
[Python Deep Learning] 16. 단어를 표현하는 방법: Word2Vec

1. 토큰에 대한 표현방법
앞서 우리는 자연어 처리 영역에서 사용되는 기본적인 통계 모델과 RNN, LSTM 에 대해서 다뤄봤다. 하지만, 단순하게 모델만 알고 있다고 해서 우리가 일상 생활에서 사용하는 언어, ‘자연어’를 기계가 그대로 이해하도록 학습 시킬 수는 없다. 따라서 컴퓨터가 이해하도록 하기 위해 최소 단위로 나눠주고, 이를 숫자 형태로 변환하는 방법에 대해서 알아볼 예정이다.
2. 토큰화 (Tokenization)
먼저, 토큰(Token)에 대해서 알아보자. 자연어처리에서 크롤링 등을 통해 얻어낸 결과는 가공되지 않은 자연어 상태이며, 이를 코퍼스(Corpus) 데이터 라고 부른다. 그리고 이러한 코퍼스 데이터에서 용도에 맞게 정제 및 가공, 정규화 등의 과정을 거쳐 나온 의미있는 단어들을 가리켜, 토큰이라고 부르며, 이렇게 코퍼스에서 토큰을 추출하는 일련의 과정을 가리켜 토큰화(Tokenization) 이라고 부른다. 예를 들어 아래의 문장에서 구두점과 같은 문자를 제외하고 단어 토큰화 작업을 하게 되면, 다음과 같이 결과가 나올 것이다.
[예시 문장]
I have a dog.
[토큰화 결과]
"I", "have", "a", "dog"
위의 예제는 구두점을 제거한 후, 공백문자를 기준으로 잘라내는 매우 단순한 토큰화이지만, 일반적인 토큰화 작업에서는 구두점을 포함해 다양한 특수문자를 정제하는 것부터, “Dr.” 를 “doctor” 로 변경하는 등의 치환 작업 등 복잡한 작업들이 많다. 그리고 그러한 과정에서 토큰이 의미를 잃어버리는 경우도 발생한다. 특히 한국어의 경우 공백 문자 기준으로 처리를 하다보면, 실제로 토큰이 의미를 잃어버리는 경우가 많다.
3. 단어 토큰에 대한 표현방법: Word2Vec
다음으로는 단어단위로 토큰을 생성했을 때, 이를 어떻게 표현해서 기계에게 학습시킬지를 알아보자. 앞서 서문에서 말했듯이, 단어 토큰으로 나누기는 했지만, 이 또한 자연어의 상태이므로 기계가 학습하기에는 어려운 형태이다. 따라서, 이를 기계가 이해하도록 숫자로 변환하는 작업을 거쳐야하며, 이를 임베딩(Embedding) 이라고 한다.
우리는 이미 임베딩 방법들 중 하나를 알고 있다. 바로 원 핫 인코딩(One-Hot Encoding) 이다. 간단하게 설명하자면, 특정 단어들을 단어의 개수 만큼의 행렬을 통해 표현 단어면 1, 아니면 0으로 표현하는 매우 직관적인 방법이였다. 원 핫 인코딩을 사용하면, 직관적인만큼 쉽다는 것이 장점이지만, 단어가 많아질 수록, 단어간의 의미관계를 파악하는 것이 어렵다.
이를 대체하기 위한 방법이 바로 word2vec이다. 말 그대로 단어를 벡터의 형태로 표현하자는 것이다. 간단하게 아래의 사이트에서 다음 내용을 입력해본 결과를 살펴보자. 해당 사이트에서는 한국어 단어를 가지고 덧셈, 뺄셈 으로 연산하여 연관된 단어를 출력해준다.
[입력 내용]
한국 + 도쿄 - 서울
[결과]
일본
신기하게도 단어로 된 식을 통해 연관된 단어가 나오는 것이 마치 연산하는 것으로도 보여진다. 이러한 것이 가능한 이유는 단어간의 유사도를 반영한 값으로 연산하기 때문이다.
앞서 원 핫 인코딩에서 표현하려는 단어만 1로 표시하고, 나머지는 0으로 표시하는 방식을 가리켜 희소 표현이라고 한다. 하지만, 단어간의 유사도를 표현하기 어렵다는 단점이 있었고, 이 점을 보완하고자, 단어의 의미를 다차원 공간상의 벡터로 표현하는 방법을 Word2Vec 에서는 사용했으며, 이러한 표현 방법을 분산 표현(Distributed Representation) 이라고 부른다.
1) 분산 표현 (Distributed Representation)
분산 표현은 기본적으로 분포가설이라는 가정 하에 만들어 졌는데, 비슷한 문맥에 등장하는 단어들은 비슷한 의미를 가진다. 는 가정이다. 예를 들어, 갓난 아이를 보고 귀엽다, 예쁘다 등의 단어가 주로 함께 등장하는데, 이를 다차원 공간상의 벡터로 표현하면 유사한 벡터 값을 가진다.
따라서, 분산 표현은 분포 가설을 이용해 텍스트들을 학습하고, 단어의 의미별로 벡터로 나타내어, 여러 차원에 분산하여 표현하는 것이다. 때문에, 원-핫 벡터와 같이 벡터를 단어 집합의 크기만큼 표현할 일이 없어, 차원이 상대적으로 저차원으로 줄어든다.
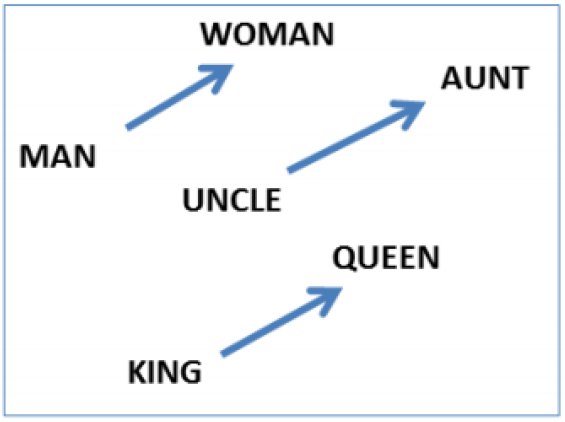
한편, Word2Vec 에는 CBOW(Continous Bag Of Word) 방식과 Skip-Gram 방식으로 나눌 수 있다. 각각에 대한 설명은 다음과 같다.
2) CBOW (Continuous Bag Of Word)
먼저 CBOW 방식을 알아보자. CBOW 는 영어 시험문제 중에 빈칸에 들어가는 단어를 맞추는 것처럼, 주변의 단어들을 입력으로 받아 중간에 있는 단어를 예측하는 방법이다. 예를 들면, [‘The’, ‘fat’, ‘cat’, ‘on’, ‘the’, ‘mat’] 를 통해 ‘sat’ 이라는 단어를 예측하는 것이 CBOW가 하는 일이다. 이 때, 예측하는 단어인 ‘sat’ 은 중심 단어라고 하고, 예측을 위해 사용되는 단어들을 주변 단어라고 부른다.
다음으로 중심 단어를 예측하기 위해서는 주변 단어들을 몇 개 볼 것인가를 결정해야하는데, 이 때 살펴볼 범위를 가리켜 윈도우(Window) 라고 부른다. 앞선 문장을 예시로 들자면, 윈도우가 2이고, 중심단어가 sat이라면, 왼쪽은 ‘fat’, ‘cat’ 을, 오른쪽은 ‘on’, ‘the’ 를 입력으로 사용한다.
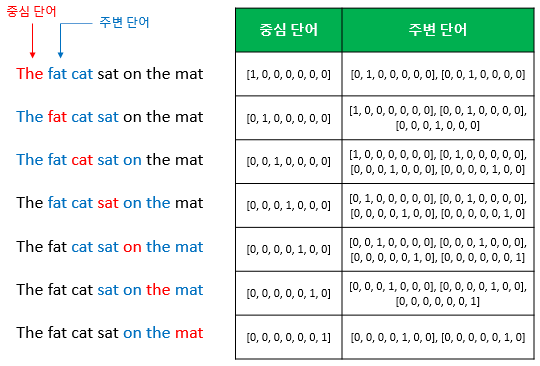
그리고 위의 그림에서처럼, 윈도우의 크기가 정해지면, 옆으로 움직이면서, 주변 단어와 중심단어의 선택을 변경하며 학습하는데, 이를 슬라이딩 윈도우(Sliding Window) 라고 한다. 위의 학습과정을 일반화 및 도식화를 한다면, 아래와 같은 그림으로 표현할 수 있다.
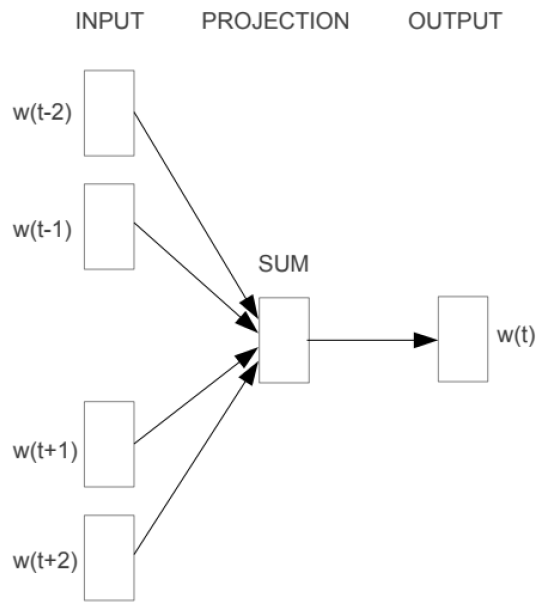
입력층에서는 앞서 말한데로, 중심단어를 기점으로 양옆에 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어들을 원-핫 벡터로 받고, 유사도를 계산해, 출력층에서 예측하려는 단어의 원-핫 벡터로 출력한다. 때문에 해당 단어에 대한 원-핫 벡터도 레이블로 필요하다.
위의 그림을 보면, Word2Vec 도 사실은 얕은 신경망구조라는 것을 알 수 있다. 이해를 돕기 위해 아래의 그림을 살펴보자.
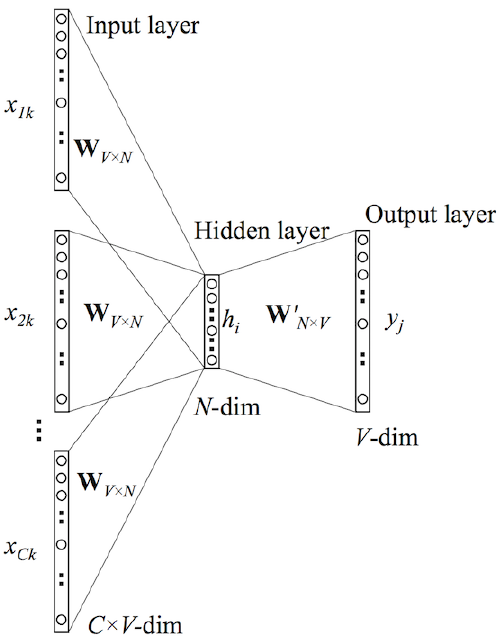
위의 그림에서 주목할 점은 2가지가 있는데, 하나는 투사층(Hidden Layer)의 크기가 N이며, 이는 임베딩 후 벡터의 차원과 같다. 다른 하나는 입력층과 투사층의 가중치가 V x N 이고, 투사층에서 사이의 가중치는 N x V라는 점이다. 여기서 V는 단어 집합의 크기이며, 얼핏 보면 입력층-투사층의 가중치 행렬을 전치(transpose) 하면 투사층-출력층 가중치 행렬이 나오는 것으로 판단할 수 있지만, 서로 다른 행렬임을 인지하자. 앞선 예제를 표현해보자면 아래와 같이 표현할 수 있을 것이다.
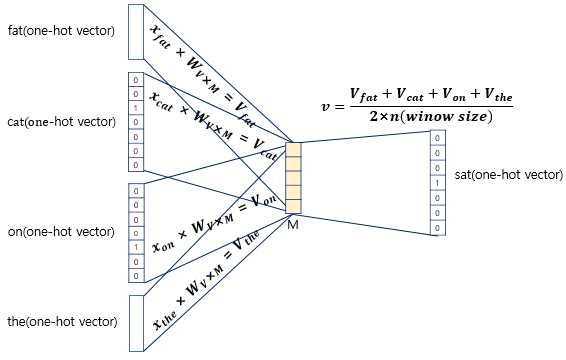
이렇게 주변 단어들의 원-핫 벡터에 가중치 W를 곱한 결과를 투사층으로 보내게 되고, 투사층에서는 입력에 사용된 단어 수만큼 평균을 구해 평균 벡터를 생성한다. 그리고 출력층으로 보낼 때는 투사층-출력층 가중치를 곱하고, 소프트맥스 함수를 통해 0 ~ 1 사이의 실수를 갖는 스코어 벡터로 나온다.
스코어 벡터에서는 레이블에 해당하는 벡터인 중심 단어의 원-핫 벡터에 가까워지기 위해서 손실함수로 크로스 엔트로피 함수를 사용한다. 계산 과정을 수식으로 표현하면 다음과 같다.
$\cos t(\hat{y}, y) = -\sum _{j=1}^V {y}_j \log (\hat{ {y}_j }) $
$(\hat{y} : 스코어벡터, y: 중심 단어의 원-핫 벡터, V: 단어집합의 크기)$
3) Skip-gram
앞서 살펴본 CBOW 가 주변 단어를 통해 중심단어를 예측했다면, Skip-gram 은 중심 단어에서 주변 단어를 예측한다. 이전 예제에 대해, 동일하게 윈도우가 2라고 가정한다면, 다음과 같이 데이터 셋을 구성한다.
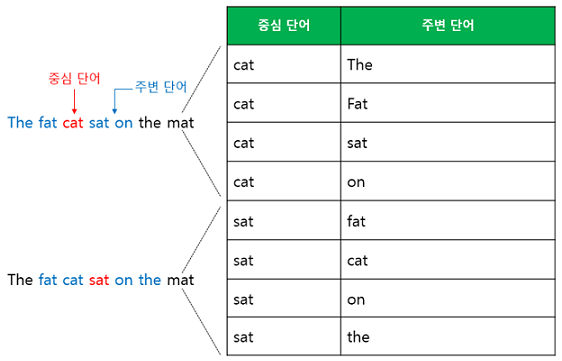
이를 도식화해보자면, 다음과 같이 나타낼 수 있다.
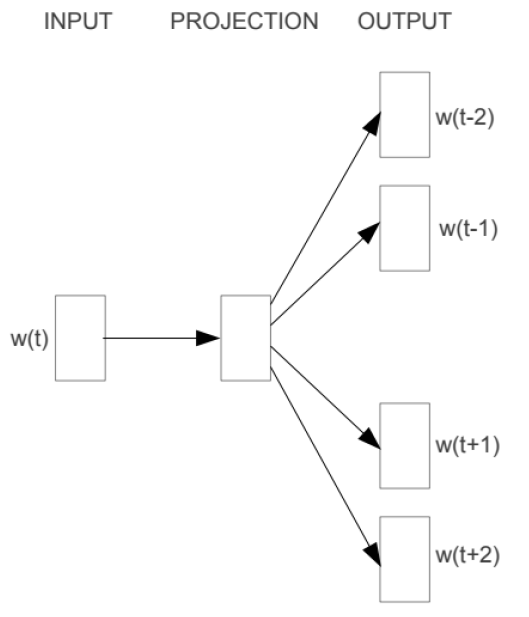
앞서 본 CBOW 와는 대칭이 되는 구조이며, 세부적으로 보면, 중심단어를 기준으로 주변 단어를 예측하는 과정이기에 CBOW와 달리, 투사층에서 벡터들의 평균을 구하는 과정은 없다. 추가적으로 여러 논문을 통해 성능 비교한 결과, 전반적으로 Skip-grame 방식이 CBOW 방식보다 성능이 좋다고 한다.
4. 실습: Word2Vec 생성하기
그렇다면 실제로 한 번 Word2Vec을 통해 영어 및 한국어 데이터를 학습해보자. 이번 예제에서 사용할 패키지는 gensim 패키지를 사용하며, 해당 패키지에 포함된 사전에 구현된 Word2Vec을 이용하면 손쉽게 단어를 임베딩 벡터로 변환시킬 수 있다.
먼저, 예제로 사용할 학습 데이터를 먼저 받아보자. 아래 코드를 실행해서 가져올 수 있으며, 해당 데이터는 XML 문법으로 작성되어 있기 때문에, 자연어를 얻으려면 추가적인 전처리 작업이 필요하다.
[Python Code]
import re
import urllib.request
import zipfile
import nltk
from lxml import etree
from nltk.tokenize import word_tokenize, sent_tokenize
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
# 사전작업
nltk.download('punkt')
# 데이터 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/ukairia777/tensorflow-nlp-tutorial/main/09.%20Word%20Embedding/dataset/ted_en-20160408.xml",
filename="data/ted_en-20160408.xml")
위의 코드에서 사전작업 및 데이터 다운로드는 1번만 수행하면 된다. 다운로드가 완료되면, 저장된 데이터를 읽어오자. 이 때, 파일 형식이 XML 이기 때문에, 파일 내용 중에서 순수 텍스트만 가져오기 위해 etree 모듈 중 parse() 를 사용해서 가져온다.
[Python Code]
# 데이터 로드
data = open('data/ted_en-20160408.xml', 'r', encoding='UTF8')
text = etree.parse(data)
위의 코드로 순수 텍스트만 가져왔지만, 아직까진 특수문자 및 의미 없는 문자들이 포함되어 있기 때문에 전처리를 수행해야한다. 이번 예제에서는 줄바꿈 및 각종 특수기호들을 공백으로 바꾸는 방식으로 전처리를 진행한다.
[Python Code]
# 원본 데이터 전처리
parse_text = '\n'.join(text.xpath('//content/text()'))
content = re.sub(r'\([^)]*\)', '', parse_text)
[실행 결과]
Here are two reasons companies fail: they only do more of the same, or they only do what's new.
To me the real, real solution to quality growth is figuring out the balance between two activities:
....
다음으로 토크나이징을 해보자. 위의 실행결과를 보면 알 수 있듯이, 문맥의 형태이기 때문에, 이를 좀 더 작은 단위인 문장의 단위로 나눠줄 것이며, 이를 위해 nltk 라이브러리 중 sent_tokenize() 함수를 사용하면 된다. 사용하면 결과를 리스트 형태로 반환해주며, 이 중 첫 번째 요소만 출력해보면 다음과 같다.
[Python Code]
sent_text = sent_tokenize(content)
print(sent_text[0])
[실행 결과]
"Here are two reasons companies fail: they only do more of the same, or they only do what's new."
확인해보면 알 수 있듯이, 아직까지는 문장 단위의 토큰이기 때문에, 단어 단위의 토큰으로 바꿔주려면 아래의 절차까지 완료해야한다. 내용이 모두 영어로 구성되어 있기 때문에, 영문자의 경우에는 대소문자 구분없이 모두 소문자로 통일시키고, 영어 및 숫자가 아닌 모든 문자에 대해서는 공란으로 바꿔준다.
그 다음, 문장 토큰을 단어 토큰으로 바꾸기 위해 각 문장을 word_tokenize() 함수에 넣어서 단어 단위 토큰을 생성한다.
[Python Code]
noralized_text = []
for string in sent_text:
token = re.sub(r"[^a-z0-9]+", " ", string.lower())
noralized_text.append(token)
result = [word_tokenize(sentence) for sentence in noralized_text]
print("총 샘플 개수: {}".format(len(result)))
[실행 결과]
총 샘플 개수: 273424
단어 토큰의 결과를 확인해보자. 양이 많기 때문에, 맨 앞부터 3개에 대해서만 확인할 것이다.
[Python Code]
# 샘플 출력
for line in result[:3]:
print(line)
[실행 결과]
['here', 'are', 'two', 'reasons', 'companies', 'fail', 'they', 'only', 'do', 'more', 'of', 'the', 'same', 'or', 'they', 'only', 'do', 'what', 's', 'new']
['to', 'me', 'the', 'real', 'real', 'solution', 'to', 'quality', 'growth', 'is', 'figuring', 'out', 'the', 'balance', 'between', 'two', 'activities', 'exploration', 'and', 'exploitation']
['both', 'are', 'necessary', 'but', 'it', 'can', 'be', 'too', 'much', 'of', 'a', 'good', 'thing']
이제 단어 단위의 토큰들을 생성했으니, 본격적으로 Word2Vec 을 생성해보자. 이번 예제에서는 Word2Vec 을 생성할 때, CBOW 방식으로 토크나이저를 생성할 것이며, 사용할 함수는 gensim의 model 모듈 내에 있는 Word2Vec() 함수를 호출해서 생성할 수 있다.
해당 함수에는 여러 가지 매개변수들이 있지만, 이중에서 우리가 사용할 것은 학습 시킬 문장(sentences), 워드 벡터의 특징 값 혹은 임베딩된 벡터의 차원(vector_size), 주변 단어 수(window), 단어 최소 빈도 수 제한(min_count), 학습에 사용되는 프로세스 수(workers), Word2Vec 생성 방식(sg) 를 사용할 것이다. 코드는 다음과 같다.
[Python Code]
# Word2Vec 학습하기
word2vec = Word2Vec(
sentences=result, # 학습 시킬 문장
vector_size=100, # 특징 값 혹은 임베딩 된 벡터의 차원
window=5, # 주변 단어 수
min_count=5, # 단어 최소 빈도 수 / 해당 숫자보다 적은 빈도의 단어들은 사용하지 않음
workers=4, # 학습에 사용되는 프로세스 수
sg=0 # Word2Vec 생성 방식 / 0 : CBOW, 1: Skip-gram
)
Word2Vec 모델을 생성했으니, 예시로 “man” 이라는 단어와 유사한 단어들을 확인해보자. 유사한 단어들을 확인하는 방법은 word2vec 모델에서 제공하는 most_similar() 메소드를 사용하면 되며, 매개변수로는 단어를 입력해주면, 유사도가 높은 단어들과 단어의 유사도를 가장 높은 순으로 출력한다.
[Python Code]
model_result = word2vec.wv.most_similar("man")
print(model_result)
[실행 결과]
[('woman', 0.8517822623252869),
('guy', 0.8084050416946411),
('boy', 0.7709711790084839),
('girl', 0.7593225240707397),
('lady', 0.7527689933776855),
('gentleman', 0.7414157390594482),
('kid', 0.6947308778762817),
('soldier', 0.69269859790802),
('son', 0.6630584597587585),
('surgeon', 0.6612566709518433)]
끝으로 Word2Vec 모델을 저장하는 법과 다시 불러오는 방법을 알아보자. 먼저 저장을 할 때는 save_word2vec_format() 메소드를 사용해서 원하는 파일명으로 모델을 저장한다. 이 후 저장된 Word2Vec 모델을 다시 불러오려면, gensim의 models 모듈 내에 있는 KeyedVectors 모듈 안에 위치한 load_word2vec_format() 함수를 실행하면 된다.
[Python Code]
# 모델 저장 및 로드
## 모델 저장
word2vec.wv.save_word2vec_format('eng_w2v')
## 모델 로드
loaded_model = KeyedVectors.load_word2vec_format('eng_w2v')
다시 불러온 모델로 앞서 본 “man” 단어와 유사한 단어를 찾는 예제를 수행하면 동일한 결과가 나오는 것까지 확인할 수 있다.
[Python Code]
## 로드 결과 확인
model_result = loaded_model.most_similar("man")
print(model_result)
[실행 결과]
[('woman', 0.8517822623252869),
('guy', 0.8084050416946411),
('boy', 0.7709711790084839),
('girl', 0.7593225240707397),
('lady', 0.7527689933776855),
('gentleman', 0.7414157390594482),
('kid', 0.6947308778762817),
('soldier', 0.69269859790802),
('son', 0.6630584597587585),
('surgeon', 0.6612566709518433)]
[참고자료]
https://wikidocs.net/22660
댓글남기기