
[Python Machine Learning] 13. 모델 성능 평가
0. 들어가며
이번장에서는 모델의 성능과 관련하여 모델의 성능평가 및 성능개선을 하기 위해 사용되는 방법을 알아보자.
1. 모델 성능 평가
머신러닝으로 생성한 모델에 대해 얼마나 잘 예측하는지를 확인하기 위해 반드시 필요한 작업이며, 모델의 성능 여부에 따라 이후에 알아볼 모델의 성능개선이 필요한지를 판단할 수 있는 단계이다. 모델의 성능평가는 주로 지도학습인 경우에 많이 사용되며, 사용한 모델에 따라 크게 회귀모델일 때와 분류모델일 때로 나눠서 살펴볼 수 있다.
1) 회귀 모델의 경우
회귀 모델의 경우 일반적으로 예측에 대한 결과가 수치 이며, 모델링을 하게 되면 우선적으로 아래의 내용들을 점검해봐야 한다.
(1) 점검 사항
① 모형이 통계적으로 유의미한가?
이에 대해서는 F통계량 값을 확인한다. 유의수준 5% 이하에서 F 통계량의 p-value 가 0.05 보다 작은 경우, 해당모델은 통계적으로 유의미하다고 본다.
② 회귀계수는 유의미한가?
각 독립 변수에 대한 회귀 계수들의 t통계량 혹은 p-value 값이 유의수준보다 작은 지 확인하면 된다.
③ 모형이 얼마나 설명력을 갖는가?
이에 대해서는 결정계수(R2-score) 를 확인하면 된다. 일반적으로 결정계수는 0 ~ 1 사이의 값을 가지며, 값이 클 수록 모델링한 회귀 모델은 설명력이 높다고 보면 된다.
④ 모형이 데이터에 적합한가?
이는 잔차 그래프로 확인할 수 있다.
앞선 2장 회귀에서 잔차 분석에 대한 방법과 MSE, 결정계수에 대한 내용은 확인했으며, 모형이 통계학적으로 유의미 한지는 정규방정식을 사용하거나, statsmodels.formula.api 의 sm.ols() 함수를 사용하여 회귀 모형을 만든 후, summary() 메소드로 확인하면 된다. 하지만, 해당 내용은 통계학습과 연관있기 때문에 간단하게 아래의 코드로 사용법만 확인하고, 궁금한 사람은 직접 실행해보기 바란다.
[Python Code]
import statsmodels.formula.api as sm
df_data = pd.DataFrame(data, columns=column_name)
df_data["Price"] = target
res = sm.ols(data=df_data, formula="Price ~ RM").fit()
res.summary()
(2) 기타 오차 함수
앞서 언급했던 데로 2장에서 이미 MSE와 결정계수에 대해서는 배웠지만, 그 외에 다른 오차 함수들을 살펴보고 필요에 따라 사용할 수 있도록 하자. MAE 와 RMSE를 살펴볼 예정이며, 2개에 대한 설명 및 사용법은 아래와 같다.
① MAE (Mean Absolute Error)
모델의 예측값과 실제값의 차이, 오차에 대해 절대값의 합으로 계산하는 것으로, 절대값을 취하기 때문에 가장 직관적으로 알 수 있는 지표이다. 뿐만 아니라 MSE(평균제곱오차) 보다 이상치에 대한 저항을 가지고, 데이터의 특성도 잘 들어내는 특징이 있지만, 절대값으로 처리되기 때문에 모델이 예측한 결과가 실제 값보다 높은지, 낮은지에 대해서 확인이 어려울 수 있다.
[Python Code]
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_pred=y_pred, y_true=y_test)
print(mae)
[실행결과]
3.1627098714574235
② RMSE (Root Mean Squared Error)
기존의 MSE에 제곱근(Root)를 추가함으로써, 오류 지표를 실제 값과 유사한 단위로 변환 및 해석이 가능하다.
scikit-learn 에서는 해당 함수가 없기 때문에 MSE에 제곱근을 추가하여 계산한다.
[Python Code]
import numpy as np
from sklearn.metrics import mean_squared_error
rmse = np.sqrt(mean_squared_error(y_pred=y_pred, y_true=y_test))
print(rmse)
[실행결과]
4.638689926172841
2) 분류 모델의 경우
분류 모델의 평가는 예측 및 분류를 위해 구축된 모형이 임의의 모형보다 더 우수한 분류 성과를 보이는지와 고려된 서로 다른 모형들 중에서 가장 우수한 예측 및 분류 성과를 갖는 지 등을 비교 분석하게 된다.
(1) 점검 사항
분류 모델의 경우, 확인해야될 점검사항은 아래와 같다.
① 일반화의 가능성
같은 모집단 내의 다른 데이터에 적용하는 경우, 안정적인 결과를 제공하는 가에 대한 지표로, 모델이 얼마나 확장성이 있는지를 살펴보는 지표라고 할 수 있다.
② 효율성
분류 분석 모형이 얼마나 효과적으로 구축되었는지를 평가하며, 입력 변수의 개수가 적음에도 잘 분류한다면, 효율성이 높다고 평가한다.
③ 예측 및 분류 정확성
구축된 모형의 정확성 측면에서 평가하는 것으로 안정적이고 효율적인 모형을 구축했다 한들, 실제 적용해야되는 데이터를 직면했을 때, 정확한 결과를 산출하지 못한다면 의미가 없어진다.
(2) 검증 (Validation)
검증을 하는 이유는 앞선 12장에서 언급한 것처럼, 모델의 정확한 성능을 측정하기 위함이며, 동시에 과적합을 방지하는 단계라고도 볼 수 있다. 12장에서는 검증의 방법중 하나로, 학습용 데이터를 다시 훈련용과 검증용으로 분리하는, 홀드아웃(Hold-Out) 기법에 대해 살펴보았다. 이번 장에서는 홀드아웃 기법 외에, 교차검증, 부트스트랩 기법에 대해 추가적으로 살펴보도록 하자.
① 교차검증(Cross Validation)
주어진 데이터를 가지고 반복적으로 성과를 측정해서 나온 결과의 평균으로 분류 분석 모형을 평가하는 방법이다. 대표적으로는 k-fold 교차검증 방법이 있는데, 전체 데이터를 동일한 사이즈의 k 개로 하부 집합을 구성한다. 이 후 학습 시, k 번째의 데이터는 검증용으로, 나머지 데이터는 훈련용으로 사용해 총 k 번 반복 측정을 하고, 결과들의 평균값으로 전체 모델의 성능을 산출한다.

scikit-learn 에서의 구현방법은 아래와 같다.
[Python Code]
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.model_selection import KFold
iris = load_iris()
scaler = StandardScaler()
x = scaler.fit_transform(iris.data)
y = (iris.target == 2).astype(np.float64) # Y = 1 / N = 0
kfold = KFold(n_splits=10)
predictions = []
train_count = 0
for train_idx, test_idx in kfold.split(x, y):
train_count += 1
x_train, x_test = x[train_idx], x[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
total = len(x_test)
correct = 0
for i in range(len(y_pred)):
if y_pred[i] == y_test[i]:
correct+=1
print("{} 회 학습 결과 : ".format(train_count), round(100 * correct / total , 2), "%")
predictions.append(round(100 * correct / total , 2))
print("="*10)
print("{}-Folds 학습 결과 : ".format(train_count), round(np.mean(predictions), 2), "%")
[실행결과]
1 회 학습 결과 : 100.0 %
2 회 학습 결과 : 100.0 %
3 회 학습 결과 : 100.0 %
4 회 학습 결과 : 100.0 %
5 회 학습 결과 : 93.33 %
6 회 학습 결과 : 93.33 %
7 회 학습 결과 : 100.0 %
8 회 학습 결과 : 100.0 %
9 회 학습 결과 : 80.0 %
10 회 학습 결과 : 100.0 %
==========
10-Folds 학습 결과 : 96.67 %
② 부트스트랩(Bootstrap)
평가를 반복한다는 측면에서, 앞서 본 교차 검증과 유사하지만, 훈련용 데이터를 반복적으로 재선정한다는 점에서 차이가 있다. 관측치를 한 번 이상 훈련용 자료로 사용하는 복원추출법에 기반한 학습 방법이다. 따라서 훈련용 자료 선정을 d번 반복할 때 하나의 관측치가 선정될 확률은 1/d 가 된다.
일반적으로는 훈련용 데이터의 63.2%를 훈련으로, 나머지 36.8%는 훈련용으로 선정되지 않기 때문에 검증용으로 선정된다.
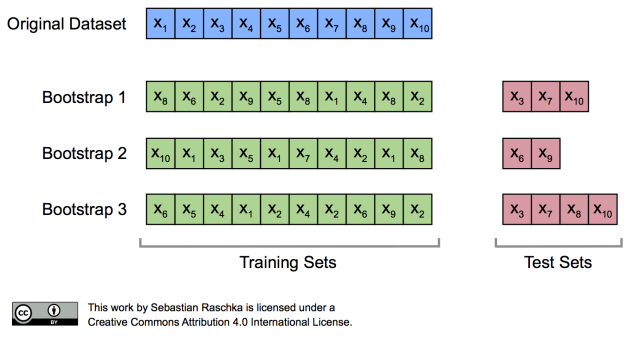
scikit learn에는 이전에 cross_validation 패키지 안에 Bootstrap 이라는 함수가 존재했으나, 최신 버전에서는 더이상 존재하지 않으며, 대신 util 패키지의 resample 함수를 이용해서 부트스트랩을 구현할 수 있다.
방법 중 하나로 아래와 같이 구현할 수 있다.
[Python Code]
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.utils import resample
iris = load_iris()
scaler = StandardScaler()
x = scaler.fit_transform(iris.data)
y = (iris.target == 2).astype(np.float64) # Y = 1 / N = 0
x_train, y_train = resample(x, y, n_samples=int(x.shape[0] * 0.7))
x_test = np.array([value for value in x if x.tolist() not in x_train.tolist()])
y_test = np.array([value for value in y if y.tolist() not in y_train.tolist()])
....
3) 학습 곡선 & 검증 곡선
(1) 학습 곡선을 이용한 편향과 분산 문제 분석
학습 데이터 셋에 비해 모델이 더 복잡한 경우(모델의 자유도 혹은 사용되는 파라미터 수가 많은 경우) 훈련 데이터에 과적합 되기 쉽고, 처음 본 데이터에는 일반화가 어려워지는 경향이 존재한다. 훈련 샘플을 더 모으는 것이 과대적합을 줄이는 데 도움이 되긴하지만, 일반적으로 실전에서는 데이터를 더 모으는 데에 많은 비용이 들거나, 불가능한 경우도 존재한다.
이럴 경우 모델의 훈련 정확도와 검증 정확도를 훈련 데이터의 크기 함수로 그래프를 그려보면, 모델의 분산이 높아서 발생하는 문제인지, 편향이 높아서 인지 등을 쉽게 감지할 수 있다.
방법을 살펴보기 전에, 우선 모델이 적합할 때, 분산이 높을 때, 편향이 높을 때에 따라, 훈련 샘플 수에 따라 훈련 정확도와 검증 정확도가 어떻게 나타나는지를 살펴보자.
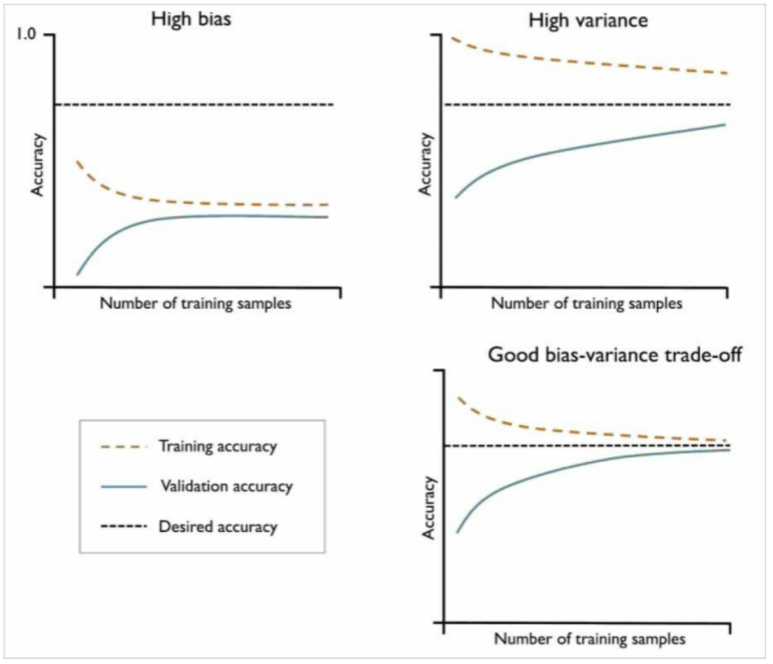
왼쪽 상단의 그래프는 분산이 높은 경우를 나타낸다. 그래프를 보면 알 수 있듯이, 분산이 높아질수록, 모델의 훈련 정확도와 검증 정확도가 낮아지는 것을 확인할 수 있다. 분산을 낮추기 위해서는 모델의 파라미터 개수를 증가시키는 것이다. 추가적인 특성을 수집하거나 생성하게 되는 것도 하나의 방법이다. 반대로 편향이 높아지게 되면 오른쪽 상단의 그래프처럼 훈련 정확도 그래프와 검증 정확도 그래프 사이에 간격이 넓어진다. 즉, 간격만큼의 차이 있다는 것을 보여주며, 이를 해결하기 위해서는 훈련 데이터를 모으거나, 모델 복잡도를 낮추거나, 규제를 통해 해결할 수 있다. 만약 좋은 모델이라면, 오른쪽 하단의 그래프와 같이 훈련 정확도와 검증 정확도 그래프의 간격이 최대한 가깝게 나올 것이다.
이제 위의 내용을 쉽게 확인할 수 있는 방법인, 학습 곡선을 그리는 방법을 살펴보자.
[Python Code]
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split, learning_curve
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
import matplotlib.pyplot as plt
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
le.classes_
le.transform(['M', 'B'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=1)
pipe_lr = make_pipeline(
StandardScaler(),
LogisticRegression(
solver='liblinear',
penalty='l2',
random_state=1
)
)
train_sizes, train_scores, test_scores = learning_curve(estimator=pipe_lr, X=X_train, y=y_train
, train_sizes=np.linspace(0.1, 1.0, 10), cv=10, n_jobs=1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(train_sizes, train_mean,
color='blue', marker='o',
markersize=5, label='training accuracy'
)
plt.fill_between(train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15, color='blue'
)
plt.plot(train_sizes, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='validation accuracy'
)
plt.fill_between(train_sizes,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green'
)
plt.grid()
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.8, 1.03])
plt.tight_layout()
plt.show()
[실행 결과]
위의 코드 중에서 learning_curve() 함수의 파라미터인 train_sizes 를 통해 학습곡선을 생성하는 데 사용할 훈련 샘플의 개수나 비율을 지정할 수 있다. 위의 예제에서는 np.linspace(0.1, 1.0, 10) 을 통해 일정한 간격으로 훈련 데이터의 비율을 총 10개 생성하였다.
learning_curve() 함수는 기본적으로 k-folds 교차 검증을 사용하여 분류기의 교차 검증 정확도를 계산한다. 예제의 경우 총 10개의 비율로 나눴기 때문에 10-folds 교차 검증을 수행하게 된다.
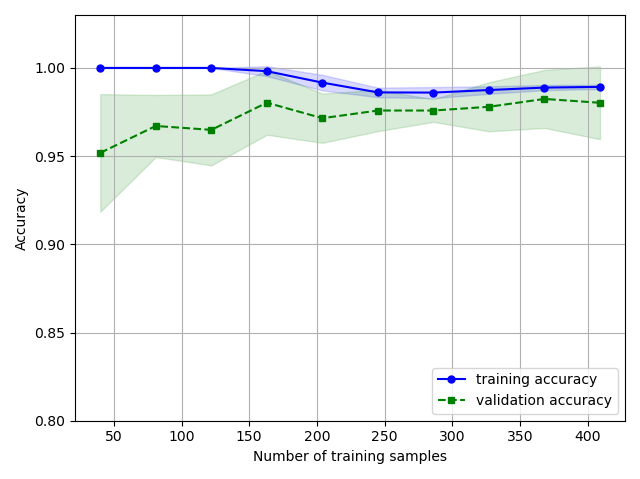
반환된 결과를 보면, 훈련과 테스트 교차 검증 점수로부터 훈련 세트 크기별로 평균 정확도를 계산해 그래프를 그렸다. 이 후 fill_between() 함수를 추가해줌으로써, 평균 정확도의 표준 편차를 같이 그려서 추정 분산을 나타냈다.
위의 그래프는 모델 훈련 샘플로 총 250개 이상을 사용할 경우 훈련과 검증이 잘되는 것을 나타낸다. 반면, 훈련 세트가 250개의 샘플보다 작을 경우, 훈련 정확도와 검증 정확도 간의 간격이 증가하는 것을 볼 수 있는데, 이는 과대적합의 확률이 증가한다고 볼 수 있다.
(2) 검증 곡선을 이용한 과대/과소적합 분석
앞서 본 훈련 곡선과 달리 검증 곡선은 과소적합 문제를 해결하여 모델의 성능을 높이는 방법으로 사용할 수 있다.
일반적으로 검증 곡선은 학습 곡선과 관련이 있지만, 모델 파라미터 값으로 함수를 표현한다.
아래의 예시를 통해 어떤 의미인지를 살펴보자.
[Python Code]
from sklearn.model_selection import validation_curve
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
train_scores, test_scores = validation_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
param_name='logisticregression__C',
param_range=param_range,
cv=10
)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(param_range, train_mean, color='blue', marker='o', markersize=5, label='train_accuracy')
plt.fill_between(param_range, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(param_range, test_mean, color='green', linestyle='--', marker='s', markersize=5, label='validation_accuracy')
plt.fill_between(param_range, test_mean + test_std, test_mean - test_std, alpha=0.15, color='green')
plt.grid()
plt.xscale('log')
plt.legend(loc="lower right")
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.ylim([0.8, 1.00])
plt.tight_layout()
plt.show()
[실행 결과]
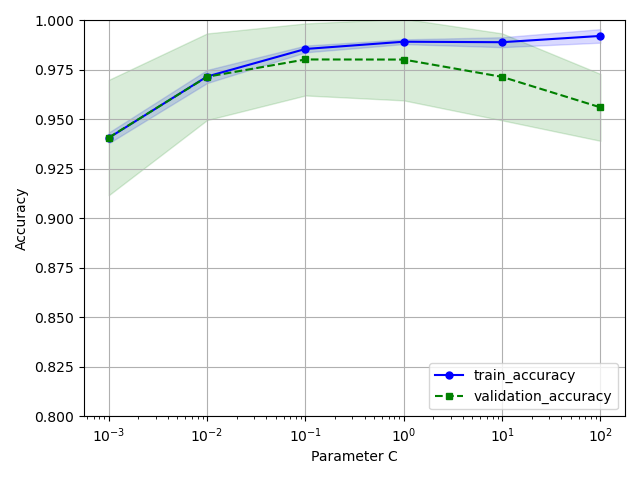
validation_curve 역시 앞서본 learning_curve와 비슷하게 기본적으로 k-folds 교차 검증을 사용하여 모델의 성능을 추정한다. 함수 내에는 평가하기 원하는 매개변수를 지정하면 된다. 위의 예시에서는 규제 매개변수인 C를 측정하였다. 또한 매개변수 C 는 이전에 생성한 파이프라인 내의 LogisticRegression 객체의 매개변수이기 때문에, param_name 매개변수의 값을 ‘logisticregreesion__C’ 로 지정하면 된다.
위의 그래프를 살펴보면, C 값이 작아질 수록, 정확도 차이가 미묘하게 과소적합되는 것을 확인할 수 있다. 반면, 규제강도가 낮아지는, C 값이 커지는 구간에서는 모델이 데이터에 조금 과대적합되는 현상도 볼 수 있다. 결과적으로 최적의 C 값을 찾게 되면, 0.01 ~ 0.1 사이의 구간으로 볼 수 있다.
2. 성능 평가 지표
1) 오차 행렬(Confusion Matrix)
분류 문제에서 예측결과와 실제 값 사이에 발생하는 4가지의 경우를 정리한 정방행렬을 의미하며, 구성은 다음과 같다.
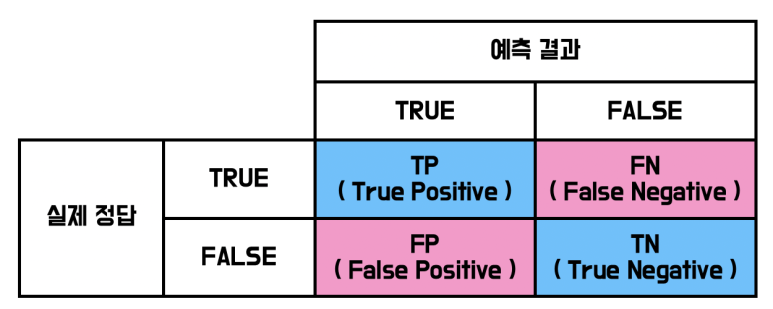
사이킷 런에서는 confusion_matrix() 함수를 통해 구현할 수 있다.
[Python Code]
from sklearn.metrics import confusion_matrix
from sklearn.svm import SVC
...
pipe_svc = make_pipeline(StandardScaler(),
SVC(random_state=1))
pipe_svc.fit(X_train, y_train)
y_pred = pipe_svc.predict(X_test)
cm = confusion_matrix(y_true=y_test, y_pred=y_pred)
print(cm)
[실행 결과]
[[71 1]
[ 2 40]]
위의 코드 실행 결과처럼 2x2행렬을 생성하지만, 숫자만 나오기 때문에 한눈에 보기에는 조금 어려울수 있다. 따라서 위의 행렬을 그래프로 나타내는 것을 확인해보자.
[Python Code]
fig, ax = plt.subplots(figsize=(2.5, 2.5))
ax.matshow(cm, cmap=plt.cm.Blues, alpha=0.3)
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(x=j, y=i, s=cm[i, j], va='center', ha='center')
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.tight_layout()
plt.show()
[실행 결과]
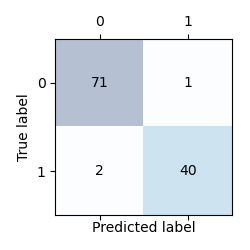
이번에는 오차행렬과 관련된 지표에 대해서 살펴보자.
2) 정분류율 (Accuracy)
전체 관측치 중 실제 값과 예측가 일치한 정도를 의미하며, 범주의 분포가 균형을 이룰 때 효과적인 평가 지표로 볼 수 있다.
$ acc = \frac {TP+TN} {P+N} = \frac {TP+TN} {TP+FN + TN+FP} $
3) 민감도 (Sensitivity)
실제 값이 True 인 관측치 중 예측치가 적중한 정도를 의미한다.
$ sensitivity = \frac {TP} {P} = \frac {TP} {TP+FN} $
4) 특이도(Specificity)
실제 값이 False 인 관측치 중 예측 값이 적중한 정도를 의미한다.
$ specificity = \frac {TF} {F} = \frac {TF} {TN+FP} $
5) 정확도(Precision)
True로 예측한 관측치 중 실제 값이 True 인 정도를 나타내는 정확성을 의미한다.
$ precision = \frac {TP} {TP+FP} $
6) 재현율 (Recall)
실제 값이 True 인 관측치 중에 예측치가 적중한 정도를 의미하며, 민감도와 동일한 지표이자, 모델의 완전성을 평가하는 지표라고 할 수 있다.
$ recall = \frac {TP} {P} = \frac {TP} {TP+FN} $
7) 분류정확도(F1 Score)
정확도(Precision) 과 재현율의 조화 평균으로, 분류 모델에서 사용된다. 조화 평균으로 계산한 이유는 정확도와 재현율이 0에 가까울수록 F1 Score 도 동일하게 낮은 값을 갖도록 하기 위함이다.
$ F1 Score = 2 \times \frac {precision \times recall} {precision + recall} $
파이썬에서 위의 7가지 지표들에 대해서는 sklearn.metrics 에서 구현되어 있다.
[Python Code]
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score
labels = [1, 0, 0, 1, 1, 1, 0, 1, 1, 1] # 실제 labels
guesses = [0, 1, 1, 1, 1, 0, 1, 0, 1, 0] # 에측된 결과
print(accuracy_score(labels, guesses)) # 0.3
print(recall_score(labels, guesses)) # 0.42
print(precision_score(labels, guesses)) # 0.5
print(f1_score(labels, guesses)) # 0.46
[실행 결과]
0.3
0.42857142857142855
0.5
0.4615384615384615
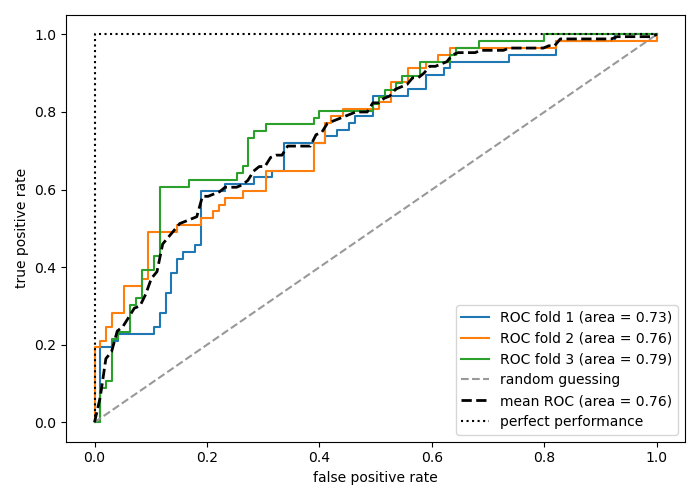
8) ROC (Receiver Operation Characteristic) curve & AUC (Area Under the ROC Curve)
ROC 커브는 레이더에서 사용되는 수식을 분류모델의 평가지표로 활용한 것이며, 분류모형의 비교 분석 결과를 시각화한 그래프이다. x 축은 1-특이도를, y 축은 민감도로 구성된다. 좋은 모델일 수록 x 축은 0, y 축은 1에 가까워지며, y=x 인 직선에 대해 직각삼각형의 형태로 나타난다.
AUC(Area Under the ROC Curve) 는 ROC 커브 아래의 영역을 의미하며, 좋은 모델일 수록 값이 1에 가깝다.
ROC 곡선 Scikit-Learn 에서의 구현방법은 다음과 같다.
[Python Code]
import numpy as np
import pandas as pd
from numpy import interp
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import StratifiedKFold, train_test_split
from sklearn.pipeline import make_pipeline
from matplotlib import pyplot as plt
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
le.classes_
le.transform(['M', 'B'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=1)
pipe_lr = make_pipeline(
StandardScaler(),
PCA(n_components=2),
LogisticRegression(
solver='liblinear',
penalty='l2',
random_state=1,
C=100.0
)
)
X_train2 = X_train[:, [4, 14]]
cv = list(StratifiedKFold(n_splits=3,
random_state=1).split(X_train, y_train))
fig = plt.figure(figsize=(7, 5))
mean_tpr = 0.0
mean_fpr = np.linspace(0, 1, 100)
all_tpr = []
for i, (train, test) in enumerate(cv):
probas = pipe_lr.fit(X_train2[train], y_train[train]).predict_proba(X_train2[test])
fpr, tpr, thresholds = roc_curve(
y_train[test],
probas[:, 1],
pos_label=1
)
mean_tpr += interp(mean_fpr, fpr, tpr)
mean_tpr[0] = 0.0
roc_auc = auc(fpr, tpr)
plt.plot(fpr,
tpr,
label='ROC fold %d (area = %0.2f)' % (i + 1, roc_auc)
)
plt.plot(
[0, 1],
[0, 1],
linestyle='--',
color=(0.6, 0.6, 0.6),
label='random guessing'
)
mean_tpr /= len(cv)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
plt.plot(mean_fpr, mean_tpr, 'k--',
label='mean ROC (area = %0.2f)' % mean_auc, lw=2)
plt.plot(
[0, 0, 1],
[0, 1, 1],
linestyle=':',
color='black',
label='perfect performance'
)
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.legend(loc="lower right")
plt.tight_layout()
plt.show()
[실행 결과]
[참고자료]
데이터분석전문가가이드 (K-Data 출판)
머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 (세바스찬 라시카, 바히드 미자리리 지음, 박해선 옮김 / 길벗 출판사)
https://rk1993.tistory.com/entry/%EB%AA%A8%EB%8D%B8-%EC%84%B1%EB%8A%A5-%ED%8F%89%EA%B0%80-%EC%A7%80%ED%91%9C-%ED%9A%8C%EA%B7%80-%EB%AA%A8%EB%8D%B8-%EB%B6%84%EB%A5%98-%EB%AA%A8%EB%8D%B8
모델 성능 평가 지표 (회귀 모델, 분류 모델)
https://m.blog.naver.com/PostView.nhn?blogId=dnjswns2280&logNo=221532535858&proxyReferer=https:%2F%2Fwww.google.co.kr%2F
[deep learning] K-Fold Cross Validation(교차검증)
https://tensorflow.blog/%EB%A8%B8%EC%8B%A0-%EB%9F%AC%EB%8B%9D%EC%9D%98-%EB%AA%A8%EB%8D%B8-%ED%8F%89%EA%B0%80%EC%99%80-%EB%AA%A8%EB%8D%B8-%EC%84%A0%ED%83%9D-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EC%84%A0%ED%83%9D-2/
머신 러닝의 모델 평가와 모델 선택, 알고리즘 선택 – 2장. 부트스트래핑과 불확실성
https://velog.io/@skyepodium/%EB%B6%84%EB%A5%98-%EB%AA%A8%EB%8D%B8-%ED%8F%89%EA%B0%80-%EB%B0%A9%EB%B2%95
댓글남기기