
[R-Machine Learning] 4. 나이브베이즈 분류

1. 나이브 베이즈의 이해
- 18세기의 수학자 토마스 베이즈의 작업에서 유래됨
- 속성값을 바탕으로 각 범주의 관찰된 확률을 계산하기 위해 사용하며 분류되지 않은 데이터를 분류기가 분류할 때 새로운 속성에 대한 가장 유사한 범주를 예측하기 위해 관찰된 확률을 사용한다.
- 결과의 확률을 추정하기 위해 많은 속성을 고려해야하는 문제에 가장 적합하다.
1) 기본 개념
- 베이즈 확률 이론: 유사한 증거를 기반으로 한 사건의 유사성을 추정한다.
- 사건: 일어날 수 있는 결과를 의미하며 확률적으로 0~100% 사이의 수치를 가진다.
- 시도: 사건이 일어날 한 번의 기회를 의미한다.
-
확률: 사건이 일어난 시도의 수를 총 사건의 수로 나눠 관찰된 데이터로부터 추정한 수치이며, 총 확률은 반드시 100%가 되야한다.
-
결합 확률
같은 시도에 대해 일부 사건이 다른 사건과 함께 일어났다면 예측에 대해 같이 사용할 수 있는 확률
두 사건의 조건부 확률에 달려있거나 한 사건의 확률이 얼마나 다른 사건에 연루되어있는가
두 사건이 서로 연관되지 않은 경우(독립 사건인 경우) - 조건부 확률
독립적 사건 간의 관계는 베이즈 이론을 사용해서 다음과 같이 나타낼 수 있다.
사건 B가 일어날 때 사건 A가 발생할 확률을 의미한다. $P(A \vert B) = \frac {P(B \vert A) P(B)}{P(B)} = \frac {P(A \cap B)}{P(B)}$
2) 나이브 베이즈 알고리즘
- 분류를 위해 사용되는 애플리케이션
- 범주형 데이터에 적용가능함
| 장점 | 단점 |
|---|---|
| 단순하고 빠르며 효과적이다 | 모든 속성은 동등하게 중요하고 독립적이라는 결함 가정에 의존함 |
| 노이즈와 결측치가 있어도 잘 수행한다. | 수치 속성으로 구성된 많은 데이터 셋에 대해 이상적이지 않다. |
| 상대적으로 적은 양의 데이터여도 수행 가능함 | 추정된 확률은 예측 범주보다 덜 신뢰적이다. |
| 예측에 대한 추정확률을 얻기 쉽다. |
- 결함 가정이 있음에도 나이브 베이즈가 좋은 성능을 내는 이유?
- 여러 상황에서도 알고리즘의 융통성 및 정확성이 있기 때문에 가능하다.
- 결함 가정에도 불구하고 나이브베이즈가 좋은 성능을 내는 이유는 추측(speculation)과 관련있다. 예측된 범주가 참이기만하면 확률의 주의깊은 추정은 중요하지 않다.
- 나이브 베이즈의 경우 사건들이 같은 범주에 있다면 사건들은 독립적이라는 범주 조건부 독립을 가정한다.
2) 라플라스 추정기
- 각 범주에서 발생 확률을 0이 되지 않게 하기 위해 빈도표의 각 값에 작은 수를 추가한다.
- 일반적으로는 적어도 각 범주에 한 번 속한 것처럼 1로 설정된다.
3) 나이브 베이즈와 수치 속성 사용
- 학습 데이터에 대해도표를 사용하기 때문에 각 속성은 매트릭스로 구성된 범주와 속성 값의 혼합을 생성하기 위해 범주형이여야한다.
- 수치형 데이터의 경우는 구간으로 범주를 나누는 이산화(discretize)를 진행한다.
-
데이터 분산에서 특정 점에서 자르거나 자연적인 범주형을 만들기 위해 일정 간격의 구간을 생성해 해당 범주에 속하면 그 때의 클래스를 값으로 부여한다.
- 대량의 훈련 데이터일 경우 이상적이며 나이브 베이즈와 작동할 때 일반적인 조건이다.
2. 예제 : 나이브 베이즈를 이용한 휴대폰 스팸 제거
- 사용 데이터: http://www.dt.fee.unicamp.br/~tiago/smsspamcollection/ 의 SMS 스팸 모음 데이터를 사용
1) 데이터 준비
[R code]
sms_raw <- read.csv("sms_spam.csv", stringsAsFactors = F)
str(sms_raw)
[실행결과]
'data.frame': 5559 obs. of 2 variables:
$ type: chr "ham" "ham" "ham" "spam" ...
$ text: chr "Hope you are having a good week. Just checking in" "K..give back my thanks." "Am also doing in cbe only. But have to pay." "complimentary 4 STAR Ibiza Holiday or 짙10,000 cash needs your URGENT collection. 09066364349 NOW from Landline not to lose out ...
- 위의 데이터 셋의 1072행에는 데이터가 잘못 저장되어있으며 이를 수정하기 위해 다음 코드를 우선 실행해준다.
[R code]
sms_raw[1072,2] <- sms_raw[1072,1]
sms_raw[1072,1] <- ("ham")
- 구조를 확인하면 알 수 있다시피 문자벡터로 구성되어있다.
- 추가적으로 type 변수는 현재 문자벡터이며 나이브베이즈를 이용하기 위해 명목형 변수를 변환시켜준다.
[R code]
sms_raw$type <- factor(sms_raw$type)
head(sms_raw$type)
[실행결과]
[1] ham ham ham spam spam ham
[R code]
table(sms_raw$type)
[실행 결과]
ham spam
4812 747
2) 텍스트 마이닝을 이용한 데이터 전처리
[R code]
install.packages("tm")
library(tm)
sms_corpus <- Corpus(VectorSource(sms_raw$text))
print(sms_corpus)
[실행결과]
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 5559
- corpus를 확인하기 위해 다음의 과정을 수행한다.
[R code]
inspect(sms_corpus[1:3])
[실행결과]
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 3
[1] Hope you are having a good week. Just checking in
[2] K..give back my thanks.
[3] Am also doing in cbe only. But have to pay.
- 확인한 corpus를 분석에 적용하기 쉽도록 변환함수를 사용한다.
[R code]
corpus_clean <- tm_map(sms_corpus, content_transformer(tolower))
corpus_clean <- tm_map(corpus_clean, removeNumbers)
- 또한 내용에 포함된 불용어(to, and, but. …)를 제거한다.
[R code]
corpus_clean <- tm_map(corpus_clean, removeWords, stopwords())
corpus_clean <- tm_map(corpus_clean, removePunctuation)
inspect(corpus_clean[1:3])
[실행결과]
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 3
[1] hope good week just checking
[2] kgive back thanks
[3] also cbe pay
- stopwords() 를 사용함으로써 마침표 및 기타 불용어들이 제거된 것을 확인할 수 있다. 마지막으로 정리된 corpus를 희소 매트릭스로 변경시켜준다.
[R code]
sms_dtn <- DocumentTermMatrix(corpus_clean)
3) 데이터 분할
- 모델 훈련을 위한 훈련용 데이터와 검증을 위해 사용할 검증 데이터로 분할 한다.
[R code]
sms_raw_train <- sms_raw[1:4169, ]
sms_raw_test <- sms_raw[4170:5559, ]
sms_dtn_train <- sms_dtn[1:4169, ]
sms_dtn_test <- sms_dtn[4170:5559, ]
sms_corpus_train <- corpus_clean[1:4169]
sms_corpus_test <- corpus_clean[4170:5559]
- 분할한 데이터 내의 ham 과 spam의 비율을 확인한다.
[R code]
prop.table(table(sms_raw_train$type))
[실행결과]
ham spam
0.8647158 0.1352842
4) 텍스트 데이터 시각화: WordCloud
- 텍스트 데이터의 단어 빈도를 시각적으로 묘사하는 방법
- 빈도 수가 높은 단어일수록 글자의 크기가 크게 표현된다.
[R code]
wordcloud(sms_corpus_train, min.freq = 40, random.order = F)
[결과]

- 다음으로 훈련 데이터의 type을 이용해 spam과 ham 으로 부분 집합을 구성한다.
[R code]
spam <- subset(sms_raw_train, type == "spam")
ham <- subset(sms_raw_train, type == "ham")
wordcloud(spam$text, max.words = 40, scale=c(3, 0.5), main = "Spam Data WordCloud")
wordcloud(ham$text, max.words = 40, scale=c(3, 0.5), main = "Ham Data WordCloud")
[결과]

5) 단어 빈도에 대한 지표 속성 생성
- 나이브 베이즈가 학습하기 쉬운 데이터 구조로 변환한다,
[R code]
sms_dict <- findFreqTerms(sms_dtn_train, 5)
sms_train <- DocumentTermMatrix(sms_corpus_train, list(dictionary = sms_dict))
sms_test <- DocumentTermMatrix(sms_corpus_test, list(dictionary = sms_dict))
- 나이브 베이즈 분류기는 일반적으로 분류적 특성을 가진 데이터에 적용해 훈련 한다.
- 희소 매트릭스의 칸은 메세지에서 나타난 단어의 빈도를 나타나기 때문에 문제가 된다. 따라서 희소 매트릭스를 단어가 나타나는지에 판단해 Yes, No를 표시하는 팩터 변수로 전환한다.
[R code]
convert_counts <- function(x){
x <- ifelse(x > 0, 1, 0)
x <- factor(x, levels=c(0, 1), labels = c("No", "Yes"))
return(x)
}
sms_train <- apply(sms_train, MARGIN = 2, convert_counts)
sms_test <- apply(sms_test, MARGIN = 2, convert_counts)
3. 나이브 베이즈 분류기
- 나이브 베이즈 모델은 e1071 패키지에 존재한다.
-
함수 구성
naiveBayes(train , test , laplace = 0 ) - 학습은 predict() 함수를 사용하며 아래와 같이 학습한다.
[R code]
install.packages("e1071")
library(e1071)
sms_classifier <- naiveBayes(sms_train, sms_raw_train$type)
sms_classifier$apriori
sms_test_pred <- predict(sms_classifier, sms_test)
4. 모델 성능 평가: 교차표
- 예측한 값과 실제 값을 비교하기 위해 gmodels 패키지의 CrossTable() 함수를 이용한다. ```R [R code]
library(gmodels)
CrossTable(sms_test_pred, sms_raw_test$type, prop.chisq = F, prop.t = F, dnn = c(“predicted”, “actual”))
[결과]<br>
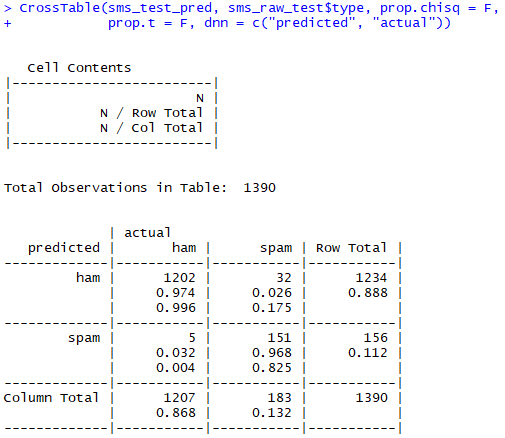
- 총 1207개의 정상 메세지 중 5개(3.2%) 를 오분류 했다. 반면 스팸 메세지의 경우 183개 중 32개 (2.6%)를 오분류 했다.
# 5. 모델 성능 평가: 라플라스 측정기
- 모델 훈련 시 라플라스 측정기에 대한 값을 설정하지 않았으므로 laplace 값을 1 로 설정 후 다시 학습 시킨다.
- 1로 설정한 이유는 다음과 같다.
- 스팸 메세지 혹은 정상 메세지 중 한쪽에서 나오지 않은 단어는 분류 과정에서 불필요하다.
- 단어 '벨소리' 는 훈련 데이터에 단 한 번 나오는 정보를 이용해서 해당 단어가 있는 모든 메세지는 스팸으로 분류한다.
```R
[R code]
sms_classifier2 <- naiveBayes(sms_train, sms_raw_train$type, laplace = 1)
sms_test_pred2 <- predict(sms_classifier2, sms_test)
CrossTable(sms_test_pred2, sms_raw_test$type, prop.chisq = F, prop.t = F, prop.r = F, dnn = c("predicted", "actual"))
[결과]
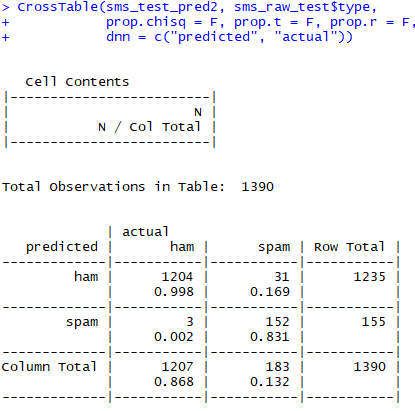
- 결과적으로 정상 메세지 중에서는 3개를, 스팸 메세지에서는 31개를 오분류 했다.
댓글남기기