value>false</value>
</property>
[yarn-env.sh]
# For setting YARN specific HEAP sizes please use this
# Parameter and set appropriately
YARN_HEAPSIZE=2000
[spark-default.xml]
spark.dynamicAllocation.enabled true
spark.dynamicAllocation.schedulerBacklogTimeout 3s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 3s
spark.shuffle.service.enabled true // datanode(worker) 들은 false 로 설정해줘야함
- 설정 변경 후 아래 과정을 수행하면 된다.
- yarn 재실행 -> spark 재실행 -> standalone 모드를 제외하고 나머지 모드에 한해서 $SPARK_HOME/sbin/start-shuffle-service.sh 를 실행 -> Application 실행
[Scala Code]
val inputPath = "hdfs://<namenode_host:port>/sample/README.md"
val outputPath = "hdfs://<namenode_host:port>/sample/output"
sc.textFile(inputPath) flatMap { line => line.split( " ") map (word => (word,1L)) } reduceByKey (_ + _) saveAsTextFile (outputPath)
[결과]
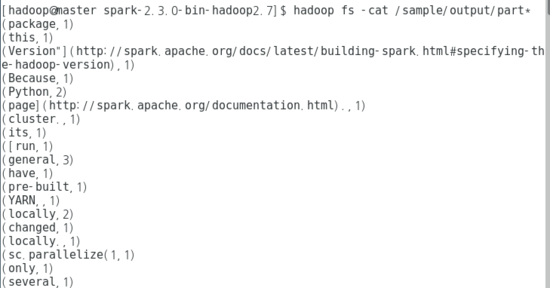
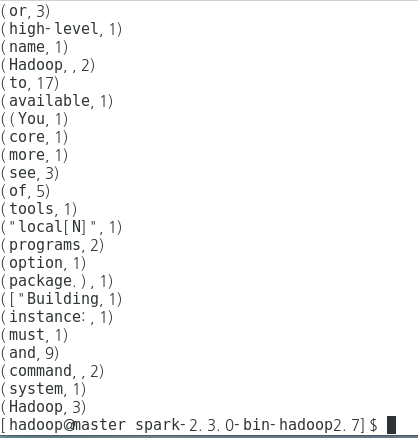
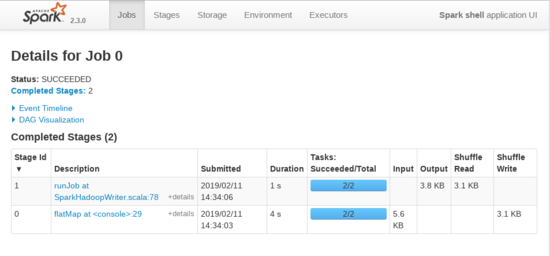
4. 예제 - WordCount
- 아래의 코드를 이용하여 spark 를 실행해보자
[WordCount.jar]
package Java.Spark;
import java.util.Arrays;
import java.util.Iterator;
import org.apache.commons.lang3.ArrayUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args)
{
if (ArrayUtils.getLength(args) != 3)
{
System.out.println("Usage: WordCount <master> <input> <output>");
return;
}
// SparkContext 생성
JavaSparkContext sc = getSparkContext("WordCount", args[0]);
try
{
JavaRDD<String> inputRDD = getInputRDD(sc, args[1]);
//JavaPairRDD<String, Integer> resultRDD = process(inputRDD);
JavaPairRDD<String, Integer> resultRDD = processWithLambda(inputRDD);
handleResult(resultRDD, args[2]);
}
catch(Exception e)
{
e.printStackTrace();
}
finally
{
sc.stop();
}
}
public static JavaSparkContext getSparkContext(String appName, String master)
{
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
return new JavaSparkContext(conf);
}
public static JavaRDD<String> getInputRDD(JavaSparkContext sc, String input)
{
return sc.textFile(input);
}
// Java 7
public static JavaPairRDD<String, Integer> process(JavaRDD<String> inputRDD)
{
JavaRDD<String> words = inputRDD.
flatMap(new FlatMapFunction<String, String>(){
public Iterator<String> call(String s) throws Exception
{
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> wcPair = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception
{
return new Tuple2(s, 1);
}
});
JavaPairRDD<String, Integer> result = wcPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
return result;
}
// Java 8
public static JavaPairRDD<String, Integer> processWithLambda(JavaRDD<String> inputRDD)
{
JavaRDD<String> words = inputRDD.flatMap((String s) -> Arrays.asList(s.split(" ")).iterator());
JavaPairRDD<String, Integer> wcPair = words.mapToPair((String w) -> new Tuple2(w, 1));
JavaPairRDD<String, Integer> result = wcPair.reduceByKey((Integer c1, Integer c2) -> c1 + c2);
return result;
}
public static void handleResult(JavaPairRDD<String, Integer> resultRDD, String output)
{
resultRDD.saveAsTextFile(output);
}
}
- 위의 코드는 Java 7 과 Java 8 모두 가지고 있으며 실행시에는 Java 8 Lambda 식을 활용한 코드가 사용된다.
- pom.xml 은 파일을 다운 받는 것을 추천한다.
- 실행은 HDFS 가 설치 되었다는 전제하에 다음의 명령어를 실행하며 만약 HDFS 가 설치 안되었다면 아래의 형식에 맞춰 사용하기 바란다.
[형식]
<spark-home-dir>/bin/spark-submit \
--class <package주소>.WordCount \
<jar 파일 경로>/<jar파일명>.jar \
local[*] \
<spark-home-dir>/README.md \
<spark-home-dir>/testresult
[실행 예시 - HDFS 설치 시]
./bin/spark-submit \
--class Java.Spark.WordCount \
hdfs://master:9000/jar/spark/WordCount.jar \
local[*] \
hdfs://master:9000/input/README.md \
hdfs://master:9000/output/WordCountResult
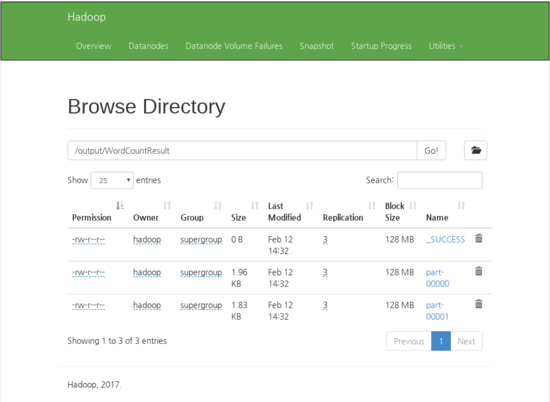
[실행 화면 - 확인]
[hadoop@master spark-2.3.0-bin-hadoop2.7]$ hadoop fs -cat /output/WordCountResult/part*
(package,1)
(this,1)
(Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1)
(Because,1)
(Python,2)
(page](http://spark.apache.org/documentation.html).,1)
(cluster.,1)
(its,1)
([run,1)
(general,3)
(have,1)
(pre-built,1)
(YARN,,1)
(locally,2)
(changed,1)
(locally.,1)
(sc.parallelize(1,1)
(only,1)
(several,1)
.....
댓글남기기