
[R-Machine Learning] 2. 데이터 관리의 이해

1. R의 데이터 구조
1) 벡터
- 원소라 불리는 값의 순서 있는 집합으로 저장된다.
- 원소의 개수를 상관하지 않으나 모든 원소는 같은 타입이어야한다.
- 결합 함수 c() 를 사용해서 간단하게 벡터를 만들 수 있다.
- R에서의 벡터는 순서화를 상속받았기 때문에 각 값을 집합에서 1부터 시작하는 아이템의 숫자를 세어 접근할 수 있으며 벡터의 이름뒤에 인덱스를 사용할 수 있다.
2) 팩터
- 명목형 데이터를 저장하는 문자형식의 특수 벡터라고 할 수 있다.
- 펙터가 character 형 벡터보다 일반적으로 더 효율적이다.
- 범주 라벨을 단지 한 번만 저장한다.
- 팩터의 레벨을 정의할 때는 Levels 옵션을 사용해서 정의한다.
3) 리스트
- 값의 순서가 있는 집합을 저장하는데 사용한다.
- 벡터와의 차이점은 모아진 값의 타입이 달라도 된다.
- 때문에 데이터의 입력과 출력의 다양한 타입을 저장하는 데 리스트를 자주 사용한다.
- list() 를 이용해서 리스트를 생성할 수 있다.
4) 데이터 프레임
- 데이터의 행과 열을 모두 갖고 있기 때문에 구조는 데이터베이스나 스프레드시트와 유사하다.
- 벡터나 팩터의 리스트로 이해된다. 따라서 벡터와 리스트 둘 다의 측면을 갖고 있다.
- 만약 문제가 존재하는 경우 팩터로 변형하지 않을 경우 stringAsFactors 옵션을 갖고 있다.
- 데이터 프레임은 2차원 이며 매트릭스 형식으로 출력된다.
5) 매트릭스 & 배열
(1) 매트릭스
- 데이터의 행과 열로 2차우너 테이블을 표시하는 데이터 구조이다.
- 데이터의 하나의 타입으로 포함하며 전형적인 수치 데이터만을 저장하고 대부분 수학 연산에 사용된다.
- 매트릭스를 생성하기 위해서는 matrix() 함수에 열의 수나 행의 수를 명시하는 매개변수와 함께 데이터의 벡터를 제공한다.
- 매트릭스는 배열 형식을 2차원으로 나열한 형태라고 볼 수 있다.
2. 데이터 관리
1) 데이터 구조로 로드 및 저장
- 특정 데이터 구조를 차후에 다시 사용하거나 다른 시스템에 전송할 파일에 저장하기 위해 save() 함수를 사용한다.
- R 데이터 파일은 .RData 형식의 파일로 저장이 된다.
- 저장은 save()로 저장하며 로드는 load() 는 .RData 파일에 저장되어있는 데이터 구조를 다시 워크 스페이스로 로드시킨다.
2) CSV 파일의 데이터 import 및 저장
- 일반적으로 데이터를 텍스트 파일에 저장하는 경우가 많지만 표 형식의 데이터인 경우 한 줄은 하나의 예제를 반영하고 각 예제는 같은 수의 속성을 가진 매트릭스 형태로 구성된다.
- 대부분의 표 택스트 파일 형태는 콤마 분리 파일이다.
- .csv 파일은 구분자로 , 를 사용한다. 뿐만아니라 많은 애플리케이션에서 사용되는 형식이기도 하다.
- 데이터 로드는 read.csv() 를 사용하며 탭 구분값을 포함한 다른 구분 형태의 표 데이터를 읽을 수 있는 read.table() 함수의 특별한 형태로 볼 수 있다.
- 데이터 저장은 write.csv()를 사용하며 데이터 프레임 이름과 파일 이름을 입력한다.
3) SQL 데이터베이스로부터 데이터 import
- 오라클, MySQL 등의 SQL의 ODBC에 데이터가 저장되어 있다면 RODBC 패키지로 데이터베이스에서 R 데이터 프레임으로 옮길 수 있다.
- ODBC : 운영체제나 DBMS와 상관없이 데이터베이스에 접속할 수 있는 표준 프로토콜이다.
- RODBC를 사용하려면 DSN(Data Source Name), 사용자명, 비밀번호가 필요하다.
3. 데이터 이해와 탐구
- 데이터를 R 데이터 구조로 로드하고 모은 후에는 데이터를 상세하게 검토하는 일이다.
- 해당 단계에서는 데이터의 속성과 데이터에 나타나는 특이점을 찾는 일이다.
- 데이터에 대해서 정확하게 이해할 수록 학습문제에 관해 좀 더 적절한 기계학습 모델을 찾을 수 있다.
1) 데이터 구조 살펴보기
- 우선 데이터를 로드한다.
- 사용할 데이터는 usedcars.csv 데이터를 사용한다.
[R code]
usedcar <- read.csv("usedcars.csv", stringsAsFactors = F)
- 데이터 구조는 str() 함수를 사용하며 데이터프레임의 구조나 벡터나 리스트를 포함한 R 데이터 구조를 표시하는 방법을 제공한다.
[R code]
str(usedcar)
[실행결과]
'data.frame': 150 obs. of 6 variables:
$ year : int 2011 2011 2011 2011 2012 2010 2011 2010 2011 2010 ...
$ model : chr "SEL" "SEL" "SEL" "SEL" ...
$ price : int 21992 20995 19995 17809 17500 17495 17000 16995 16995 16995 ...
$ mileage : int 7413 10926 7351 11613 8367 25125 27393 21026 32655 36116 ...
$ color : chr "Yellow" "Gray" "Silver" "Gray" ...
$ transmission: chr "AUTO" "AUTO" "AUTO" "AUTO" ...
- 해당 데이터는 150개의 데이터와 6개의 변수로 구성되어있다는 것을 알 수 있다.
- 또한 각 변수에는 해당 변수가 어떤 형식의 데이터를 갖는 지 표시해준다.
2) 수치형 변수 살펴보기
- summary() : 데이터의 수지 변수를 조사하기 위해 요약 통계를 보기 위해 사용한다.
[R code]
summary(usedcar$year)
[실행결과]
Min. 1st Qu. Median Mean 3rd Qu. Max.
2000 2008 2009 2009 2010 2012
[R code]
summary(usedcar[c("price","mileage")])
[실행결과]
price mileage
Min. : 3800 Min. : 4867
1st Qu.:10995 1st Qu.: 27200
Median :13592 Median : 36385
Mean :12962 Mean : 44261
3rd Qu.:14904 3rd Qu.: 55125
Max. :21992 Max. :151479
- 수치형 변수인 경우에는 중심의 측정과 산포도의 측정 두 가지를 확인할 수 있지만 명목형 변수인 경우에는 각 항목에 대한 값을 확인 할 수 있다.
(1) 중심 경향 측정: 평균과 중앙값
- 데이터의 중심에 있는 값을 식별하기 위해 사용되는 통계 분류로 일반적인 중심(평균) 측정에 익숙할 수 있다.
- 평균은 데이터의 중심을 측정하기 위한 사용되는 통계이지만 항상 적절하지 않다.
- 중앙값은 일반적으로 사용하는 중심 경향 측정은 값의 리스트에서 중간에 있는 값을 의미한다.
(2) 산포도 측정: 사분위수와 다섯수치요약
- 다양성을 측정하기 위해 얼마나 값이 조밀하게 또는 느슨하게 분포되는지를 확인할 수 있다.
- 아래의 5가지 수치를 주로 사용한다.
- 최소값
- 1사분위수
- 중앙값 (2사분위수)
- 3사분위수
- 최대값
- 최소값과 최대값은 가장 크고 작은 극단적인 값이며 그 사이의 공간을 범위라고한다.
R에서는 range() 함수와 diff() 함수를 통해 하나의 명령으로 데이터의 범위를 나타낼 수 있다.
[R code]
diff(range(usedcars$price))
[실행결과]
[1] 18192
- 또한 중앙 50% 데이터를 의미하는 1사분위수와 3사분위수의 차이를 사분위수범위라고 하며, IQR() 함수를 통해 계산이 가능하다.
- 위에 대한 전반적인 내용은 quantile() 함수를 통해서도 제공이 되며, 사분위수를 식별하는데 많이 사용된다.
(3) 시각화
① Boxplot
- 수치형 변수에 사용되며 변수의 범위와 쏠림을 다른 변수와 비교해 쉽게 알 수 있게 보여준다.
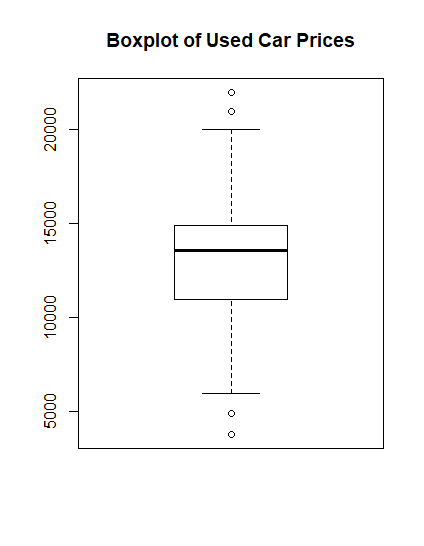
- 최소값과 최대값은 상자 끝부터 시작되는 점선으로 표시한다.
- 박스는 1사분위, 2사분위(중앙값), 3사분위 수의 경계를 차례로 보여준다.
② Histogram
- 수치형 변수의 퍼짐을 시각적으로 나타내는 방법
- 변수의 값을 미리 정해진 범위의 수나 값을 넣는 구간을 나눈다는 점에서 박스플롯과 유사하다.
- 차이점은 균등한 크기의 구간에 값이 있는 빈도수난 개수를 나타내는 막대로 구성된다.
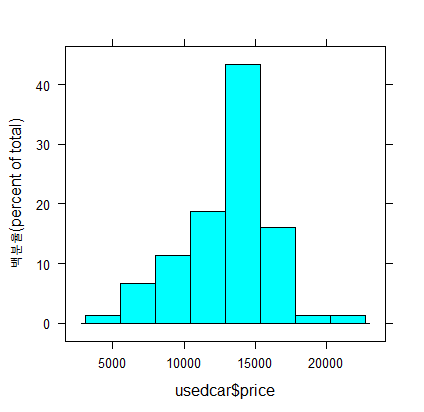
(4) 수치 데이터의 이해
① 변수의 분포
- 어떻게 변수가 여러 가지 범위안에 있는 지를 묘사하는 것
- 균등 분포: 모든 값이 균일하게 발생한다는 경우의 분포 (ex. 주사위 값을 기록한 데이터 셋)
- 정규분포: 실제 데이터에서 많이 보여지는 분포이며 값들이 다른 값과 빈도가 같지 않고 종 모양의 형태로 분포하는 경우를 의미함
② 퍼진 정도 측정
- 분산: 평균 주변으로 데이터가 얼마나 넓게 퍼져있는가를 나타내는 값
- 표준 편차: 값들이 평균과 비교했을 때 얼마나 차이나고 있는가를 나타내는 값
3) 범주형 변수 살펴보기
- 수치형 데이터와 비교해 범주형 데이터는 요약 통계보다 표를 사용해 살펴볼 수 있다.
[R code]
table(usedcar$model)
SE SEL SES
78 23 49
- 표 결과는 정상 변수의 범주를 나타내고 각 범주에 해당하는 개수를 나타낸다.
- 비율에 대한 계산은 prop.table을 이용하면 된다.
[R code]
prop.table(table(usedcar$model))
SE SEL SES
0.5200000 0.1533333 0.3266667
(1) 중심 경향 측정
① 최빈값
- 범주형 데이터에서 많이 사용되는 통계치
- 변수는 하나이상의 최빈값을 갖는다.
- 하나의 최빈값만 갖는 변수는 단봉, 두 개 이상의 최빈값을 가는 변수는 다봉이라고 한다.
- 데이터를 이해하는데 중요한 값을 이해하는 데 사용되지만 가장 일반적인 값이 대다수는 아니기 때문에 최빈값만을 강조하는 데는 위험이 있다.
4) 변수간의 관계 살펴보기
(1) 관계 시각화
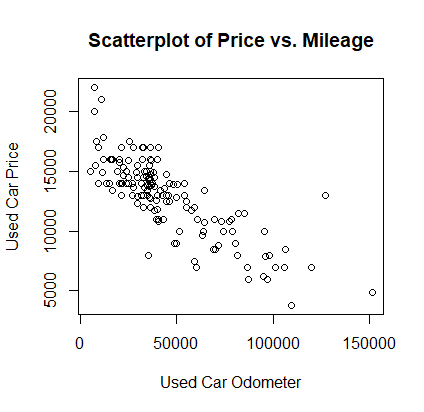
① 산포도
- 이변수 관계를 시각화하는 다이어그램
- 2개의 변수를 x, y으로 해서 좌표평면에 그리는 2차원 그래프이다.
② 이원 교차표
- 일반적인 변수간의 관계를 살펴보기 위해 사용됨
- 교차표는 한 값이 다른 값을 변경하는지 살표볼수 있다는 점에서 산포도와 유사하다.
- gmoldes 패키지의 CrossTable() 함수를 사용하면 된다.
[R code]
install.packages("gmodels")
library(gmodels)
usedcar$conservative <- usedcar$color %in%
c("Black", "Gray", "Silver","White")
table(usedcar$conservative)
CrossTable(x=usedcar$model, y=usedcar$conservative)
[결과]
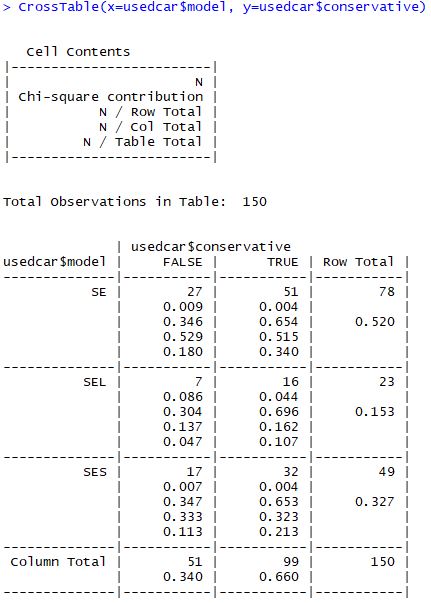
댓글남기기