
[Python Deep Learning] 3. 분류 (Classification)

1. 분류
회귀와 더불어 머신러닝에서부터 가장 기초적인 데이터 분석 방법 중 하나이다. 분류란, 데이터가 어느 범주에 속하는지를 판단하는 문제이며, 유사한 것들을 하나의 클래스로 묶어주는 작업이 대표적인 예시라고 볼 수 있다.
학습 방법에 대해서는 데이터와 그에 대응되는 클래스 혹은 라벨이 부여되고, 데이터에 대한 정답이 있기 때문에 지도학습 방법으로 분류된다.
2. 이진 분류(Binary Classification)
먼저 살펴볼 이진 분류는 말 그대로, 예/아니오 와 같이 정답의 범주가 2개인 분류 문제를 의미한다. 사실 분류 알고리즘이 나오기전에는 회귀를 이용해서 분류를 진행했다. 하지만, 데이터가 비선형으로 분포하는 경우에 이를 정확하게 분류를 할 수 있는 직선 회귀식이 없었으며, 이를 위해 로지스틱 회귀, 의사결정나무 등 머신러닝에서 살펴본 알고리즘들이 등장하게 된다.
해당 알고리즘들은 머신러닝에서 다뤄봤기 때문에 이번장에서는 텐서플로를 활용한 이진분류를 진행해보자. 예시를 위해 캘리포니아 어바인 대학에서 제공하는 와인데이터를 사용한다. 본래 해당 데이터는 12개의 속성들을 이용해서 와인의 품질을 예측하는 데이터이며, 레드와인과 화이트 와인이 별도의 데이터셋으로 나눠져있다.
이번 예제에서는 레드와인인 것과 화이트 와인인 것에 별도의 컬럼에 표시를 해두고 이를 예측하는 모델을 생성해보자.
먼저 필요한 라이브러리들을 임포트하고, 데이터를 로드한다. 코드는 다음과 같다.
[Python Code]
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
red = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep=";")
white = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep=";")
print(red.head())
print(white.head())
다음으로 각 데이터에 type 이라는 신규컬럼을 생성하고, 레드와인은 0, 화이트와인은 1로 라벨링한다. 이 후, 레드와인과 화이트와인을 하나의 변수인 wine 으로 통합한다.
[Python Code]
red['type'] = 0
white['type'] = 1
wine = pd.concat([red, white])
print(wine.describe)
[실행결과]
<bound method NDFrame.describe of fixed acidity volatile acidity citric acid ... quality type type]
0 7.4 0.70 0.00 ... 5 0.0 NaN
1 7.8 0.88 0.00 ... 5 0.0 NaN
2 7.8 0.76 0.04 ... 5 0.0 NaN
3 11.2 0.28 0.56 ... 6 0.0 NaN
4 7.4 0.70 0.00 ... 5 0.0 NaN
... ... ... ... ... ... ...
4893 6.2 0.21 0.29 ... 6 NaN 1.0
4894 6.6 0.32 0.36 ... 5 NaN 1.0
4895 6.5 0.24 0.19 ... 6 NaN 1.0
4896 5.5 0.29 0.30 ... 7 NaN 1.0
4897 6.0 0.21 0.38 ... 6 NaN 1.0
[6497 rows x 14 columns]>
새로운 속성을 추가하는 방법은 딕셔너리 타입에서처럼 새로운 속성과 그에 대한 값을 직접 지정해주면 된다. 정확하게 라벨링이 됬는지 확인하기 위해 아래의 시각화를 통해 살펴보도록하자.
[Python Code]
plt.hist(wine['type'])
plt.xticks([0, 1])
plt.show()
print(wine['type'].value_counts())
[실행결과]
1 4898
0 1599
Name: type, dtype: int64
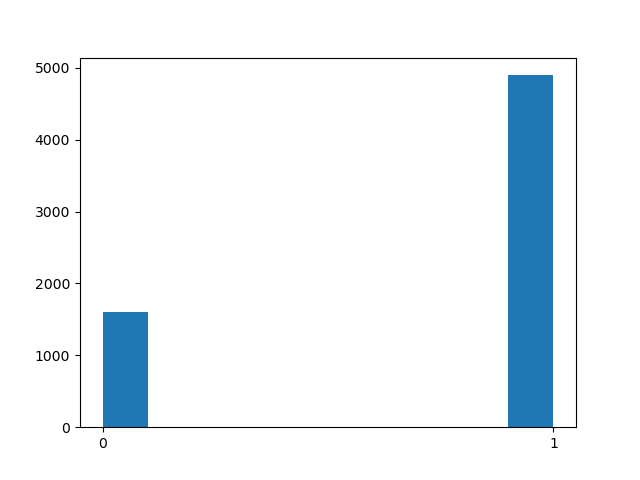
코드와 위의 시각화 결과를 살펴보면 알 수 있듯이, wine 데이터의 type 컬럼에는 0 과 1밖에 없다. 때문에 x 축의 최소값은 0, 최대값은 1이 되도록 표시했고 추가적으로 value_counts() 메소드를 통해 각 라벨에 해당하는 데이터의 수를 확인해봤다.
이번에는 wine 변수의 구성을 확인하기 위해 아래와 같이 info() 메소드를 실행해서, 새부적은 컬럼들과 각 컬럼별 데이터 타입들도 살펴보자.
[Python Code]
wine.info()
[실행결과]
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6497 entries, 0 to 4897
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 fixed acidity 6497 non-null float64
1 volatile acidity 6497 non-null float64
2 citric acid 6497 non-null float64
3 residual sugar 6497 non-null float64
4 chlorides 6497 non-null float64
5 free sulfur dioxide 6497 non-null float64
6 total sulfur dioxide 6497 non-null float64
7 density 6497 non-null float64
8 pH 6497 non-null float64
9 sulphates 6497 non-null float64
10 alcohol 6497 non-null float64
11 quality 6497 non-null int64
12 type 6497 non-null int64
13 type] 4898 non-null float64
dtypes: float64(12), int64(2)
memory usage: 761.4 KB
None
info() 를 통해서 각 컬럼별 데이터 타입을 확인한 이유는 지금부터 진행할 정규화 과정과 연관이 있다. 앞서 describe() 메소드와 head() 메소드로 각 컬럼별 값을 확인해봤을 때, 최소값과 최대값이 서로 다르다는 것도 확인할 수 있었다. 원본의 데이터 그대로를 사용해 학습을 하는 것도 가능하지만, 원본을 사용하기 때문에 오차가 더 크게 발생할 수도 있다. 따라서 데이터의 표기형식을 일정한 비율로 나타내도록 가공해주는 정규화 작업이 필요한데, 해당 과정은 수치형 변수에 한해서만 수행이 가능하다.
때문에 정규화 과정을 하기에 앞서, 데이터 내에 수치형 변수의 유무와 어떤 컬럼을 정규화할지를 정해야한다.
이번 예제의 경우 전체적으로 정규화를 적용할 예정이며, 최소값과 최대값을 활용하는 Min-Max 정규화를 진행할 예정이다. 방법은 다음과 같다.
[Python Code]
wine_norm = (wine - wine.min()) / (wine.max() - wine.min())
print(wine_norm.head())
print(wine_norm.describe())
[실행결과]
fixed acidity volatile acidity citric acid ... quality type type]
0 0.297521 0.413333 0.000000 ... 0.333333 0.0 NaN
1 0.330579 0.533333 0.000000 ... 0.333333 0.0 NaN
2 0.330579 0.453333 0.024096 ... 0.333333 0.0 NaN
3 0.611570 0.133333 0.337349 ... 0.500000 0.0 NaN
4 0.297521 0.413333 0.000000 ... 0.333333 0.0 NaN
[5 rows x 14 columns]
fixed acidity volatile acidity ... type type]
count 6497.000000 6497.000000 ... 6497.000000 0.0
mean 0.282257 0.173111 ... 0.753886 NaN
std 0.107143 0.109758 ... 0.430779 NaN
min 0.000000 0.000000 ... 0.000000 NaN
25% 0.214876 0.100000 ... 1.000000 NaN
50% 0.264463 0.140000 ... 1.000000 NaN
75% 0.322314 0.213333 ... 1.000000 NaN
max 1.000000 1.000000 ... 1.000000 NaN
[8 rows x 14 columns]
실행결과를 통해서 알 수 있듯이, 정규화 수행 전에는 최소값과 최대값이 각 컬럼마다 차이가 컸지만, 정규화를 해줌으로써, 0 ~ 1 사이의 값으로 변환되었다는 것을 알 수 있다.
이렇게 정규화된 데이터를 가지고, 학습을 시키기 위해 랜덤하게 셔플링 해준 후, numpy array 형식으로 바꿔준다.
[Python Code]
## 셔플링
wine_shuffle = wine_norm.sample(frac=1)
print(wine_shuffle.head())
## numpy array로 변환
wine_array = wine_shuffle.to_numpy()
print(wine_array[:5])
[실행결과]
fixed acidity volatile acidity citric acid ... quality type type]
1481 0.363636 0.133333 0.361446 ... 0.333333 0.0 NaN
3565 0.347107 0.113333 0.162651 ... 0.500000 1.0 NaN
2944 0.272727 0.140000 0.204819 ... 0.500000 1.0 NaN
387 0.206612 0.206667 0.210843 ... 0.333333 1.0 NaN
1448 0.256198 0.333333 0.006024 ... 0.333333 0.0 NaN
[[0.36363636 0.13333333 0.36144578 0.03680982 0.15780731 0.03125
0.03686636 0.21534606 0.51937984 0.25842697 0.37681159 0.33333333
0. nan]
[0.34710744 0.11333333 0.1626506 0.13957055 0.0448505 0.04861111
0.18202765 0.13398882 0.20930233 0.07865169 0.46376812 0.5
1. nan]
[0.27272727 0.14 0.20481928 0.11042945 0.0448505 0.16666667
0.28110599 0.13225371 0.37984496 0.1011236 0.39130435 0.5
1. nan]
[0.20661157 0.20666667 0.21084337 0.08128834 0.05149502 0.28298611
0.58525346 0.13475998 0.31007752 0.24719101 0.30434783 0.33333333
1. nan]
[0.25619835 0.33333333 0.0060241 0.01993865 0.1179402 0.13541667
0.11059908 0.18739156 0.52713178 0.28651685 0.24637681 0.33333333
0. nan]]
셔플링까지 완료되었기 때문에, 이번에는 전체 데이터를 대상으로 학습용 데이터와 테스트용 데이터로 분할하는 작업을 진행한다. 이번 예시에서는 학습데이터 : 테스트 데이터 = 8 : 2 비중으로 분리한다.
[Python Code]
train_idx = int(len(wine_array) * 0.8)
x_train, y_train = wine_array[:train_idx, :-1], wine_array[:train_idx, -1]
x_test, y_test = wine_array[train_idx:, :-1], wine_array[train_idx:, -1]
위의 코드에서는 먼저 전체 데이터 중 80%에 위치하는 데이터의 행 번호를 계산하고, 학습용 데이터는 시작부터 (80%에 대한 행번호 - 1)까지, 테스트용 데이터는 80%에 대한 행 번호 부터 끝까지로 잡아주면 된다.
그리고 사용되는 속성 중 예측해야되는 컬럼은 가장 끝에 위치하기 때문에 -1로 슬라이싱해주면 제일 끝 이전까지는 속성인 feature 로, 제일 마지막에 위치한 type 부분만 라벨로 사용된다.
이렇게 학습용 데이터와 테스트용 데이터, 그리고 속성과 라벨로 분리하는 작업까지 마무리했다. 이제 학습하기 직전에 분류문제에서 모델이 라벨을 이해하기 쉽도록 변환하는 작업인 One-Hot Encoding 을 해줄 것이다. 여러가지 방법이 있지만, 지금 살펴볼 One-Hot Encoding 은 정답에 해당하는 인덱스의 값에는 1, 나머지 인덱스에는 0으로 채워주는 방식이다.
예시의 경우 0인 경우에는 [1 0]으로, 1인 경우에는 [0 1]로 바꿔줄 것이다.
[Python Code]
y_train = tf.keras.utils.to_categorical(y_train, num_classes=2)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=2)
print(y_train[0])
print(y_test[0])
[실행결과]
[1. 0.]
[1. 0.]
이제 학습을 위한 데이터의 준비는 끝났으며, 본격적으로 모델링 작업을 진행해보자.
[Python Code]
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(lr=0.07),
loss='categorical_crossentropy',
metrics=['accuracy']
)
print(model.summary())
[실행결과]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 48) 624
_________________________________________________________________
dense_1 (Dense) (None, 24) 1176
_________________________________________________________________
dense_2 (Dense) (None, 12) 300
_________________________________________________________________
dense_3 (Dense) (None, 2) 26
=================================================================
Total params: 2,126
Trainable params: 2,126
Non-trainable params: 0
_________________________________________________________________
None
모델은 크게 입력층 - 은닉층 x2 - 출력층 으로 구성되어있다. 구조를 좀 더 살펴보자면, 먼저 입력층에는 속성값 12개가 모두 한번에 들어오기 때문에 input_shape 옵션으로 (12,) 이라고 설정했다. 다음으로 출력층을 제외한 각 층 별로는 ReLU함수를 활성화함수로 사용했고, 마지막 출력층의 경우에만 SoftMax 함수를 사용해서 최종결과를 생성했다.
모델구조를 디자인한 다음에는 모델이 어떻게 학습할 지를 설정해줘야한다. 이 부분이 그다음에 등장하는 model.compile() 부분이며, 에제에서는 Adam 최적화 알고리즘을 사용했고 손실함수는 크로스 엔트로피 방식을 적용했으며, 모델에 대한 성능 확인 지표는 accuracy를 사용했다.
해당 내용은 model.summary() 메소드를 사용하면 결과를 확인할 수 있다.해당 내용에 대해서는 다음장에서 다룰 신경망 학습과 관련해서 자세히 다룰 예정이다. 이번 장에서는 모델을 설계하는 대략적인 흐름에 대해서만 알고 넘어가자. 여기까지 완료가 됬다면, 학습을 위한 모델의 설계가 마무리된 것이다.
마지막으로 모델에 대한 학습과 성능평가를 수행해보자. 먼저 모델에 대한 학습은 fit() 메소드로 실행시킨다. 학습 결과에 대한 기록을 원한다면, 코드에서처럼 별도의 변수에 대입시키면된다. 이를 아래의 시각화로 표현해줄 수도 있다.
[Python Code]
## 학습하기
history = model.fit(x_train, y_train, epochs=25, batch_size=32, validation_split=0.25)
## 성능 확인
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epochs')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k--', label='val_acc')
plt.xlabel('Epochs')
plt.ylim(0.5, 1)
plt.legend()
plt.show()
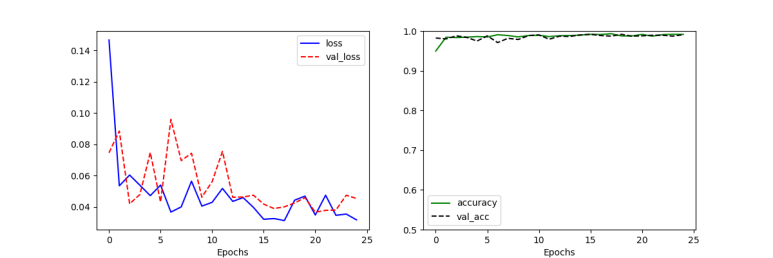
모델성능에 대한 시각화를 살펴보면, 정확도는 거의 98%정도이고, 오차(손실)도 0.1 이하인 것을 확인할 수 있다.
끝으로 테스트데이터를 활용해서 예측값 까지 출력해보자. 모델의 예측결과는 predict() 메소드를 사용하면 되며, 해당 예제의 경우 분류 문제이기 때문에, 예측 결과는 각 라벨에 해당하는 확률이 나오게 된다. 이를 하나의 값으로 만들어 주기 위해 argmax() 함수를 사용해서 최종결과를 만들어주면 된다.
[Python Code]
y_pred = np.argmax(model.predict(x_test), axis=1)
print(y_pred)
[실행결과]
[0 1 1 ... 1 0 1]
3. 다중분류
앞서 본 이진분류는 정답지가 2개인 문제였다면, 다중 분류는 정답지가 2개 이상인 분류문제를 의미한다. 때문에 과정 역시 앞서 본 이진 분류의 확장이라고 할 수 있으며, 이를 예제와 같이 살펴보자. 이번 예제는 앞서 다뤘던 와인 데이터의 목적인 와인 별 품질등급을 예측하는 모델을 만들어보자.
데이터 로드하는 부분은 이전과 동일하기때문에 생략하도록 하겠다. 데이터 로드가 완료되었다면, 예측변수인 quality 변수의 값을 확인해보자.
[Python Code]
wine = pd.concat([red, white])
print(wine.describe())
print(wine["quality"].value_counts())
[실행결과]
fixed acidity volatile acidity ... alcohol quality
count 6497.000000 6497.000000 ... 6497.000000 6497.000000
mean 7.215307 0.339666 ... 10.491801 5.818378
std 1.296434 0.164636 ... 1.192712 0.873255
min 3.800000 0.080000 ... 8.000000 3.000000
25% 6.400000 0.230000 ... 9.500000 5.000000
50% 7.000000 0.290000 ... 10.300000 6.000000
75% 7.700000 0.400000 ... 11.300000 6.000000
max 15.900000 1.580000 ... 14.900000 9.000000
[8 rows x 12 columns]
6 2836
5 2138
7 1079
4 216
8 193
3 30
9 5
Name: quality, dtype: int64
위의 결과에서처럼 총 7개의 분류가 존재한다. 이처럼 데이터의 양도 작고 범주 수가 많으면, 세세한 분류가 어려워지기 때문에 범주 수를 조금 더 줄일 예정이다. 크게 3가지 등급으로 다시 분류하며 3~5사이는 0, 6은 1, 7 이상은 2로 분류한다.
[Python Code]
wine.loc[wine['quality'] <= 5, 'new_quality'] = 0
wine.loc[wine['quality'] == 6, 'new_quality'] = 1
wine.loc[wine['quality'] >= 7, 'new_quality'] = 2
print(wine.describe())
print(wine["new_quality"].value_counts())
[실행결과]
fixed acidity volatile acidity ... quality new_quality
count 6497.000000 6497.000000 ... 6497.000000 6497.000000
mean 7.215307 0.339666 ... 5.818378 0.829614
std 1.296434 0.164636 ... 0.873255 0.731124
min 3.800000 0.080000 ... 3.000000 0.000000
25% 6.400000 0.230000 ... 5.000000 0.000000
50% 7.000000 0.290000 ... 6.000000 1.000000
75% 7.700000 0.400000 ... 6.000000 1.000000
max 15.900000 1.580000 ... 9.000000 2.000000
[8 rows x 13 columns]
1.0 2836
0.0 2384
2.0 1277
Name: new_quality, dtype: int64
이제 학습을 위한 정규화 및 데이터 셋을 생성하도록 하자 과정은 이전과 동일하다. 또한 학습은 새로 만든 품질 등급으로 학습시킬 예정이므로 기존의 quality 변수는 제거하도록 한다.
[Python Code]
del wine['quality']
wine_norm = (wine - wine.min()) / (wine.max() - wine.min())
wine_shuffle = wine_norm.sample(frac=1)
wine_array = wine_shuffle.to_numpy()
train_idx = int(len(wine_array) * 0.8)
x_train, y_train = wine_array[:train_idx, :-1], wine_array[:train_idx, -1]
x_test, y_test = wine_array[train_idx:, :-1], wine_array[train_idx:, -1]
y_train = tf.keras.utils.to_categorical(y_train, num_classes=3)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=3)
학습에 사용할 모델은 이전 예제와 동일한 모델로 세팅한다. 학습은 총 25회 실행하고, 배치 1회 당 데이터에서 32만큼 사용하도록 설정한다.
[Python Code]
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=48, activation='relu', input_shape=(12,)),
tf.keras.layers.Dense(units=24, activation='relu'),
tf.keras.layers.Dense(units=12, activation='relu'),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(lr=0.07),
loss='categorical_crossentropy',
metrics=['accuracy']
)
history = model.fit(x_train, y_train, epochs=25, batch_size=32, validation_split=0.25)
위의 모델에 대한 성능은 아래와 같이 확인할 수 있었다.
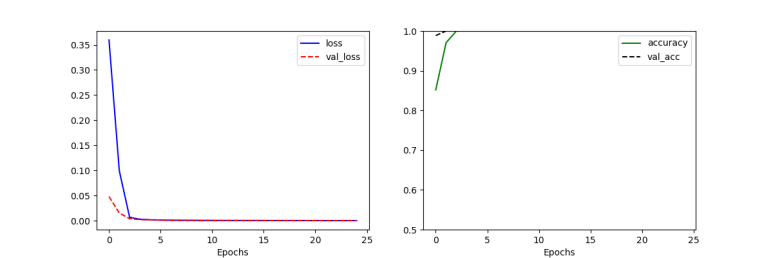
그래프를 보면 알 수 있듯이, 학습이 꽤 잘됬으며, 클래스 수가 적었기 때문에 학습이 완벽하게 됬다라고 볼 수 있다. 이런 식으로 분류와 앞서 본 회귀 문제에 대해서도 신경망을 사용해서 문제를 해결할 수 있다는 것을 확인할 수 있었다.
댓글남기기