
[R-Machine Learning] 5. 의사결정나무

1. 결정 트리
- 트리 구조 모델을 만들며 연결된 논리 결정으로 구성되어 있다.
- 각 결정 노드의 속성에 따라 결정하는 가지들로 나누어 지며 모든 조합의 결과는 잎 노드로 끝난다.
- 분류 문제에서 많이 활용되는 모델이다.
2. C5.0 결정 트리 알고리즘
- ID3의 성능 향상을 위해 개발된 알고리즘인 C4.5의 상향 버전
- 알고리즘의 단일 스레드 방식에 대한 소스가 공개되었으며 R 과 같은 프로그램에서 사용하는 것이 가능하다.
1) 특징
|장점|단점| |—|—| |모든 문제에 적합한 분류기|다수의 레벨을 가진 속성으로 구분하는 경향| |결측치, 명목형 변수, 수치를 처리할 수 있는 자동성 높은 모델|과적합 혹은 과소적합이 쉽게 발생함| |가장 중요한 속성만 사용|일부 관계를 모델화 하는 데에 취약함| |수학적인 배경 없이 해석이 가능함|훈련 데이터의 사소한 변화에 민감하게 반응함| |다른 모델에 비해 높은 효율을 가짐|트리의 규모가 클 경우 이해하기 어려움|
2) 최적의 구분 선택 방법
- 데이터가 가지는 엔트로피를 이용한 순종성을 측정한다.
- 순수성(Purity) : 데이터가 몇개의 범주를 가지는가를 의미하며 적을 수록 순수성이 높다,
-
엔트로피(Entropy) : 물리에서의 용어가 아닌, 범주가 얼마나 섞여 있는 가를 의미하는 지표이다.
- 순수성을 고려해 어떤 속성으로 구분할 지를 결정하며 데이터가 하나 이상으로 분할되기 때문에 구분이 이뤄진 후에 복잡해진다.
- 총 엔트로피는 각 분할의 엔트로피에 가중치를 주어 계산 가능하다.
$ InfoGain(F) = Entropy(S_1) - Entropy(S_2) $ $ Entropy(S) = \sum_{i=1}^{n} { w_i Entropy(P_i) } $
- 속성을 선택하고 선택한 속성으로 분할할 경우 정보 이득이 높은 쪽으로 좀 더 균일한 그룹을 생성한다.
- 정보 이득 = 0 : 해당 속성으로 구분해 엔트로피를 줄일 수는 없다.
- 최대 정보 이득 = 구분 전 최대 정보 이득 : 엔트로피 = 0 임을 의미하며 완전히 균일한 그룹임을 의미한다.
3) 가지치기(Pruning)
- 트리의 규모가 너무 클 경우 많은 결정이 생겨 훈련 데이터에 과적합이 되는 결과를 발생시킨다.
- 이를 방지하기 위해, 보지 못한 데이터에 대해 좀 더 일반화를 하기 위해 트리의 크기를 줄이는 방법
(1) 사전 가지 치기
- 결정이 일정 수에 도달하거나 결정 트리가 적은 수의 예제를 포함할 경우 성장을 중지하는 방법
- 필요 없는 작업을 진행하지 않아도 되기 때문에 효율적일 수 있다.
- 트리가 감지하기 힘들지만 중요한 패턴을 놓칠 수도 있다.
(2) 사후 가지 치기
- 너무 크게 생성된 트리에 대해 트리의 규모를 줄이는 방법
- 적당한 크기로 줄이기 위해 각 노드의 오차 비율을 기반으로 가지치기 조건을 결정한다.
4) 실습 : 위험 은행 대출 확인
- 사용데이터 : 함브르크 대학의 한스 호프만이 기부한 독일의 신용회사에서 얻은 대출 기록
- 데이터 내의 문자열 데이터는 명사들이기 때문에 데이터 로드 시 stringAsFactor=False로 설정한다.
[R code]
credit <- read.csv("credit.csv", stringsAsFactors = F)
str(credit)
[실행결과]
'data.frame': 1000 obs. of 17 variables:
$ checking_balance : chr "< 0 DM" "1 - 200 DM" "unknown" "< 0 DM" ...
$ months_loan_duration: int 6 48 12 42 24 36 24 36 12 30 ...
$ credit_history : chr "critical" "good" "critical" "good" ...
$ purpose : chr "furniture/appliances" "furniture/appliances" "education" "furniture/appliances" ...
$ amount : int 1169 5951 2096 7882 4870 9055 2835 6948 3059 5234 ...
$ savings_balance : chr "unknown" "< 100 DM" "< 100 DM" "< 100 DM" ...
$ employment_duration : chr "> 7 years" "1 - 4 years" "4 - 7 years" "4 - 7 years" ...
$ percent_of_income : int 4 2 2 2 3 2 3 2 2 4 ...
$ years_at_residence : int 4 2 3 4 4 4 4 2 4 2 ...
$ age : int 67 22 49 45 53 35 53 35 61 28 ...
$ other_credit : chr "none" "none" "none" "none" ...
$ housing : chr "own" "own" "own" "other" ...
$ existing_loans_count: int 2 1 1 1 2 1 1 1 1 2 ...
$ job : chr "skilled" "skilled" "unskilled" "skilled" ...
$ dependents : int 1 1 2 2 2 2 1 1 1 1 ...
$ phone : chr "yes" "no" "no" "no" ...
$ default : chr "no" "yes" "no" "no" ...
[R code]
table(credit$checking_balance)
[실행결과]
< 0 DM > 200 DM 1 - 200 DM unknown
274 63 269 394
[R code]
table(credit$savings_balance)
[실행결과]
< 100 DM > 1000 DM 100 - 500 DM 500 - 1000 DM unknown
603 48 103 63 183
[R code]
summary(credit$months_loan_duration)
[실행결과]
Min. 1st Qu. Median Mean 3rd Qu. Max.
4.0 12.0 18.0 20.9 24.0 72.0
[R code]
summary(credit$amount)
Min. 1st Qu. Median Mean 3rd Qu. Max.
250 1366 2320 3271 3972 18424
[R code]
table(credit$default)
[실행결과]
no yes
700 300
[R code]
install.packages("C50")
library(C50)
set.seed(12345)
credit_rand <- credit[order(runif(1000)), ]
creditTrain <- credit_rand[1:900,]
creditTest <- credit_rand[901:1000]
creditModel <- C5.0(creditTrain[,-17], as.factor(creditTrain$default))
creditModel
[실행 결과]
Call:
C5.0.default(x = creditTrain[, -17], y = as.factor(creditTrain$default))
Classification Tree
Number of samples: 900
Number of predictors: 16
Tree size: 67
Non-standard options: attempt to group attributes
[R code]
summary(creditModel)
[실행 결과]
Call:
C5.0.default(x = creditTrain[, -17], y = as.factor(creditTrain$default))
C5.0 [Release 2.07 GPL Edition] Sat Apr 28 21:02:11 2018
-------------------------------
Class specified by attribute `outcome'
Read 900 cases (17 attributes) from undefined.data
Decision tree:
checking_balance = unknown: no (358/44)
checking_balance in {< 0 DM,1 - 200 DM,> 200 DM}:
:...credit_history in {perfect,very good}:
:...dependents > 1: yes (10/1)
: dependents <= 1:
: :...savings_balance = < 100 DM: yes (39/11)
: savings_balance in {500 - 1000 DM,unknown,> 1000 DM}: no (8/1)
: savings_balance = 100 - 500 DM:
: :...checking_balance = < 0 DM: no (1)
: checking_balance in {1 - 200 DM,> 200 DM}: yes (5/1)
credit_history in {critical,good,poor}:
:...months_loan_duration <= 11: no (87/14)
months_loan_duration > 11:
:...savings_balance = > 1000 DM: no (13)
savings_balance in {< 100 DM,100 - 500 DM,500 - 1000 DM,unknown}:
:...checking_balance = > 200 DM:
:...dependents > 1: yes (3)
: dependents <= 1:
: :...credit_history in {good,poor}: no (23/3)
: credit_history = critical:
: :...amount <= 2337: yes (3)
: amount > 2337: no (6)
checking_balance = 1 - 200 DM:
:...savings_balance = unknown: no (34/6)
: savings_balance in {< 100 DM,100 - 500 DM,500 - 1000 DM}:
: :...months_loan_duration > 45: yes (11/1)
: months_loan_duration <= 45:
: :...other_credit = store:
: :...age <= 35: yes (4)
: : age > 35: no (2)
: other_credit = none:
: :...job = unemployed: no (1)
: : job = unskilled: [S1]
: : job = management:
: : :...amount <= 7511: no (10/3)
: : : amount > 7511: yes (7)
: : job = skilled:
: : :...dependents <= 1: no (55/15)
: : dependents > 1:
: : :...age <= 34: no (3)
: : age > 34: yes (4)
: other_credit = bank:
: :...years_at_residence <= 1: no (3)
: years_at_residence > 1:
: :...existing_loans_count <= 1: yes (5)
: existing_loans_count > 1:
: :...percent_of_income <= 2: no (4/1)
: percent_of_income > 2: yes (3)
checking_balance = < 0 DM:
:...job = management: no (26/6)
job = unemployed: yes (4/1)
job = unskilled:
:...employment_duration in {4 - 7 years,
: : unemployed}: no (4)
: employment_duration = > 7 years:
: :...other_credit in {none,bank}: no (5/1)
: : other_credit = store: yes (2)
: employment_duration = < 1 year:
: :...other_credit in {none,store}: yes (11/2)
: : other_credit = bank: no (1)
: employment_duration = 1 - 4 years:
: :...age <= 39: no (14/3)
: age > 39:
: :...credit_history in {critical,good}: yes (3)
: credit_history = poor: no (1)
job = skilled:
:...credit_history = poor:
:...savings_balance in {< 100 DM,100 - 500 DM,
: : 500 - 1000 DM}: yes (8)
: savings_balance = unknown: no (1)
credit_history = critical:
:...other_credit = store: no (0)
: other_credit = bank: yes (4)
: other_credit = none:
: :...savings_balance in {100 - 500 DM,
: : unknown}: no (1)
: savings_balance = 500 - 1000 DM: yes (1)
: savings_balance = < 100 DM:
: :...months_loan_duration <= 13:
: :...percent_of_income <= 3: yes (3)
: : percent_of_income > 3: no (3/1)
: months_loan_duration > 13:
: :...amount <= 5293: no (10/1)
: amount > 5293: yes (2)
credit_history = good:
:...existing_loans_count > 1: yes (5)
existing_loans_count <= 1:
:...other_credit = store: no (2)
other_credit = bank:
:...percent_of_income <= 2: yes (2)
: percent_of_income > 2: no (6/1)
other_credit = none: [S2]
SubTree [S1]
employment_duration in {> 7 years,4 - 7 years,unemployed}: no (8)
employment_duration in {1 - 4 years,< 1 year}: yes (11/3)
SubTree [S2]
savings_balance = 100 - 500 DM: yes (3)
savings_balance = 500 - 1000 DM: no (1)
savings_balance = unknown:
:...phone = no: yes (9/1)
: phone = yes: no (3/1)
savings_balance = < 100 DM:
:...percent_of_income <= 1: no (4)
percent_of_income > 1:
:...phone = yes: yes (10/1)
phone = no:
:...purpose in {education,business,car0,renovations}: yes (3)
purpose = car:
:...percent_of_income <= 3: no (2)
: percent_of_income > 3: yes (6/1)
purpose = furniture/appliances:
:...years_at_residence <= 1: no (4)
years_at_residence > 1:
:...housing = rent: yes (2)
housing = other: no (1)
housing = own:
:...amount <= 1778: no (3)
amount > 1778:
:...years_at_residence <= 3: yes (6)
years_at_residence > 3: no (3/1)
Evaluation on training data (900 cases):
Decision Tree
----------------
Size Errors
66 125(13.9%) <<
(a) (b) <-classified as
---- ----
609 23 (a): class no
102 166 (b): class yes
Attribute usage:
100.00% checking_balance
60.22% credit_history
53.22% months_loan_duration
49.44% savings_balance
30.89% job
25.89% other_credit
17.78% dependents
9.67% existing_loans_count
7.22% percent_of_income
6.67% employment_duration
5.78% phone
5.56% amount
3.78% years_at_residence
3.44% age
3.33% purpose
1.67% housing
Time: 0.0 secs
[R code]
install.packages("gmodels")
library(gmodels)
creditPred <- predict(creditModel, newdata = creditTest)
creditReal <- creditTest$default
CrossTable(creditReal, creditPred, prop.chisq = F, prop.c = F, prop.r = F,
dnn = c("Actual Default", "Pred Default"))
[실행결과]
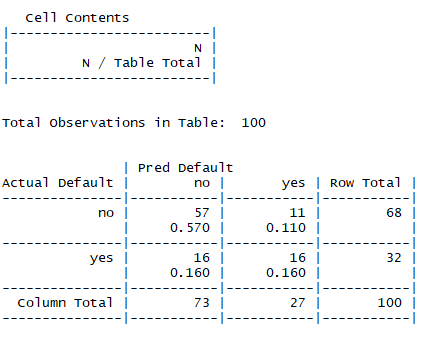
[R code]
creditModelBoost10 <- C5.0(creditTrain[,-17], as.factor(creditTest$default), trials = 10)
creditModelBoost10
[실행 결과]
Call:
C5.0.default(x = creditTrain[, -17], y =
as.factor(creditTest$default), trials = 10)
Classification Tree
Number of samples: 900
Number of predictors: 16
Number of boosting iterations: 10
Average tree size: 61.6
Non-standard options: attempt to group attributes
[R code]
summary(creditModelBoost10)
[실행결과]
...
----- Trial 9: -----
Decision tree:
purpose in {education,car0}: no (68.3/28.4)
purpose = renovations:
:...months_loan_duration <= 10: no (3)
: months_loan_duration > 10: yes (18/5.2)
purpose = business:
:...dependents > 1: no (7.5)
: dependents <= 1:
: :...amount <= 3711: no (38/14.1)
: amount > 3711: yes (37.7/16.4)
purpose = car:
:...savings_balance in {unknown,> 1000 DM}: no (72/29.6)
: savings_balance = 500 - 1000 DM:
: :...months_loan_duration <= 13: yes (8.6/0.5)
: : months_loan_duration > 13: no (8.4/1.4)
: savings_balance = 100 - 500 DM:
: :...housing = rent: no (5.3/2.1)
: : housing = other: yes (3.1)
: : housing = own:
: : :...dependents > 1: yes (7.1/1.4)
: : dependents <= 1:
: : :...percent_of_income <= 3: no (11.2/3.2)
: : percent_of_income > 3: yes (12.7/3.6)
: savings_balance = < 100 DM:
: :...other_credit = store: no (2.8)
: other_credit in {none,bank}:
: :...job = unemployed: no (3/0.6)
: job = management:
: :...years_at_residence <= 1: no (3.4)
: : years_at_residence > 1:
: : :...age <= 40: yes (31.5/8.7)
: : age > 40: no (10.3/2.1)
: job = unskilled:
: :...other_credit = bank: no (3.8)
: : other_credit = none:
: : :...phone = yes: no (6.8/2.1)
: : phone = no:
: : :...housing = rent: yes (3.6/0.4)
: : housing = other: no (0.5)
: : housing = own:
: : :...months_loan_duration <= 16: yes (24.4/6.2)
: : months_loan_duration > 16: no (3.1)
: job = skilled:
: :...credit_history in {perfect,very good}: yes (4.7)
: credit_history in {critical,good,poor}:
: :...percent_of_income <= 1: yes (9.7/2.5)
: percent_of_income > 1:
: :...dependents > 1: no (6.1)
: dependents <= 1:
: :...months_loan_duration <= 18: no (24.9/3.7)
: months_loan_duration > 18: yes (32.2/13.2)
purpose = furniture/appliances:
:...job in {unskilled,unemployed}: no (83/32.9)
job = management:
:...dependents <= 1: no (26.5/10.1)
: dependents > 1: yes (3.8/0.9)
job = skilled:
:...employment_duration = < 1 year: no (53.9/19.6)
employment_duration = unemployed: yes (5.6/2.4)
employment_duration = 4 - 7 years:
:...housing = rent: yes (10.1/3.7)
: housing = other: no (0.5)
: housing = own:
: :...dependents <= 1: no (33.6/11.2)
: dependents > 1: yes (2.2/0.2)
employment_duration = > 7 years:
:...credit_history = poor: no (1.7)
: credit_history in {perfect,very good}: yes (3.2/0.7)
: credit_history = good:
: :...age <= 38: yes (22.5/6.7)
: : age > 38: no (15.1/1.8)
: credit_history = critical:
: :...savings_balance in {100 - 500 DM,> 1000 DM}: yes (5.6/0.4)
: savings_balance in {500 - 1000 DM,unknown}: no (15/6.2)
: savings_balance = < 100 DM:
: :...existing_loans_count <= 2: no (12.9/2.9)
: existing_loans_count > 2: yes (3.5)
employment_duration = 1 - 4 years:
:...dependents > 1: yes (7.1/1.7)
dependents <= 1:
:...housing = rent: no (12.2/3.7)
housing = other: yes (8.5/2.8)
housing = own:
:...existing_loans_count > 1: no (23.7/7.7)
existing_loans_count <= 1:
:...other_credit in {store,bank}: no (4.2)
other_credit = none:
:...percent_of_income <= 3: no (32.8/9.7)
percent_of_income > 3: yes (24.9/8.6)
Evaluation on training data (900 cases):
Trial Decision Tree
----- ----------------
Size Errors
0 82 170(18.9%)
1 29 261(29.0%)
2 72 252(28.0%)
3 56 245(27.2%)
4 77 240(26.7%)
5 45 266(29.6%)
6 82 218(24.2%)
7 62 274(30.4%)
8 57 252(28.0%)
9 54 252(28.0%)
boost 56( 6.2%) <<
(a) (b) <-classified as
---- ----
608 4 (a): class no
52 236 (b): class yes
Attribute usage:
100.00% credit_history
100.00% purpose
100.00% percent_of_income
100.00% years_at_residence
99.89% other_credit
96.89% savings_balance
96.78% housing
95.33% dependents
93.67% existing_loans_count
90.78% checking_balance
85.67% employment_duration
83.56% job
83.11% months_loan_duration
66.11% phone
61.44% age
45.00% amount
Time: 0.1 secs
[R code]
creditBoostPred10 <- predict(creditModelBoost10, creditTest)
CrossTable(creditTest$default, creditBoostPred10,
prop.chisq = FALSE, prop.c = FALSE, prop.r = FALSE,
dnn = c('actual default', 'predicted default'))
[실행결과]
Cell Contents
|-------------------------|
| N |
| N / Table Total |
|-------------------------|
Total Observations in Table: 100
| predicted default
actual default | no | yes | Row Total |
-----------|--------|---------|---------|
no | 58 | 10 | 68 |
| 0.580 | 0.100| |
-----------|--------|---------|---------|
yes | 28 | 4 | 32 |
| 0.280 | 0.040 | |
-----------|---------|--------|--------|
Column Total | 86 | 14 | 100 |
------------|---------|--------|--------|
[R code]
errorCost <- matrix(c(0, 1, 4, 0), nrow = 2)
errorCost
[실행결과]
[,1] [,2]
[1,] 0 4
[2,] 1 0
[R code]
creditCostPred <- predict(creditCost, creditTest)
CrossTable(creditTest$default, creditCostPred,
prop.chisq = FALSE, prop.c = FALSE, prop.r=FALSE,
dnn = c('actual default', 'predicted default'))
[실행결과]
Cell Contents
|-------------------------|
| N |
| N / Table Total |
|-------------------------|
Total Observations in Table: 100
| predicted default
actual default | no | yes | Row Total |
-----------|--------|---------|---------|
no | 42 | 26 | 68 |
| 0.420 | 0.260 | |
-----------|---------|---------|--------|
yes | 6 | 26 | 32 |
| 0.060 | 0.260 | |
-----------|---------|---------|--------|
Column Total | 48 | 52 | 100 |
-----------|---------|---------|--------|
5) 분류 규칙 이해하기
- 분류 규칙은 라벨 없는 예제에서 범주를 지정하는 논리적 유형 if-else 식으로 지식을 표현한다.
- 선형 사건과 결과 면에서 분류 구칙은 명시된다.
- 규칙 학습기는 결정 트리 학습기와 유사한 방법으로 사용된다.
- 기계적 장치에서 하드웨어 고장을 만드는 상태 확인하기
- 고객 대응 분석에 대한 그룹의 특징 정의를 묘사하기
- 주식시장에서 주식의 큰 폭 상향이나 하향 전 상태 찾기
- 하향식 방식으로 적용하는 트리와 달리 규칙은 독립형이다.
- 규칙 학습기의 결과는 같은 데이터로 만들어진 결정트리보다 직접적이며 쉽게 이해할 수 있다.
- 규칙 학습기는 속성이 매우 중요하거나 전체적으로 명목형 문제에 적용한다.
(1) 구분해 정복하기
- 분류 규칙 학습기 알고리즘은 휴리스틱 알고리즘을 사용한다.
-
위의 과정에서 훈련 데이터에서 예제 부분집합을 다루는 규칙을 찾는 것과 연관되어있다.
- 규칙이 추가되면 추가적인 데이터의 부분집합은 남은 예제가 없고 전체 데이터를 다룰 때까지 나눠진다.
- 데이터를 먼저 들어오면 먼저 처리하는 원칙으로 사용하기 때문에 Greedy 학습기로도 알려져 있다.
- 규칙은 데이터 분할을 다루기 때문에 위의 알고리즘은 커버링 알고리즘으로 알려져있으며, 그 때문에 사용되는 규칙을 커버링 규칙이라고 한다.
(2) One Rule 알고리즘
- 단순히 하나의 규칙을 선택해 Zero Rule 알고리즘을 개선하기 위해서 사용된다.
- 단순해보이기는 하나 예상외로 좋은 성능을 낼 수 있다는 장점이 있다.
- 쉽게 이해할 수 있고 사람이 읽을 수 있는 최상의 규칙 하나를 생성한다.
-
조금 복잡한 알고리즘에 대해 벤치마크로 실행할 수 있다.
- 하지만 하나의 속성만을 사용하기 때문에 너무 단조로워 보일 수 있다는 단점이 있다.
(3) RIPPER 알고리즘
-
모든 데이터셋의 인스턴스를 구별하기 전에 가지를 자르고 매우 복잡한 규칙으로 커지는 기법에 사전 가지 치기와 사후 가지치기의 조합을 사용한다.
- 등장배경
- 초기 규칙 학습 알고리즘의 문제점
- 알고리즘의 속도가 느리고 증가하는 빅데이터의 수를 효과적으로 처리하지 못함
- 노이즈 데이터로 인해 부정확한 경향이 있음
- 한계점
- 규칙 학습기의 성능에 도움을 줬지만 결정 트리 보다 나은 성능을 발휘하진 못한다.
-
규칙 학습 알고리즘의 일부 반복과 관련해 RIPPER 알고리즘은 규칙 학습에 대해 효과적인 휴리스틱 부분 작업으로 구성됐다. 일반적으로 아래와 같이 3단계로 구성된다.
- 성장
- 나누기 위한 속성이 없거나 데이터의 부분집합으로 분류하기 전까지는 규칙에 조건을 추가하기 위해 나누고 정복하기 기법을 사용한다.
- 가지치기
- 결정 트리와 유사하게 정보 이득 기준을 다음에 나눌 속성을 확인하기 위해 사용하며 증가하는 규칙의 특수성이 엔트로피를 줄이지 못할 때 해당 규칙의 사용을 멈춘다.
- 최적화
- 휴리스틱의 다양성을 사용해 전체 규칙이 최적화되는 멈춤 기준에 도달하기 전까지 성장과 가지치기 과정을 반복한다.
6) 독버섯 식별하기
-
해당 데이터 셋은 Audubon Society Field Guide to North American Mashrooms 에서 제공한 데이터로 총 8124의 버섯 표본과 23개의 주름 있는 버섯의 속성으로 돼 있다.
(1) 데이터 준비 및 탐구
- 각 속성변수의 값은 명목형 변수들이며 문자열 형식이기 때문에 데이터 로드 시 stringAsFactor 옵션 값을 TRUE로 설정해준다.
[R code]
data <- read.csv("mushrooms.csv",stringsAsFactors = TRUE)
- 데이터 로드 이 후 정보를 확인하기 위해 다음 2가지의 작업을 수행한다.
[R code]
colnames(data) # 변수명 확인
str(data) # 변수형 확인
- 확인 해본 결과 다른 속성변수들과 달리 veil_type의 변수만 1개의 레벨을 갖는 것을 확인할 수 있다.
- 이는 데이터의 모든 예가 partial로 잘못 코드화 된 것으로 판단되며, 예측에 유용한 정보를 제공하지 못하기 때문에 제거해준다.
[R code]
data$veil_type <- NULL
- 마지막으로 버섯 종류에서 범주 변수의 분포를 확인한다.
[R code]
table(data$type) # 식용버섯 : 독버섯 = 52:48
[실행결과]
edible poisonous
4208 3916
- 위의 탐색을 토대로 실험의 목적을 위해 버섯 데이터 전체표본은 모든 야생버섯이라고 가정한다.
- 이는 테스트 목적을 위해 룬련 데이터에서 벅어나 일부 표본을 가질 필요가 없음을 뜻하기 때문에 중요한 가정이라고 할 수 있다.
(2) 모델링
- 사용 모델: RWeka 의 OneR()
- 구성
OneR(class, predictors, data = mydata)- class : 예측하고자 하는 mydata의 열
- predictors : 예측에 사용하기 위해 mydata 데이터프레임의 속성을 명시
- data : class 와 predictors를 찾을 수 있는 데이터프레임
[R code]
install.packages("RWeka")
library(RWeka)
mushroom_1R <- OneR(type ~ ., data = data)
mushroom_1R
[실행결과]
odor:
almond -> edible
anise -> edible
creosote -> poisonous
fishy -> poisonous
foul -> poisonous
musty -> poisonous
none -> edible
pungent -> poisonous
spicy -> poisonous
(8004/8124 instances correct)
- 결과해석 예시
독버섯의 경우 : creosote, fishy, foul, musty, pungent, spicy 의 성향이 강하다는 특징을 가짐
(3) 모델 성능 평가
[R code]
summary(mushroom_1R)
[실행결과]
=== Summary ===
Correctly Classified Instances 8004 98.5229 %
Incorrectly Classified Instances 120 1.4771 %
Kappa statistic 0.9704
Mean absolute error 0.0148
Root mean squared error 0.1215
Relative absolute error 2.958 %
Root relative squared error 24.323 %
Total Number of Instances 8124
=== Confusion Matrix ===
a b <-- classified as
4208 0 | a = edible
120 3796 | b = poisonous
- 정확도는 약 98.52%, 오차률은 약 1.48% 정도의 모델이다.
- 전체 데이터 셋에 대해 120 개 정도를 오분류했다.
(4) 모델 성능 개선
- 모델링 방식을 변화하는 방식으로 개선
- RIPPER 알고리즘 사용
[R code]
mushroom_jRip <- JRip(type ~ ., data = data)
mushroom_jRip
[실행 결과]
JRIP rules:
===========
(odor = foul) => type=poisonous (2160.0/0.0)
(gill_size = narrow) and (gill_color = buff) => type=poisonous (1152.0/0.0)
(gill_size = narrow) and (odor = pungent) => type=poisonous (256.0/0.0)
(odor = creosote) => type=poisonous (192.0/0.0)
(spore_print_color = green) => type=poisonous (72.0/0.0)
(stalk_surface_below_ring = scaly) and (stalk_surface_above_ring = silky) => type=poisonous (68.0/0.0)
(habitat = leaves) and (gill_attachment = free) and (population = clustered) => type=poisonous (16.0/0.0)
=> type=edible (4208.0/0.0)
Number of Rules : 8
- 총 8개의 규칙을 학습함
- 제일 마지막 줄에 위치한 내용( => type=edible (4208.0/0.0) ) 은 해당 클래스로 분류된 인스턴스의 개수를 의미한다.
[R code]
summary(mushroom_jRip)
[실행 결과]
=== Summary ===
Correctly Classified Instances 8124 100 %
Incorrectly Classified Instances 0 0 %
Kappa statistic 1
Mean absolute error 0
Root mean squared error 0
Relative absolute error 0 %
Root relative squared error 0 %
Total Number of Instances 8124
=== Confusion Matrix ===
a b <-- classified as
4208 0 | a = edible
0 3916 | b = poisonous
- 전체 데이터 셋을 정확하게 100% 분류했다는 것을 확인할 수 있다.
댓글남기기