
[Python Deep Learning] 8. CNN Ⅱ : Case Study (LeNet ~ ResNet)

0. 개요
이번 장에서는 case study를 통해 CNN 모델이 갖는 특징들과 구조, 구현 방법, 완성된 모델 사용, 커스터마이징 등 다양한 CNN 과 관련된 내용들을 다룰 예정이다. 지금부터 다룰 CNN 모델들은 거의 대규모의 이미지들을 분류하기 위해서 였으며, 대표적으로 ImageNet의 주관하에 진행된 이미지 분석관련 대회를 통해 등장한 모델들이 많다.
1. LeNet
1) 개요
최초의 CNN이라고 불리는 모델로, 얀 르쿤(Yann LeCun)이 개발했다. 간단한 기하학적 변형과 왜곡에도 불구하고, MNIST 필기 문자를 인식하게 훈련된 모델이자, 머신러닝 모델인 Fully Connected NeuralNet 의 한계를 해결하기 위해서 개발된 모델이다.
2) 구조
LeNet의 핵심 아이디어는 최대 풀링 작업을 통해 더 낮은 계층에서 컨볼루션 연산을 교대로 수행하는 것이다. 구조는 아래 그림과 같지만, 간단하게 정리하면, 먼저 다중 특징 맵에 가중치를 공유하는 로컬 수용 필드를 기반으로 컨볼루션 작업을 수행한다. 그 다음 은닉층과 소프트 맥스를 출력 계층으로 사용하는 기존의 다층 퍼셉트론 형태의 계층을 완전 연결(Fully-Connected) 하는 것이다.
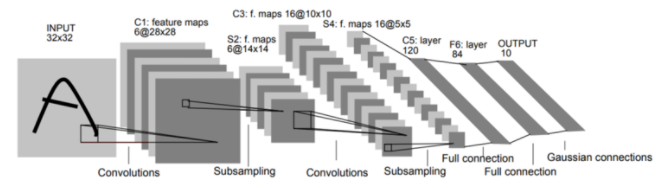
3) 구현하기
위의 그림을 Tensorflow를 이용해서 모델을 재현해보자. 먼저 작업에 필요한 모듈과 변수들에 대해 아래와 같이 정의한다.
[Python Code]
import tensorflow as tf
from tensorflow.keras import datasets, layers, models, optimizers
# 학습 변수 선언
EPOCHS = 5
BATCH_SIZE = 128
VERBOSE = 1
OPTIMIZER = optimizers.Adam()
VALIDATION_SPLIT = 0.95
IMG_ROWS, IMG_COLS = 28, 28
INPUT_SHAPE = (IMG_ROWS, IMG_COLS, 1)
CLASSES = 10
다음으로 LeNet 신경망으로 정의하자. 첫 번째 컨볼루션 작업은 ReLU 활성화와 최대 풀링이 있다. 신경망은 5 x 5 의 크기를 가진 20개의 컨볼루션 필터를 학습하며, 출력 차원은 입력 형태와 동일하기 때문에 28 x 28 이 된다.
최대 풀링 작업은 계층 위로 슬라이딩하고 세로와 가로 2픽셀 간격으로 각 영역의 최대값을 가져오는 슬라이딩 윈도우를 구현한다.
[Python Code]
# LeNet 신경망
def LeNet(input_shape, classes):
model = models.Sequential()
# CONV1 : ReLU -> Max Pooling / 5 x 5 x 20 / ReLU / input_shape
model.add(layers.Conv2D(20, (5, 5), activation='relu', input_shape=input_shape))
model.add(layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
그 다음 2번째 컨볼루션 작업은 앞선 내용과 유사하지만, 특징이 20개에서 50개로 증가했다는 점이 다르다.
[Python Code]
# CONV2 : ReLU -> Max Pooling / 5 x 5 x 50 / ReLU / input_shape
model.add(layers.Conv2D(50, (5, 5), activation='relu', input_shape=input_shape))
model.add(layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
마지막으로 Fully-Connected 계층을 선언해주면 된다. 분류하려는 클래스의 개수는 10개 이고, 소프트맥스 함수를 활성화 함수로 사용하기 때문에 아래와 같이 작성하면 된다.
[Python Code]
# FC(Fully-Connected) Layer
model.add(layers.Flatten()) # 컨볼루션 결과를 1차 행렬로 펴주는 작업
model.add(layers.Dense(500, activation='relu'))
model.add(layers.Dense(classes, activation='softmax'))
return model
이제 학습을 진행해보자. 학습에 사용할 데이터는 MNIST 필기체 이미지이며, 0 ~ 9까지 총 10개의 클래스로 구분되어 있다. 코드는 다음과 같다.
[Python Code]
# 학습하기
## 데이터 로드
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
## 전처리
### 1) 크기조정
x_train = x_train.reshape((60000, 28, 28, 1))
x_test = x_test.reshape((10000, 28, 28, 1))
### 2) 정규화
x_train, x_test = x_train/255.0, x_test/255.0
### 3) 형식 변환
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
### 4) 클래스를 이진 벡터로 변환
y_train = tf.keras.utils.to_categorical(y_train, CLASSES)
y_test = tf.keras.utils.to_categorical(y_test, CLASSES)
## 모델 초기화
model = LeNet(input_shape=INPUT_SHAPE, classes=CLASSES)
model.compile(loss="categorical_crossentropy", optimizer=OPTIMIZER, metrics=["accuracy"])
model.summary()
## 텐서보드 사용
callbacks = [tf.keras.callbacks.TensorBoard(log_dir="./logs")]
history = model.fit(
x_train, y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT,
callbacks=callbacks
)
score = model.evaluate(x_test, y_test, verbose=VERBOSE)
print("\nTest Score: ", score[0])
print("\nTest Accuracy: ", score[1])
[실행결과]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 24, 24, 20) 520
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 20) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 8, 8, 50) 25050
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 50) 0
_________________________________________________________________
flatten (Flatten) (None, 800) 0
_________________________________________________________________
dense (Dense) (None, 500) 400500
_________________________________________________________________
dense_1 (Dense) (None, 10) 5010
=================================================================
Total params: 431,080
Trainable params: 431,080
Non-trainable params: 0
_________________________________________________________________
Epoch 1/5
1/24 [>.............................] - ETA: 0s - loss: 2.3028 - accuracy: 0.1016WARNING:tensorflow:From D:\workspace\Python3\venv\lib\site-packages\tensorflow\python\ops\summary_ops_v2.py:1277: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01.
Instructions for updating:
use `tf.profiler.experimental.stop` instead.
2/24 [=>............................] - ETA: 4s - loss: 2.2870 - accuracy: 0.0898WARNING:tensorflow:Callbacks method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0050s vs `on_train_batch_end` time: 0.4135s). Check your callbacks.
24/24 [==============================] - 2s 86ms/step - loss: 1.1945 - accuracy: 0.6580 - val_loss: 0.4600 - val_accuracy: 0.8544
Epoch 2/5
24/24 [==============================] - 1s 50ms/step - loss: 0.3321 - accuracy: 0.9033 - val_loss: 0.2895 - val_accuracy: 0.9125
Epoch 3/5
24/24 [==============================] - 1s 49ms/step - loss: 0.2177 - accuracy: 0.9397 - val_loss: 0.2198 - val_accuracy: 0.9327
Epoch 4/5
24/24 [==============================] - 1s 49ms/step - loss: 0.1522 - accuracy: 0.9557 - val_loss: 0.1777 - val_accuracy: 0.9453
Epoch 5/5
24/24 [==============================] - 2s 69ms/step - loss: 0.1206 - accuracy: 0.9680 - val_loss: 0.1574 - val_accuracy: 0.9519
313/313 [==============================] - 1s 2ms/step - loss: 0.1405 - accuracy: 0.9578
Test Score: 0.14048416912555695
Test Accuracy: 0.9577999711036682
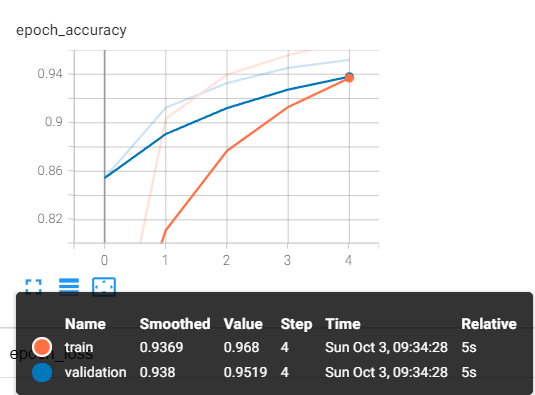
현재 5 에폭만 수행했는데 추가로 20 에폭을 수행하면, 모델의 정확도는 97%까지 향상된다.
2. AlexNet
1) 개요
가장 먼저 알아볼 모델은 2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회에서 우승을 차지했던 모델이다. 이 당시까지만 해도, 성능이 가장 좋고, 대세였던 SVM + HoG(Histograms of Oriented Gradient) 모델을 제치고, 딥러닝 기술로 최고 성능을 낼 수 있다고 증명했다는 점에서 큰 의의가 있었다. 사실 AlexNet의 전신이였던 LeNet 이 1998년도에 개발되었지만, 그 때는 하드웨어의 성능과 GPU의 병렬처리가 불가했기 때문에 크게 두각을 드러내지 못했지만, 위의 대회를 통해 좀 더 개념적으로나 구조적으로나 다듬어져서 등장했다고도 볼 수 있겠다.
AlexNet이라고 명명하게 된 계기는 해당 대회에 참석해서 제출한 논문의 저자가 Alex Khrizevsky 인데, 그의 이름을 따서 붙여진 이름이라고 한다.
2) 구조
AlexNet의 구조는 아래 그림과 같다.
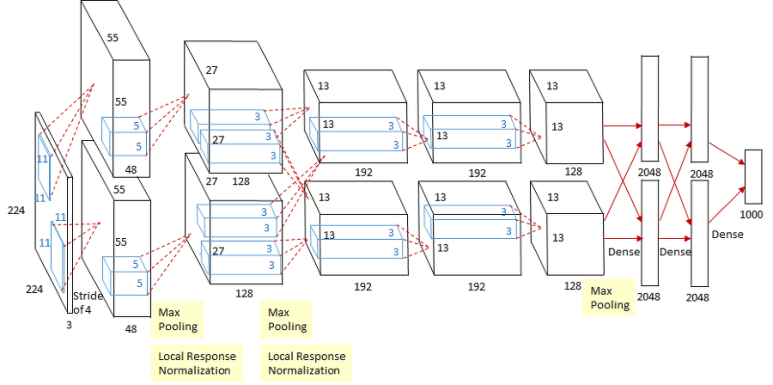
위의 그림에서 가장 눈에 띄는 점은 모델의 진행 순서를 위와 아래로 나눠 병렬적인 구조를 가졌다는 점이다. 이는 병렬 처리를 위한 분할이라고 이해하면 될 것이다.
그 외에 중요한 부분을 짚어보자면, 입력데이터는 224 x 224 크기의 RGB 이미지를 사용했다. 이를 컨볼루션 연산을 하고자 11 x 11 크기의 필터를 3개 채널에 대해 적용했으며, stride 값는 4로 주었고 패딩은 zero-padding 이다. 이러한 필터의 개수는 전체 96개이며, 연산이 완료되면, 55 x 55 인 이미지가 96개 존재하고 이를 병렬연산을 하기 위해 각 48개씩으로 분할한다.
위의 특징값에 ReLU를 적용하고, 3x3 으로 Max Pooling 을 수행했을 때, 풀링연산의 결과는 27 x 27 x 96 이 된다. 위의 과정을 반복하게 되면, 최종적으로 13 x 13 x 256 의 특징 맵이 남게 된다.
이렇게 컨볼루션 연산의 최종결과를 Flatten으로 쭉 펴준 다음, Fully Connected Layer에 입력으로 넣어주면 된다.
3) 특징
AlexNet 이 갖고 있는 가장 큰 특징으로는 활성화 함수를 ReLU 함수를 사용한다는 점이다. AlexNet이 등장하기 전까지는 인공신경망에서 활성화 함수로 Sigmoid 계열의 함수들을 사용하는 추세였지만, AlexNet에서 ReLU 계열의 함수로 학습한 결과 예측 속도는 빠르면서, 정확도는 유지되는 결과를 통해 이 후로 활성화 함수로 ReLU 계열의 함수를 사용하는 계기가 되었다.
또다른 특징은 Fully-Connected 레이어에서 과적합을 막기 위해 드롭아웃(Drop-Out) 기법을 사용하였다는 점이다. 추가적으로 훈련 시에 같은 이미지라도, 실행마다 변환하거나, 다른 위치로 crop 하는 등의 변화를 주게 되면, 과적합을 방지할 수 있다.
4) 모델 구현
AlexNet은 별도의 구현 클래스가 없기 때문에 아래 코드로 직접 구성해보았다.
[Python Code - AlexNet]
import tensorflow as tf
from tensorflow import keras as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout, BatchNormalization, Activation, Conv2D, MaxPooling2D, ZeroPadding2D
from tensorflow.keras.optimizers import SGD
import matplotlib.pyplot as plt
# AlexNet 모델 생성
model = Sequential()
## 1 계층 (conv1 - pool1 - batch1)
model.add(Conv2D(96, (11, 11), strides=4, input_shape=(224, 224, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
model.add(BatchNormalization())
## 2 계층 (conv2 - pool2 - batch2)
model.add(ZeroPadding2D(2))
model.add(Conv2D(256, (5, 5), strides=1, activation="relu"))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
model.add(BatchNormalization())
## 3 계층 (conv3 - pool3 - batch3)
model.add(ZeroPadding2D(1))
model.add(Conv2D(384, (3, 3), strides=1, activation="relu"))
## 4 계층 (conv4)
model.add(ZeroPadding2D(1))
model.add(Conv2D(384, (3, 3), strides=1, activation="relu"))
## 5 계층 (conv5 - pool5)
model.add(ZeroPadding2D(1))
model.add(Conv2D(256, (3, 3), strides=1, activation="relu"))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
## 1차원 배열로 Flatten
model.add(Flatten())
## 6 계층 (FC6)
model.add(Dense(4096, activation="relu"))
model.add(Dropout(0.5))
## 7 계층 (FC7)
model.add(Dense(4096, activation="relu"))
model.add(Dropout(0.5))
## 8 계층
model.add(Dense(1, activation='sigmoid'))
## 손실함수 정의
loss_func = SGD(lr=0.01, decay=5e-4, momentum=0.9)
model.compile(loss="binary_crossentropy", optimizer=loss_func, metrics=["accuracy"])
model.summary()
5) 성능 확인
끝으로 AlexNet의 성능을 확인해보자. 아래 그림은 AlexNet을 사용해 사진 분류를 했고, 예측 결과를 정답이 높은 순으로 상위 5개를 출력한 결과이다. 라벨 옆에 보이는 막대그래프는 해당 라벨이 정답일 확률을 표시한 것으로 보면 될 것이다.

결과를 살펴보면, 위의 4개 사진에 대해서는 분류가 잘 됬다는 것을 알 수 있다. 하지만, 아래 4개의 경우에는 예측 결과에서는 실제 라벨과 다르다는 것을 알 수 있다. 먼저 하단의 왼쪽 2개는 라벨을 예측하지는 못했지만, 상위 5개 안에는 포함되는 것을 알 수 있다. 반면 하단의 오른쪽 2개는 상위 5개 내에는 포함되어 있지 않다.
그렇다고 하단의 4개가 모두 잘못 예측 했다 보기도 어렵다. 버섯을 제외한 나머지 3개 그림의 경우를 살펴보자.
하단의 왼쪽 1번째는 그릴 보다는 컨버터블 자동차로 예측했고 실제 사진을 봐도 예측결과가 어느정도 납득이 된다. 또한 우측 2개도 체리와 마다가스카를 고양이 라고 라벨이 되어 있지만, 예측 결과로 달마시안 강아지와 여우원숭이를 본 것 또한 틀린말이 아니기 때문이다.
어찌됬든 성능상으로만 보면 Top 5 내에 라벨을 예측한 결과가 전체 8개 중 6개 이기 때문에 성능상으로도 괜찮다라고 할 수 있겠다.
3. VGGNet
1) 개요
다음으로 살펴볼 모델은 VGGNet으로 2014년, Simonyan 과 Zisserman 에 의해서 개발되었다. 해당 모델은 당시 ImageNet에서 주최한 대회인 ILSVRC(이미지넷 이미지분류 및 인식 대회)의 이미지 분류 및 위치측정부문에서 각각 2위, 1위를 기록한 모델이다. 바로 이어 구조에 대해서 좀 더 살펴보겠지만, 앞서 본 GooLeNet보다 구조적으로 간단해지고, 이해하기 쉽다.
뿐만 아니라 해당 모델은 이 후에 등장할 Inception-V2 와 Inception-V3 에서 구조의 일부가 적용되었다.
2) 구조
모델의 구조를 살펴보면서, 앞서 본 AlexNet과 어떻게 달라졌는지를 같이 살펴보도록 하자. 구조는 다음과 같다.
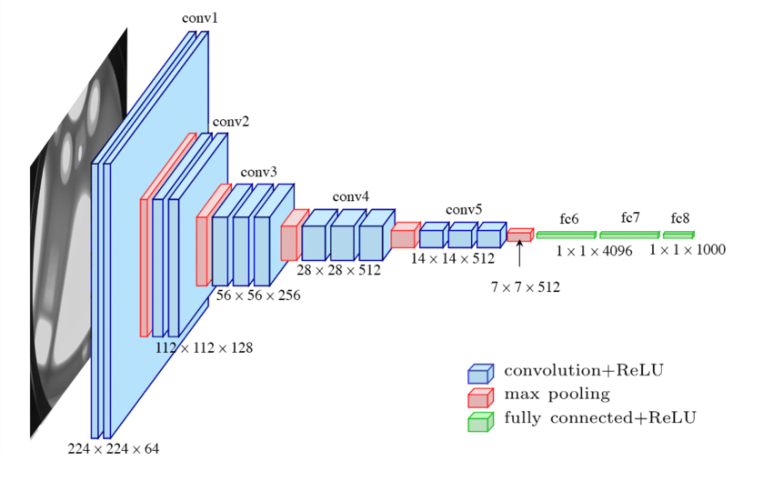
위의 그림을 통해서 알 수 있듯이, VGGNet은 이전까지 등장했던 다른 CNN 모델보다 더 깊은, 19개의 Layer를 갖고 있다. 사실 CNN의 성능은 신경망의 깊이에 영향을 많이 받는데, 이는 “Very deep convolutional networks for large-scale image recognition” 에서 나온 아래 그래프를 통해서 알 수 있다.
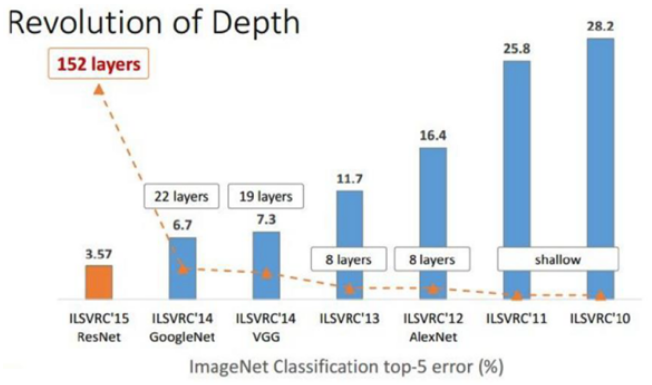
위의 그림은 ImageNet 대회 중 분류 부문에서 사용된 모델들의 오차를 막대그래프로 표현한 것이고, 사용 모델의 Layer 개수를 선으로 표현한 그래프이다. 위의 그래프에서 중요한 부분은 VGGNet 이 사용된 기점을 전후로 모델의 오차가 급격하게 낮아졌다는 점이며, 특히 2015년에 등장한 마이크로소프트의 ResNet의 경우 Layer는 152개가 쓰였지만, 그만큼 오차가 매우 낮아졌으며, 이는 신경망을 구성하는 Layer의 수가 많을 수록 좀 더 복잡한 문제를 해결할 수 있다는 결론에 도달할 수 있다.
3) 특징
그렇다면 AlexNet 과 비교했을 때, 어떤 특징들이 있는지 살펴보자. 가장 큰 차이점은 앞서 구조부분에서 말했던 모델의 계층이 8개에서 19개까지 깊어졌다는 점이다. 사실 VGGNet은 모델을 구성하는 Layer의 개수에 따라 VGG16, VGG19 등 변형된 모델이 있지만, 이들 중 가장 좋은 성능을 내기 위해서는 모델의 Layer가 16 ~ 19개 정도가 좋다.
두 번째 차이점으로는 모델에 사용된 컨볼루션 레이어는 입력에 대해 주변 값을 1씩 패딩하고, 이를 3x3 크기에 1칸씩 이동하는 Conv. 연산을 사용했으며, 풀링은 2x2 크기의 2씩 이동하는 Max Pooling 방식을 택했다. 위의 내용을 접하게 되면, 한 가지 의문이 들 것이다. 아래 그림에서처럼 “한 번에 5x5 Conv. 연산을 하면 안될까?” 이다. 하지만, 굳이 3x3을 2번 수행한 이유는 이전 기초과정에서 설명했듯이. Layer 가 많이 쌓일 수록 수용 영역(Receptive Field) 가 넓어지기 때문에, 굳이 3x3 Conv. 연산을 2번 수행하는 것이다.
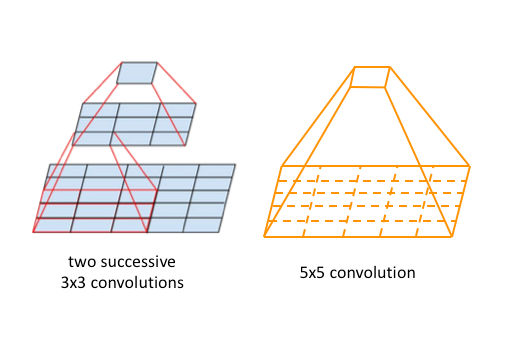
앞서 모델을 구성하는 신경망의 깊이가 깊어질 수록 오차가 확연하게 줄어드는 것을 봤다. 그만큼 신경망의 깊이가 깊어지면, 깊어질 수록 풀어야하는 문제가 비선형성을 많이 갖고있다는 것을 의미하기도한다. 때문에 복잡한 곡선일 수록, 규제를 적용해야되고, 특징을 좀 더 정확하게 찾아내야하기 때문에 2번의 필터를 거치게 된 것이다.
하지만, VGGNet에서도 결정적인 단점이 하나 존재한다. 바로 신경망을 구성하는 파라미터의 개수가 너무 많다는 점이다. 특히 AlexNet에서와 유사하게 VGGNet의 경우에도 최종단에 위치한 Fully-Connected Layer 부분 3개를 오는데 사용된 파라미터 개수만 무려 12억 2,000만개가 사용된다.
만약 우리가 VGG16 모델을 사용한다고 하면, 필요한 파라미터에 대한 메모리 소요량은 아래와 같을 것이다.

4) 모델 구현
VGGNet을 구현하려면 아래의 코드와 같이 나타낼 수 있다. 예시로 사용한 모델은 VGG16 모델이며, 예시로 분류 클래스 수는 10개로 설정했다.
[Python Code]
import tensorflow as tf
from tensorflow import keras as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout, BatchNormalization, Activation, Conv2D, MaxPooling2D, ZeroPadding2D
from tensorflow.keras.optimizers import SGD
classes = 10
## 모델 구성
model = tf.keras.models.Sequential()
## 제 1 계층
model.add(Conv2D(input_shape=(224, 224, 3), filters=64, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
## 제 2 계층
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
## 제 3 계층
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
## 제 4 계층
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
## 제 5 계층
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dense(4096, activation='relu'))
model.add(Dense(classes, activation='softmax', name='predictions'))
추가적으로 Tensorflow 2.x 버전부터는 VGGNet과 같이 사전에 학습된 모델을 함수형태로 제공해준다.
사용방법은 다음과 같다.
[Python Code]
import tensorflow as tf
from tensorflow import keras as K
model = K.applications.VGG16(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=10,
classifier_activation="softmax"
)
print(model.summary())
4. GoogLeNet
1) 개요
앞서 본 VGGNet과 같은 해인 2014년에 등장한 모델로, 당시 진행됬던 ILSVRC(이미지넷 이미지분류 및 인식 대회)에서 VGG19 모델을 제치고, 우승을 차지한 모델이다. 이름에서 알 수 있듯이, 구글의 Christian Szegedy 등에 의해 개발되었다. 해당 모델은 Inception-V1 이라고도 부르는데, 이후에 나올 Inception-V2, V3 모델의 원형이 되기 때문이며, 원조인 LeNet 을 개량해서 만들어진 모델이기도 하다.
2) 구조
GoogleNet 구조를 살펴보기 전에, 기본이 된 LeNet 구조를 다시 한 번 살펴보자.
초창기 CNN 모델인 만큼 성능은 뛰어나지 못했다. 이를 개선하기 위해서 구글에서 개발한 모델이 지금부터 살펴볼 GoogleNet이다. 자세한 구조는 다음과 같다.
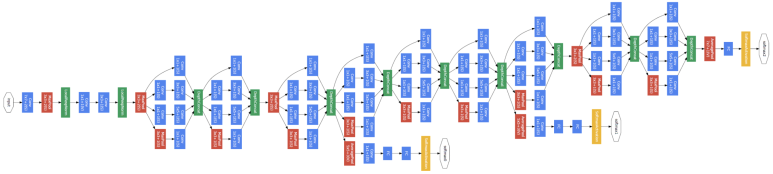
위의 구조를 자세히보면, 특정 구간이 반복되는 것을 볼 수 있다. 반복되는 구간에 해당하는 구조를 좀 더 살펴보면 아래의 사진과 같다.
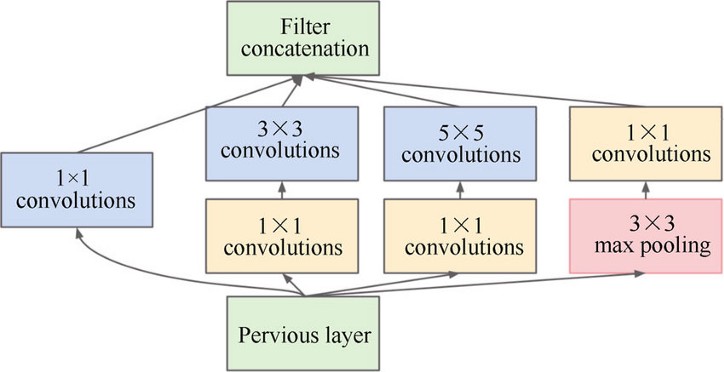
위 사진에 나온 구조가 바로 Inception 이다. 우선 Inception 구조에 대한 건 잠시 후에 다루기로 하고, 우선 GoogLeNet의 구조를 좀 더 알아보자. 이전에 본 모델들과 비교했을 때 가장 큰 차이는 Conv. 연산을 병렬적으로 수행한다는 점이다. 뿐만 아니라, 모델 구성에 사용된 Layer 수는 22개이고, 파라미터의 개수가 500만개에 달했다. 앞서 본 VGGNet이 Layer 19개에 파리미터 12억 개인 점에 비하면, 모델의 깊이는 깊지만, 파라미터 수가 적은 만큼 성능이 매우 좋은 모델이라고 할 수 있다.
앞서 VGGNet에서 본 것처럼, 일반적으로 신경망의 깊이가 깊어지게 되면, 2가지 문제점이 발생한다.
첫 번째는 망이 깊어지는 만큼, 모델을 구성하는 파라미터의 수도 증가해서, 학습 시 과대적합(Overfitting) 에 빠질 수 있다.
두 번째는 모델 구성 파라미터의 수가 커지기 때문에, 이에 대한 연산량도 커진다는 점이다.
GoogLeNet 은 위의 2가지 문제를 해결하고자 했으며, 이에 대한 결과가 바로 Inception 모듈이다.
3) Inception 모듈
Inception 구조가 나오게 된 계기는 이에 기본이 되는 지식인 NIN(Network In Network) 에 대해서 먼저 알아야 한다. 이전에 CNN 의 구조를 설명하면서, 특징 추출을 쉽게하기 위해서는 수용 영역(Reception Field)를 늘려줘야한다고 언급했다. 사실 일반적으로 Convolution Layer 자체가 수용영역에서 특징을 추출하는 능력은 뛰어나지만, 적용되는 필터의 특징이 linear 하기 때문에, non-linear 한 특성을 추출하기에는 부적합할 수 있고, 이를 극복하기 위해서는 결국 feature 의 개수를 늘려야만 했다. 때문에 수용영역에서 어떻게 하면 좀 더 feature 를 잘 추출할 수 있을지를 연구하던 중, 아래 그림과 같이 filter 대신 MLP(Multi Layer Perceptron) 을 활용해 feature 를 추출하도록 설계하게된다.
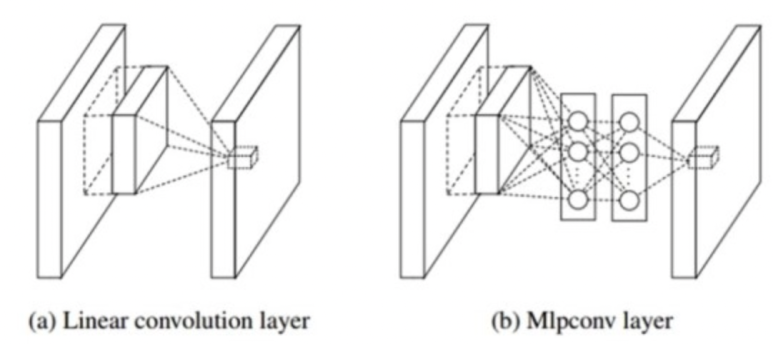
MLP 모델은 컨볼루션 레이어보다 non-linear한 성질을 잘 다루기 때문에, feature 를 추출하는 것만 비교해보자면, 컨볼루션 레이어를 쓰는 것보다 더 낫다는 것이다.
구글은 Inception 구조를 개발하면서 NIN 이론을 적극적으로 참고했다. 특히 구조를 보면 알 수 있듯이, 더 많은 feature 를 추출하기 위해 1x1, 3x3, 5x5 Conv. Layer를 병렬적으로 배치하여, 컨볼루션 연산을 병렬적으로 활용하고자 했다. 최초에는 아래그림에서 나타나듯, 위의 그림과 비교했을 때 1x1 Conv. Layer를 중간에 사용하지 않은 단순한 구조였다.
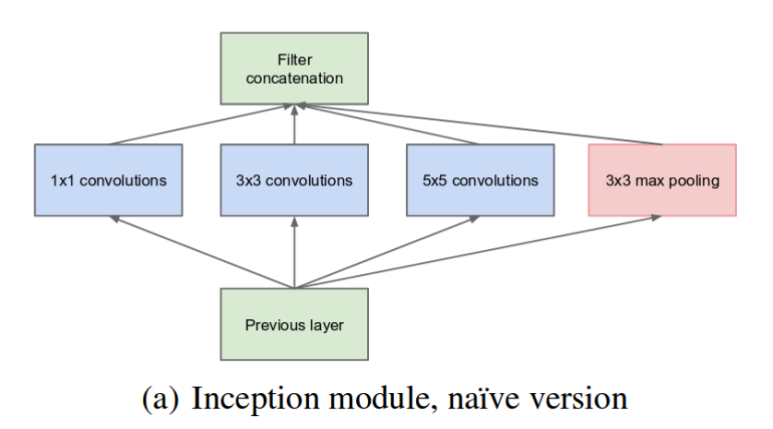
하지만, 위와 같이 생성하게되면, 다양한 크기의 특징을 추출할 수 있다는 장점이 있지만, 3x3, 5x5 Conv. Layer 부분의 연산량이 많아진다는 단점이 있다. 이를 해결하기 위해 3x3, 5x5 Conv. Layer 앞에 1x1 Conv. Layer 를 먼저 연산하도록 추가해주었다. 여기서 1x1 Conv. Layer 의 역할은 feature map 의 개수를 줄이는 역할을 하는데, 이렇게 할 경우, 여러 feature 를 추출할 수 있으면서, 연산량도 줄일 수 있는 효과를 갖는다. 결과적으로 GoogLeNet에서 모델의 깊이가 22 Layer 까지 깊어지면서, 연산량의 측면에서도 적게 소요할 수 있었다. 또한 구조적으로 CNN 의 구조를 벗어나지 않으면서, feature 를 추출하게 되었다. GoogLeNet에는 총 9개의 Inception 모듈이 사용되었다.
4) 모델 구현
위에서 살펴본 Inception 모듈을 먼저 구현하고, 이를 활용해 GoogLeNet을 어떻게 구현하는지 확인해보자.
[Python Code - Inception]
def inception(x, f_1x1, f_reduce_3x3, f_3x3, f_reduce_5x5, f_5x5, f_pool):
# 1x1
path1 = K.layers.Conv2D(f_1x1, strides=1, padding="same", activation="relu")(x)
# 3x3_reduce -> 3x3
path2 = K.layers.Conv2D(f_reduce_3x3, strides=1, padding="same", activation="relu")(x)
path2 = K.layers.Conv2D(f_3x3, strides=1, padding="same", activation="relu")(path2)
# 5x5_reduce -> 5x5
path3 = K.layers.Conv2D(f_reduce_5x5, strides=1, padding="same", acitivation="relu")(x)
path3 = K.layers.Conv2D(f_5x5, strides=1, padding="same", activation="relu")(path3)
# 3x3_max_pool -> 1x1
path4 = K.layers.MaxPooling2D(pool_size=(3,3), strides=1, padding="same")(x)
path4 = K.layers.Conv2D(f_pool, strides=1, padding="same", activation="relu")(path4)
return tf.concat([path1, path2, path3, path4], axis=3)
위의 함수에서 확인할 수 있듯이, 사용되는 필터는 총 6개가 사용되며, 각 구성요소 별 stride 는 모두 1로, 활성화함수는 ReLU 함수로 설정한다.
그렇다면 위의 함수를 사용해 GoogLeNet을 구현해보자.
[Python Code - GoogLeNet]
# GoogLeNet
input_layer = K.layers.Input(shape=(32, 32, 3))
input = K.layers.experimental.preprocessing.Resizing(224, 224, interpolation="bilinear", input_shape=x_train.shape[1:])(input_layer)
## Conv
x = K.layers.Conv2D(64, 7, strides=2, padding="same", activation="relu")(input)
## max-pool
x = K.layers.MaxPooling2D(pool_size=3, strides=2)(x)
## Conv
x = K.layers.Conv2D(64, 1, strides=1, padding="same", activation="relu")(x)
## max-pool
x = K.layers.MaxPooling2D(pool_size=3, strides=2)(x)
## inception 3a
x = inception(x, f_1x1=64, f_reduce_3x3=96, f_3x3=128, f_reduce_5x5=16, f_5x5=32, f_pool=32)
## inception 3b
x = inception(x, f_1x1=128, f_reduce_3x3=128, f_3x3=192, f_reduce_5x5=32, f_5x5=32, f_pool=32)
## max-pool
x = K.layers.MaxPooling2D(pool_size=3, strides=2)(x)
## auc 1
aux1 = K.layers.AveragePooling2D((5, 5), strides=3)(x)
aux1 = K.layers.Conv2D(128, 1, padding='same', activation='relu')(aux1)
aux1 = K.layers.Flatten()(aux1)
aux1 = K.layers.Dense(1024, activation='relu')(aux1)
aux1 = K.layers.Dropout(0.7)(aux1)
aux1 = K.layers.Dense(10, activation='softmax')(aux1)
## inception 4a
x = inception(x, f_1x1=192, f_reduce_3x3=96, f_3x3=208, f_reduce_5x5=16, f_5x5=48, f_pool=64)
## inception 4b
x = inception(x, f_1x1=160, f_reduce_3x3=112, f_3x3=224, f_reduce_5x5=24, f_5x5=64, f_pool=64)
## aux2
aux2 = K.layers.AveragePooling2D((5, 5), strides=3)(x)
aux2 = K.layers.Conv2D(128, 1, padding='same', activation='relu')(aux2)
aux2 = K.layers.Flatten()(aux2)
aux2 = K.layers.Dense(1024, activation='relu')(aux2)
aux2 = K.layers.Dropout(0.7)(aux2)
aux2 = K.layers.Dense(10, activation='softmax')(aux2)
## inception 4c
x = inception(x, f_1x1=128, f_reduce_3x3=128, f_3x3=256, f_reduce_5x5=24, f_5x5=64, f_pool=64)
## inception 4d
x = inception(x, f_1x1=112, f_reduce_3x3=144, f_3x3=288, f_reduce_5x5=32, f_5x5=64, f_pool=64)
## inception 4e
x = inception(x, f_1x1=256, f_reduce_3x3=160, f_3x3=320, f_reduce_5x5=32, f_5x5=128, f_pool=128)
## aux3
aux3 = K.layers.AveragePooling2D((5, 5), strides=3)(x)
aux3 = K.layers.Conv2D(128, 1, padding='same', activation='relu')(aux3)
aux3 = K.layers.Flatten()(aux3)
aux3 = K.layers.Dense(1024, activation='relu')(aux3)
aux3 = K.layers.Dropout(0.7)(aux3)
aux3 = K.layers.Dense(10, activation='softmax')(aux3)
## max-pool
x = K.layers.MaxPooling2D(pool_size=3, strides=2)(x)
## inception 5a
x = inception(x, f_1x1=256, f_reduce_3x3=160, f_3x3=320, f_reduce_5x5=32, f_5x5=128, f_pool=128)
## inception 5b
x = inception(x, f_1x1=384, f_reduce_3x3=192, f_3x3=384, f_reduce_5x5=48, f_5x5=128, f_pool=128)
## avg pool
x = K.layers.GlobalAveragePooling2D()(x)
## drop-out (40%)
x = K.layers.Dropout(0.4)(x)
## linear & softmax
out = K.layers.Dense(10, activation='softmax')(x)
model = K.Model(inputs=input_layer, outputs=[out, aux1, aux2])
model.compile(optimizer='adam',
loss=[K.losses.sparse_categorical_crossentropy,
K.losses.sparse_categorical_crossentropy,
K.losses.sparse_categorical_crossentropy],
loss_weights=[1, 0.3, 0.3],
metrics=['accuracy'])
history = model.fit(x_train, [y_train, y_train, y_train], validation_data=(x_val, [y_val, y_val, y_val]), batch_size=64, epochs=40)
위의 내용처럼 인셉션 구조를 활용해서 GoogLeNet을 구현할 수 있으며, 이후에 Inception V2, V3 로 개선된다.
V2, V3에서는 기존 GoogLeNet에서 사용된 파라미터 수를 개선하기 위한 과정으로 아래와 같이 필터를 배치하게 된다.
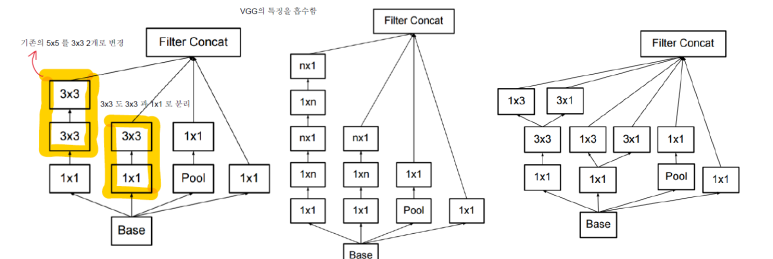
위의 그림에서 가장 왼쪽에 위치한 구조를 사용할 경우에, 기존의 5x5 필터를 3x3 필터 2개로 바꿔줬으며, 마찬가지로, 7x7 필터의 경우에는 3x3 필터 3개로 변경하였으며, 이럴 경우 사용된 파라미터 수가 45% 정도 줄일 수 있다. 위와 같은 기법을 가리켜, 인수분해(Factorization) 이라고 한다.
단, 인수분해를 반드시 7x7 이나 5x5 필터를 3x3 필터로 바꿔줄 필요는 없다. 필요에 따라 1x3 필터나 3x1 필터로 바꿔서도 적용할 수 있다.
위의 내용을 좀 더 일반화 시켜보자면, 1xn 필터 혹은 nx1 필터로 인수분해를 적용할 수 있으며, n 의 값이 커질수록, 모델에 사용되는 파라미터 수를 줄일 수 있다.결과적으로, 위와 같은 개선사항을 반영해서 이후에 Inception V2, V3 모델이 생성된다.
5. ResNet
1) 배경
마지막으로 ResNet에 대해서 알아보도록 하자. ResNet은 2015년 마이크로소프트에서 개발되었으며, ILSVRC에서 우승을 차지한 알고리즘이다.
우선, ResNet에 대해서 알아보기전에, 딥러닝에 사용되는 신경망의 깊어지면 어떻게 되는지 배경을 먼저 알아보자. 앞서 VGGNet에서 언급했던것처럼 19 개 이상 레이어를 구성하게 되면 아래와 같은 결과를 얻을 수 있다.
아래 예시에서는 20개 레이어를 사용한 것과 56개 레이어를 사용한 모델을 비교한 것이다.
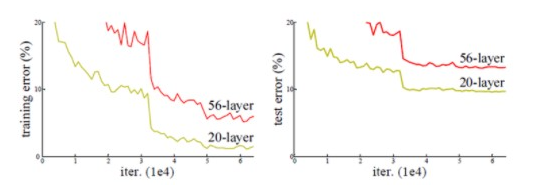
그래프에서 볼 수 있듯이, 레이어 수가 많을 수록, 오차는 높아지고, 성능이 떨어지는 것을 볼 수 있다. 위와 같은 현상이 발생하는 이유는 신경망이 깊어질 수록 Gradient Vanishing/Exploding 현상이 발생할 수 있다.
하지만, 이후에 보게될 ResNet의 경우에는 레이어 수를 최초에는 152개까지 늘렸고, 이 후에는 1,001개 까지 늘려서 설계하게된다. 그렇다면 어떤 방식으로 Gradient Vanishing/Exploding을 방지한 것일까?
2) 구조
일반적으로 우리가 알고있는 CNN의 구조는 다음과 같다.
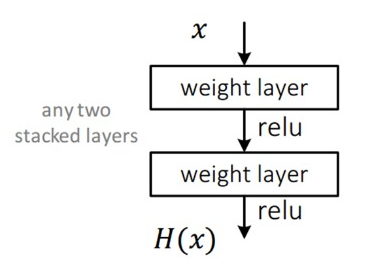
입력 x 를 받아 2개의 가중치가 적용된 레이어를 거쳐, 출력 H(x)를 내고, 출력된 결과는 다음 레이어의 입력으로 사용되는 구조이다. 하지만 ResNet의 구조는 layer의 입력을 출력으로 바로 연결하는 Skip Connection 을 적용하였다. 구체적인 구조는 다음과 같다.
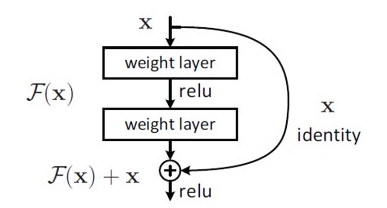
위와 같은 구조를 갖기 때문에, 이전과 달리 출력되는 결과는 F(x) + x 를 한 결과가 되어 다음 레이어의 입력으로 사용된다. 그림상으로는 굉장히 단순한 구조지만, 기존 신경망들은 H(x) 값을 얻기 위해 학습하는 것과 달리, F(x) 값이 0이 되는 방향으로 학습한다.
위의 구조 및 수식에서 F(x) = H(x) - x 가 되며, 결과적으로 잔차(residual) 을 학습하는 것으로 볼 수 있다. 또한 x 가 그대로 skip connection 으로 출력 결과에 반영되기 때문에, 연산량은 증가하지 않으며, F(x) 가 몇 개의 레이어를 포함할 지도 선택이 가능하기 때문에, Fully Connection 레이어 이외에 Convolution 레이어도 추가 가능하다.
그렇다면 실제 ResNet 구조는 어떻게 생겼을지 아래 그림을 통해서 살펴보자.
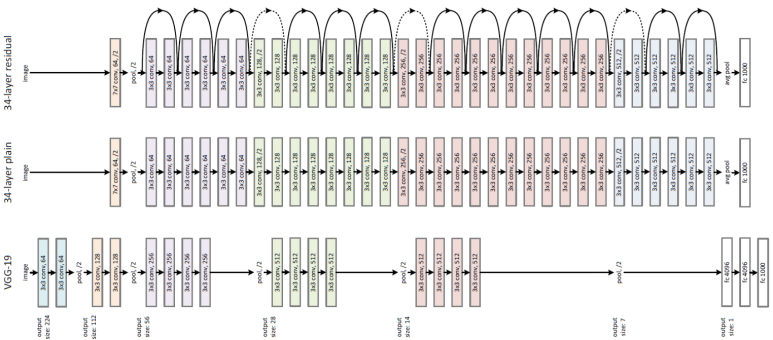
위의 그림에서 나온 것처럼, ResNet은 VGG-19 모델을 기반으로 제작되었다. 여기에 컨볼루션 레이어를 여러 개 추가해서 위의 그림 중 가운데에 있는 Plain Net이 생성된다. 그림이 작아 잘 안보일 수 있지만, 처음을 제외하고 전부 3x3 컨볼루션 레이어를 사용한다. 또한 특징 맵의 크기가 반으로 줄어들면, 특성 맵의 두께는 2배로 늘어난다.
좀 더 자세하게 표현하면 아래 그림과 같이 구성된다고 할 수 있겠다.
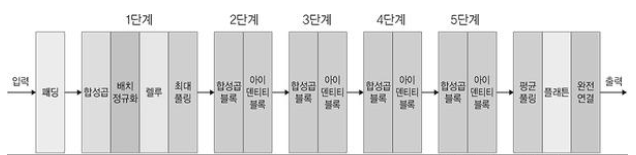
위의 그림을 통해서 알 수 있듯이, 1단계에서만 컨볼루션과 배치정규화 등의 작업을 수행하고 이후에는 컨볼루션 계층과 숏컷을 추가하는 것으로 구성된다.
하지만, 논문을 통해서 알 수 있듯이, 신경망이 깊어질 수록 오차가 커지는 문제는 아직 해결되지 않았다.
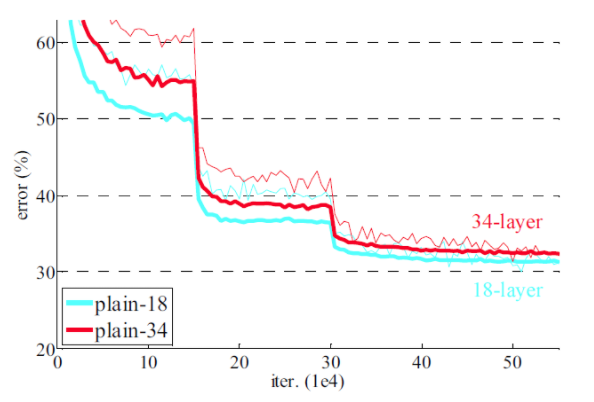
이를 위해 앞서 본 skip connection 만들어서 처리한 ResNet 이 완성되었다. 최종적으로 생성한 ResNet의 성능을 비교하면 다음과 같다.
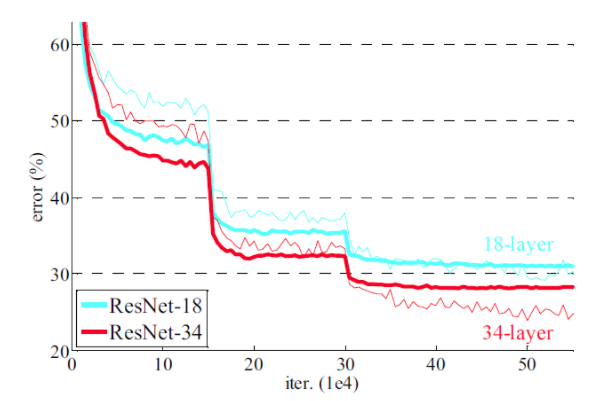
그림을 통해서 알 수 있듯이, 신경망의 깊이가 깊더라도, 오차는 오히려 감소한다는 것을 알 수 있으며, 이러한 현상은 skip connection 구조 (bottleneck 구조라고도 함)로 인한 성능개선이라고 볼 수 있겠다.
3) 모델 구현
앞서 살펴 본 ResNet을 직접 구현해보자. 좀 더 쉽게 구현하기 위해서 먼저 Residual Unit 클래스부터 생성해보자.
[Python Code - Residual Module]
class ResidualUnit(tf.keras.Model):
def __init__(self, filter_in, filter_out, kernel_size):
super(ResidualUnit, self).__init__()
self.batch_norm1 = tf.keras.layers.BatchNormalization()
self.conv1 = tf.keras.layers.Conv2D(filter_out, kernel_size, padding="same")
self.batch_norm2 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv2D(filter_out, kernel_size, padding="same")
if filter_in == filter_out:
self.identity = lambda x: x
else:
self.identity = tf.keras.layers.Conv2D(filter_out, (1, 1), padding="same")
def call(self, x, training=False, mask=None):
h = self.batch_norm1(x, training=training)
h = self.nn.relu(h)
h = self.conv1(h)
h = self.batch_norm2(h, training=training)
h = tf.nn.relu(h)
h = self.conv2(h)
return self.identity(x) + h
위의 코드에서 중요한 부분은 identity 부분을 정의하는 것이다. 구조를 잘 보면 입력값을 마지막에 한 번 더 연산 결과와 더해서 반영한다. 때문에 call 함수의 return 부분에서 결과에 입력값인 x 를 한번 더 더해주는 것이다.
끝으로, 위의 모듈을 사용해서 간단한 ResNet 모델을 만들어보자.
[Python Code]
class ResNet(tf.keras.Model):
def __init__(self):
super(ResNet, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(8, (3,3), padding="same", activation="relu") # 28 X 28 X 8
self.res1 = ResnetLayer(8, (16, 16), (3, 3)) # 28 X 28 X 16
self.pool1 = tf.keras.layers.MaxPool2D((2,2)) # 14 X 14 X 16
self.res2 = ResnetLayer(16, (32, 32), (3, 3)) # 14 X 14 X 32
self.pool2 = tf.keras.layers.MaxPool2D((2,2)) # 7 X 7 X 32
self.res3 = ResnetLayer(32, (64, 64), (3, 3)) # 7 X 7 X 64
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(128, activation="relu")
self.dense2 = tf.keras.layers.Dense(10, activation="softmax")
def call(self, x, training=False, mask=None):
x = self.conv1(x)
x = self.res1(x, training=training)
x = self.pool1(x)
x = self.res2(x, training=training)
x = self.pool2(x)
x = self.res3(x, training=training)
x = self.flatten(x)
x = self.dense1(x)
return self.dense2(x)
[참고자료]
딥러닝 텐서플로 교과서(서지영 지음, 길벗출판사)
http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9791165215477
[Part Ⅴ. Best CNN Architecture] 6. VGGNet
https://blog.naver.com/laonple/220738560542
댓글남기기