
[Python Machine Learning] 4. 분류: 의사결정나무
1. 의사결정나무란?
트리 구조의 모델을 형성하며, 연결된 논리적인 결정을 통해 데이터를 분류하는 모델이다. 주로 설명이 중요한 경우에 사용되며, 분류, 회귀 및 다중출력 작업이 가능한 머신러닝 알고리즘이다.
해당 모델의 목표는 입력으로 받은 데이터를 보다 작고 동질적인 그룹으로 분할하는 것이다. 여기서의 동질적이란 분기별 노드가 보다 순수한(동일한 클래스의 비율이 높은) 성격을 갖는 것이다.
분류 문제에서의 순수도를 높이는 방법은 정확도를 높이거나 오분류를 낮추는 방법이 있다. 하지만 정확도를 이용하게 되면 하나의 클래스로 분류하는 방식으로 데이터를 분할하기 보다는, 오분류를 최소화하는 방식으로 데이터를 분할하는 것에 초점을 두게 되므로 목적에 어긋날 수 있으니 주의하자.
모델의 형태는 아래의 그림과 유사하다.
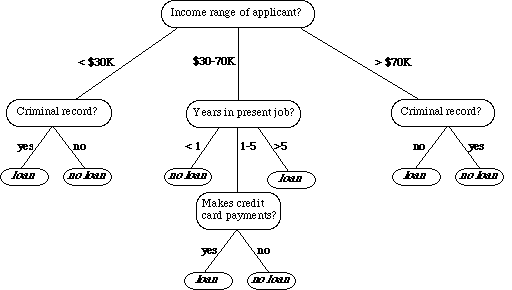
위의 그림처럼 기준에 따라 분류가 진행되며, 각 노드에서 가지가 나뉘는 원리는 해당 기준에 대해 정보 이득이 최대가 되는 특성으로 데이터를 분류하는 것이다.
이를 루트 노드부터 시작하여 가지가 나뉘게 되고, 기준을 정해 분류하는 일련의 과정이 반복되다가, 특정 시점에 이르어서 자식노드가 순수해 지면, (불순도가 낮아지면) 종료하게 된다.
1) 정보 이득(Information Gain)
가장 정보가 풍부한 특성으로 노드를 나누기 위해 트리 알고리즘으로 최적화할 목적함수를 정의한다. 이 함수는 각 분할에서 정보 이득을 최대화로하며, 이때의 정보이득은 아래와 같은 수식으로 표현할 수 있다.
$ IG(D_p, f)=I({D}_p)-\sum _{j=1}^m \frac {N_j} {N_p} I(D_j) $
위의 수식에서 나오는 문자들의 의미는 다음과 같다.
- Dp, Dj : 부모와 j번째 자식노드의 데이터 셋
- I : 불순도 지표
- Np , Nj : 부모노드의 전체 샘플 수, 자식 노드의 샘플 수
위의 내용을 통해서 알 수 있듯이, 정보 이동은 단순히 부모 노드의 불순도와 자식 노드의 불순도 합의 차이를 의미하는 것을 알 수 있다. 이 때 자식 노드의 불순도가 낮을수록 정보 이득이 커진다. 구현은 간단하게 하고 탐색 공간을 줄이기 위해서이다. 이를 위해 대부분의 라이브러리는 이진 결정 트리를 사용하며 부모노드는 자식노드 $D_left$, $D_right$ 로 나누어진다.
$ IG(D_p, f)=I(D_p) - \frac { N_{left} } {N_p} I(D_{left}) - \frac {N_{right}}{N_p}I(D_{right}) $
이진 결정 트리에서 널리 사용되는 3개의 불순도 지표(또는 분할 조건)는 지니 불순도, 엔트로피, 분류오차이다.
먼저 엔트로피에 대해서 알아보자. 원래 엔트로피는 열역학에서 분자의 무질서함을 측정하는 지표이다. 분자가 안정되고 질서정연해지면 엔트로피는 0이 가깝다. 이러한 원리를 정보공학으로 가져온 것이 엔트로피 불순도 지표이다. 임의의 샘플을 생성했다고 가정할 때, 샘플이 존재하는 모든 클래스에 대한 엔트로피는 다음과 같다.
$ I_{Entropy}(t) = - \sum _{i=1}^ep({i}\vert{t}) \log _2p({i}\vert{t}) $
위의 식에서 p(i|t)는 특정 노드 t에서 클래스 i에 속한 샘플비율을 의미한다. 예를 들어 클래스가 이진 클래스라고 가정해보자. 만약 모든 샘플이 같은 클래스라면 엔트로피는 0이 된다. 반대로 클래스 분포가 균등하다면 엔트로피는 최대가 된다. 만약 클래스 비율이 0.5 : 0.5 로 동일한 비율로 분포하고 있다면 엔트로피는 1이 된다.
결과적으로 엔트로피라는 것은 트리의 상호 의존 정보를 최대화하는 정보라고 볼 수 있다.
다음으로 지니 불순도를 살펴보자. 엔트로피와 비슷하게 지니 불순도는 잘못 분류될 확률을 최소화하기위한 기준으로 볼 수 있다. 엔트로피와 비슷하기때문에 클래스가 완벽하게 섞여 있을 때 최대 값을 갖게 된다. 수식으로는 아래와 같이 표현할 수 있다.
$ I_{Gini}(t) = \sum _{i=1}^c p({i}\vert{t})(1-p({i}\vert{t})) = 1 - \sum _{i=1}^cp{({i}\vert{t})}^2 $
앞서 엔트로피에서 예를 들었듯, 이진 클래스일 경우(c=2), 지니 불순도를 계산한 결과는 다음과 같다.
$ I_{Gini}(t) = 1 - \sum _{i=1}^c{0.5}^2=0.5 $
실제로 지니 불순도와 엔트로피 모두 비슷한 결과가 나오게 되며 보통 불순도 조건을 바꾸어 트리를 평가하기 보다 가지치기 수준을 바꾸면 튜닝하기에 수월하다. 만약 엔트로피 불순도와 지니 불순도 중 어떤 것을 사용하는 것이 좋냐는 질문이 있다면 결과적으로는 둘 다 비슷한 트리를 만들어 낸다. 다만 속도에 있어 지니 불순도로 연산하는 것이 좀 더 빠르다는 면이 있다.
마지막으로 분류오차를 살펴보자. 분류오차는 주로 가지치기에 좋은 기준이긴하지만, 결정 트리를 구성하는 것에 있어서는 권장 사항이 아니다. 노드의 클래스 확률 변화에 둔감하기 때문이다.
위에서 설명한 3가지 기준에 대해 시각적으로 비교하기 위하여 클래스 1[0, 1]에 대한 불순도 인덱스를 그려보면 다음과 같다.
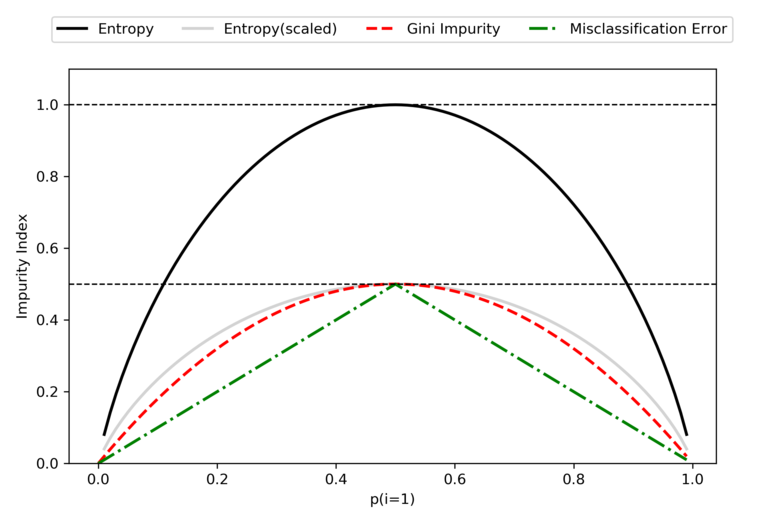
정리를 해보자면 의사결정나무를 구성할 때, 노드가 분할되는 기준은 구분 뒤 각 영역의 순도가 증가하는 방향으로, 불순도 혹은 불확실성이 최대한 감소하는 방향으로 학습이 진행된다 할 수 있다.
2) CART 알고리즘
사이킷런에서 의사결정나무를 성장시키기 위해 사용되는 알고리즘 중 하나로, 훈련 세트를 하나의 특성 k의 임계값 t 를 사용해 2개의 서브 셋으로 나눈다. 나눌 때 가장 순수한 서브셋으로 나눌 수 있는 특성 k 와 임계값 t 를 쌍으로 하며, 최소화해야 하는 비용함수는 아래의 식과 같다.
$ J(k, t_k) = \frac {m_{left}} m G_{left} + \frac {m_{right}} m G_{right} $
훈련세트를 성공적으로 둘로 나누었다면 같은 방식으로 서브셋을 반복적으로 나누어 준다. 만약 최대 깊이에 도달하거나, 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 중지하게 된다.
하지만 최적의 트리를 찾는 것은 어렵다. 이유는 시간상 O(exp(m)) 만큼의 시간복잡도가 존재하기 때문에 그만큼의 시간이 필요하며, 매우 작은 훈련세트도 적용하기 어렵기 때문이다.
2. 모델 생성하기
진행하기에 앞서 graphviz를 먼저 설치한다.
graphviz 는 DOT 언어 스크립트로 지정된 그래프 그리기를 위해 AT&T 랩스 리서치가 시작한 오픈 소스 도구 패키지이며 이번 장에서 의사결정나무 모델에 대한 시각화를 그릴 때 필요하기 때문에 먼저 설치를 하고 시작하는 것을 추천한다.
설치파일은 아래의 페이지에서 다운 받을 수 있다.
https://graphviz.gitlab.io/download/
graphviz 외에도 Python에는 pydotplus 패키지가 있다. Graphviz와 비슷한 기능을 하며, .dot 데이터 파일을 의사결정나무 이미지 파일로 변환해준다. 방법은 다음과 같다.
[pip 설치]
pip install pydotplus
pip install graphviz
pip install pyparsing
[conda 설치]
conda install pydotplus
conda install graphviz
conda install pyparsing
이번 예제에서는 앞서 이용했던 iris 데이터를 이용하여 의사결정나무 모델을 만들어보자. 모델의 분류 시 사용할 불순도 지표로는 지니 계수를 사용하며, 이를 위해 파라미터 criteria = “gini” 로 설정한다. 또한 의사결정나무가 너무 깊게까지 노드를 생성하지 않도록 최대 깊이는 4로 지정한다.
[Python Code]
iris = datasets.load_iris()
x = iris.data[:, [2, 3]]
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1, stratify=y)
def plot_decision_regions(x, y, classifier, test_idx=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ("red", "blue", "lightgreen", "gray", "cyan")
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = x[:, 0].min() - 1, x[:, 0].max() + 1
x2_min, x2_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
z = z.reshape(xx1.shape)
plt.contourf(xx1, xx2, z, alpha=.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x = x[y == cl, 0], y = x[y == cl, 1],
alpha=0.8, c=colors[idx], marker=markers[idx],
label=cl, edgecolors="black")
if test_idx:
x_test, y_test = x[test_idx, :], y[test_idx]
plt.scatter(x_test[:, 0], x_test[:, 1],
c='', edgecolors="black", alpha=1.0,
linewidth=1, marker="o",
s=100, label="test set")
tree = DecisionTreeClassifier(criterion="gini", max_depth=4, random_state=1)
tree.fit(x_train, y_train)
x_ned = np.vstack((x_train, x_test))
y_ned = np.hstack((y_train, y_test))
plot_decision_regions(x_ned, y_ned, classifier=tree, test_idx=range(105, 150))
plt.xlabel("Petal Length(cm)")
plt.ylabel("Petal Width(cm)")
plt.legend(loc="upper left")
plt.tight_layout()
plt.show()
save_fig("iris_decisionTreeClassifier")
[실행 결과]
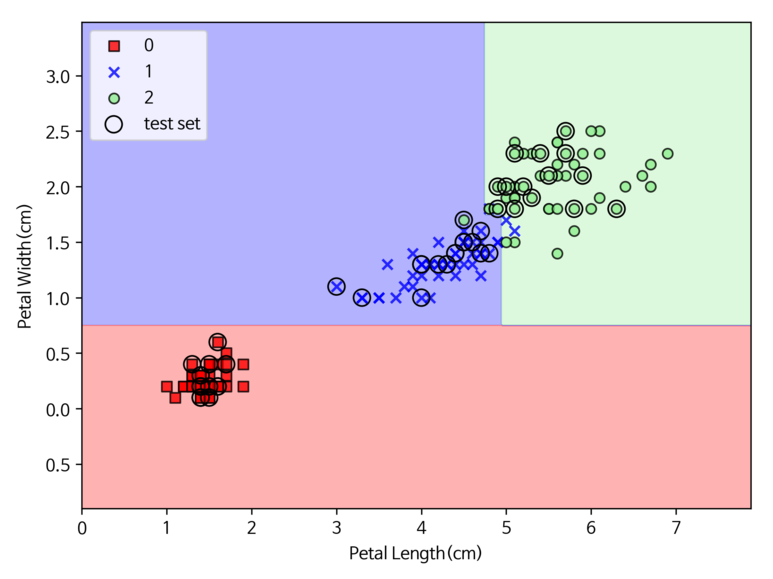
추가적으로 모델을 생성할 때 어떻게 의사결정을 했는지 확인하기 위해 아래의 코드도 실행하여 결과를 확인해보자.
[Python Code]
dot_data = export_graphviz(tree, filled=True, rounded=True, class_names=["Setosa", "Versicolor", "Virginica"],
feature_names=["Petal Length", "Petal Width"], out_file=None)
graph = graph_from_dot_data(dot_data)
graph.write_png("images/decision_trees/iris_decisionTreeDetail.png")
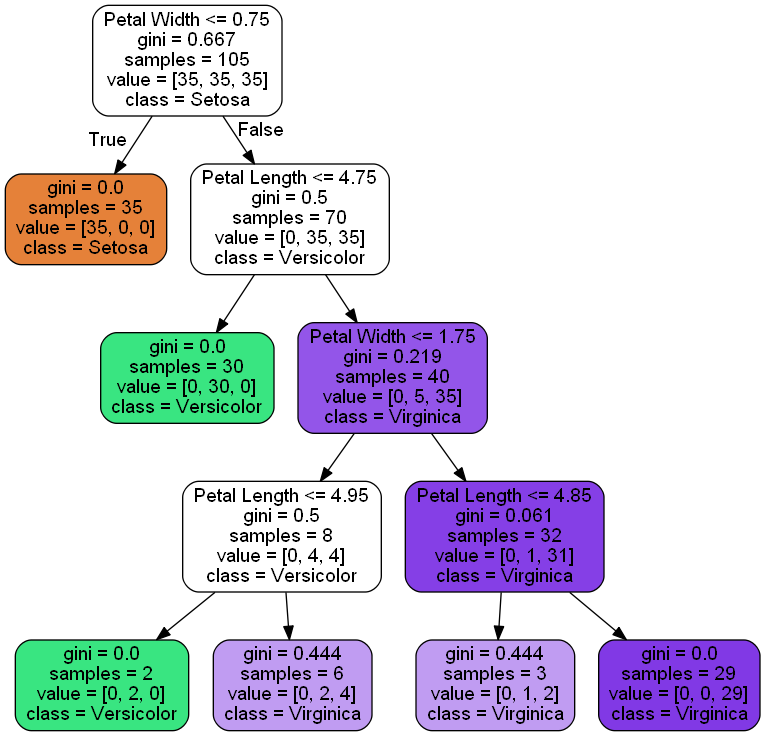
위의 결과를 살펴보면, 처음 시작은 105개의 샘플로 시작을 했다. 그다음 꽃입 너비 기준 0.75이하인 경우를 사용해 35개와 70개의 샘플로 분할 하였다. 각 노드에서 클래스별 샘플 수는 value 부분을 확인하면 되며, 왼쪽부터 Setosa, Versicolor, Virginica 순으로 분류된 샘플 수를 의미한다고 할 수 있다. 분할 결과 중 첫번째 결과인 iris-setosa 클래스를 갖는 순수노드로 분할했다. 다음으로 오른쪽 부분에서 추가적으로 iris-Versicolor 와 iris-Virginica 에 대한 분류 기준으로 보여준다. 색이 진할 수록 해당 노드에서 완벽하게 분류했다는 것을 알 수 있다.
3. 클래스 확률 추정
한 샘플이 특정 클래스 k에 속할 확률을 추정할 수 있다. 먼저 샘플에 대해 리프 노드를 찾기 위해 트리를 탐색하고 노드에 있는 클래스 k의 훈련 샘플의 비율을 반환한다.
의사결정나무 모델에서는 predict_proba() 메소드를 통해 이를 계산할 수 있으며, 함수 입력으로 사용할 값을 list in list 형식([[ ]]) 으로 넣어준다.
[Python Code]
tree.predict_proba([[5, 1.5]])
tree.predict([[5, 1.5]])
[실행 결과]
Out[6]: array([[0. , 0.33333333, 0.66666667]])
Out[7]: array([2])
실행 결과를 통해서 알 수 있듯이, 입력한 값(5, 1.5) 에 대해서 클래스 2로 추정되는 비율이 가정 높았고 실제로 예상한 클래스 역시 클래스 2(Virginica) 가 출력되는 것을 확인할 수 있다.
4. 의사결정나무 규제
의사결정나무의 경우에는 훈련데이터에 대해 제약은 없다. 다만, 훈련되기전에 파라미터 수가 결정되지 않는 비파라미터 모델이기 때문에, 모델에서 사용되는 파라미터값에 제한을 두지 않으면 훈련 데이터에 과대적합되기 쉽다는 단점이 존재한다.
일반적으로 의사결정나무의 최대 깊이인 max_depth 파라미터를 제어하는 경우가 많지만, 그 외에 다른 파라미터들도 같이 살펴보자. 아래의 내용과 같다.
- min_sample_split: 분할되기 위해 노드가 가져야하는 최소 샘플 수
- min_sample_leaf: 리프 노드가 가지고 있어야 할 최소 샘플 수
- min_weight_fraction_leaf: min_sample_leaf 와 같으나 가중치가 부여된 전체 샘플의 비율
- max_leaf_nodes: 리프노드의 최대 수
- max_features: 각 노드에서 분할에 사용할 특성의 최대 수
- max_depth: 의사결정나무의 최대 깊이
5. 의사결정나무 회귀
의사결정나무는 회귀 문제에서도 사용할 수 있다. 다만 모델이 DecisionTreeRegressor로 변경된다는 점이다.
예시로 노이즈가 섞인 2차 함수 형태의 데이터셋에서 max_depth=2 인 경우와 max_depth=3 인 경우의 비교 설정으로 회귀 트리를 만들어 보자.
[Python Code]
import numpy as np
from sklearn.tree import DecisionTreeRegressor
# 추가적인 비교
## 2차식으로 만든 데이터셋 + 잡음
np.random.seed(42)
m = 200
x = np.random.rand(m, 1)
y = 4 * (x - 0.5) ** 2
y = y + np.random.randn(m, 1) / 10
tree_reg1 = DecisionTreeRegressor(random_state=42, max_depth=2)
tree_reg2 = DecisionTreeRegressor(random_state=42, max_depth=3)
tree_reg1.fit(x, y)
tree_reg2.fit(x, y)
위의 코드를 실행하고 시각화를 해보면 다음과 같다.
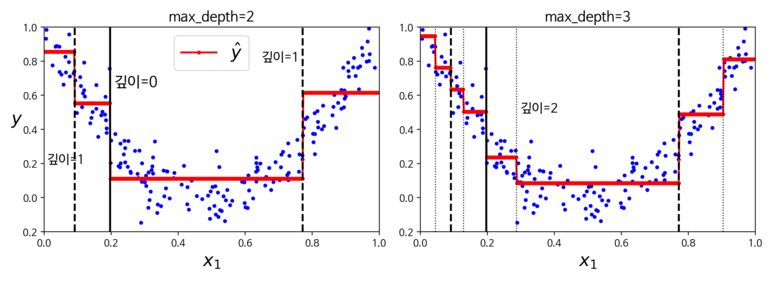
의사결정나무 회귀 모델 최대 깊이에 따른 비교
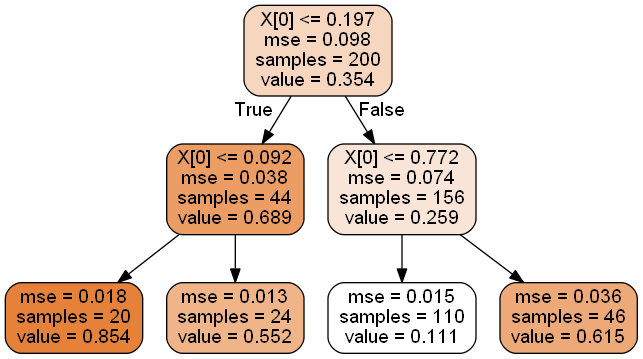
max_depth = 2 인 경우
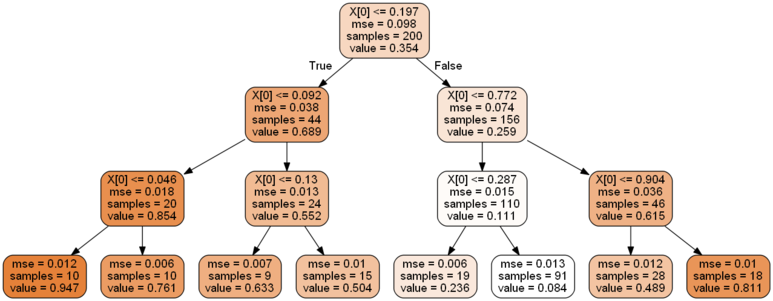
max_depth = 3 인 경우
첫번째 시각화를 통해서 최대 깊이가 깊을 수록 데이터 분포 및 그래프 상에서 분할 구간이 자세하게 나누어 지는 것을 확인할 수 있다. 각 영역의 예측값은 항상 그 영역에 있는 타깃값의 평균값을 의미하며, 알고리즘은 예측값과 가능한 많은 샘플이 가까이 있도록 영역을 분할한다.
앞서 살펴본 분류 문제일 경우의 의사결정나무 구성과 거의 유사하다는 것을 알 수 있다.다만, 주요한 차이점은 각 노드에서 클래스를 예측하는 것이 아니라 어떤 값을 예측한다는 점이 분류 모델과의 차이라고 할 수 있다.
댓글남기기