
[Python Deep Learning] 13. Modern CNN Ⅴ : ShuffleNet

1. 개요
앞서 살펴본 MobileNet 에 이어 경량화에 집중한 모델이다. 이 모델은 맨 처음에 봤던 AlexNet 과 동일한 정확도지만, 연산 속도에서는 13배 더 빠르다.
ShuffleNet은 Xception 과 MobileNet에서 사용한 Depthwise Separable Convolution 을 사용하고, ResNext 에서 나온 Group Convolution 을 사용한다. Pointwise Group Convolution 과 Channel Shuffle 을 사용한다. 뒤에서 자세하게 다루겠지만, 간단히 말하자면, Pointwise Group Convolution 은 연산량을 감소시키기위해 제안되었고, Channel Shuffle 은 Group Convolution 에서 발생하는 문제점을 해결하기 위함이다.
2. Pointwise Group Convolution & Channel Shuffle
ShuffleNet의 핵심 중 하나로 1x1 Pointwise Convolution 의 연산량을 감소시키기 위해 제안되었다. Pointwise Group Convolution 을 이해하기 전에 먼저 Pointwise Convolution 을 알아보자.
Pointwise Convolution 은 공간 방향의 Convolution 이 아니라 채널 방향으로 Convolution을 진행해서, 채널 수를 조절하는 연산이며, 기본적으로 각 픽셀 마다 Fully-Connected layer 의 원리와 동일하기 때문에 연산량이 많다는 특징이 있다. 때문에, ShuffleNet에서는 이를 1x1 Convolution에 적용했으며, 여기에 Group convolution 연산까지 추가해서 Pointwise Group Convolution 연산을 하도록 설계한 것이다.
Group Convolution 은 MobileNet에서 봤던 Depthwise Convolution 을 떠올리면 쉽게 이해할 수 있다. 아래 그림에서는 2개의 그룹을 사용했는데, 좌측에 위치한 H x W x C1 에서 1 ~ C1/2 까지는 h1 x w1 x c1/g 의 필터를 통해 H x W x C2/2 를 완성시키고 C1/2 ~ C1 까지는 h1 x w1 x c2/g 필터를 통해 나머지 반을 완성시키게 된다.
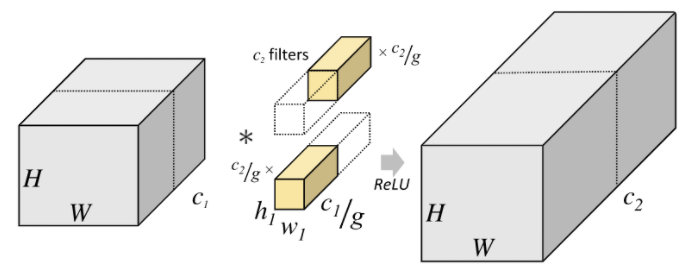
위와 같이 연산을 하게 되면, 다음과 같은 효과를 얻을 수 있다.
[Group Convolution 연산의 효과]
- 병렬처리에 효율적이다.
- 파라미터 수가 감소된다. (채널 방향의 연산이 줄어들기 때문이다.)
- 각 Channel Group 마다 높은 상관성(Correlation)을 갖는 feature 들이 학습된다.
하지만, 마지막 3번 특징의 경우, 채널 그룹마다 독립적으로 convolution 연산이 수행되기 때문에 서로 다른 group 에 있는 채널끼리는 feature 에 대한 정보가 교환되지 않게 되며, 유의미한 feature를 추출하는 데에 방해가 되는 요소이다.
이를 극복하고자 ShuffleNet에서는 Channel Shuffle 을 도입하게 된다. 설명에 앞서, 우선 ShuffleNet에서 수행하는 Group Convolution을 살펴보도록 하자.
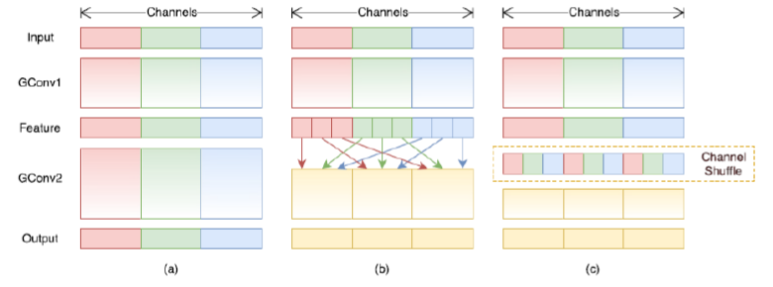
먼저 일반적으로 Group Convolution 을 수행한다면, 맨 왼쪽 그림 (a) 와 같이 입력에 대해 3개의 채널이 각각 독립적으로 그룹을 이룬 상태로 학습이 이뤄진다. 하지만, 이럴 경우 앞서 언급한 것처럼, feature 가 섞이지 않아, 유의미한 feature를 찾기 어렵다는 단점이 있다.
이를 위해 그림(b) 와 같이 각 그룹별로 특정 크기만큼씩 분할한 후 균일하게 분포하도록 섞어서 그림 (c) 와 같은 형태로 재배치한 후에 학습을 진행하는 것이 Channel Shuffle 의 원리이다.
3. ShuffleNet 구조
1) ShuffleNet 모듈
그렇다면 ShuffleNet의 구조의 핵심인 모듈에 대해서 살펴보도록 하자. 아래 그림은 ShuffleNet에 대한 변천사를 보여주는 그림이다.
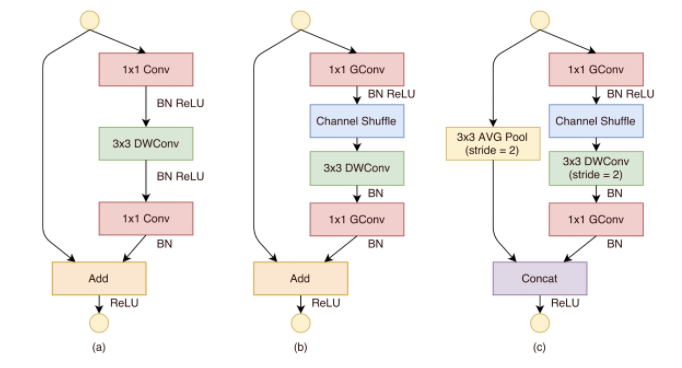
초창기 ShuffleNet의 구조는 제일 왼쪽의 그림처럼 MobileNet과 같이 1x1 Conv. 를 수행한 다음, 3x3 Depthwise Conv. 를 수행한다. 하지만 해당 구조의 경우 1x1 Conv. 를 수행하는 과정에서 오버헤드가 발생하며, 앞서 언급한 것처럼 ShuffleNet 에서는 1x1 Conv. 의 오버헤드를 줄이는 것이 주요 목적이라고 했다.
이를 위해 가운데 그림에서처럼 1x1 Conv. 를 Group Conv. 연산으로 변경해주고, 이어서 바로 channel shuffle 을 수행해서 효과적인 feature 추출을 보장한다.
특이사항으로는 두 번째 1x1 Group Conv. 이후에는 Channel Shuffle 을 따로 수행하지 않았는데, 그 이유는 channel shuffle 을 하지 않아도 성능 상의 손실이 없었기 때문이다. 마지막으로 맨 오른쪽의 그림은 컨볼루션 연산 시, stride 가 1보다 큰 경우에 사용되는 모듈 구조이다. 3x3 depthwise Conv. 에서 stride 가 2이기 때문에 차원을 맞추기 위해서 skip connection 부분에 stride = 2 인 Avg Pooling 연산을 추가한 것이 그 이유이다.
이렇게 pointwise group conv. 연산을 적용한 결과 연산량이 상당히 줄어들게 된다. 구체적인 성능은 조금 뒤에서 살펴보도록 하자.
2) 네트워크 구조
그렇다면 전체적인 네트워크의 구조는 어떨까? 아래의 표는 실제 논문에 기재된 네트워크의 구조에 대한 표를 가져온 것이다.
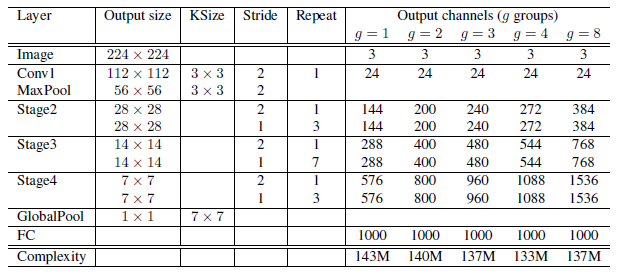
표를 통해 알 수 있듯이, 매 stage 마다 stride = 2 로 하여 입력 사이즈를 줄이면서 출력 채널 크기를 늘려간다. 각 유닛의 bottlenect layer 의 채널 수는 기존과 동일하게 출력 채널의 1/4로 설정한다. 추가적으로 모델에 대한 복잡도와 관련하여 앞서 다룬 MobileNet 과 비교했을 때, 150MFLOPS (복잡도의 단위, 전체 곱하기와 더하기의 개수를 의미함) 이하의 소규모 모델에 한해서 특별하게 설계되었지만, 전반적으로 MobileNet 보다는 성능이 좋다고 할 수 있다.
4. 구현하기
마지막으로 ShuffleNet 을 구현해보도록 하자. 먼저 ShuffleNet의 핵심인 채널 셔플(Channel Shuffle) 을 먼저 구현해보도록 하자. 코드는 다음과 같다.
[Python Code]
# 필요 라이브러리 import
from tensorflow.keras.layers import Dense, DepthwiseConv2D, Conv2D, BatchNormalization, Activation, Permute, Reshape, AvgPool2D, Add, Concatenate, Input, MaxPool2D, GlobalAvgPool2D
from tensorflow.keras.models import Model
# Channel Shuffle
def channel_shuffle(x, groups):
_, width, height, channels = x.get_shape().as_list()
group_channels = channels // groups
x = Reshape([width, height, group_channels, groups])(x)
x = Permute([1, 2, 4, 3])(x)
x = Reshape([width, height, channels])(x)
return x
다음으로 ShuffleNet을 구성하는 유닛을 만들어보자.
[Python Code]
def unit(x, groups, channels, strides):
y = x
x = Conv2D(channels//4, kernel_size=1, strides=1, padding="same", groups=groups)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = channel_shuffle(x, groups)
x = DepthwiseConv2D(kernel_size=3, strides=strides, padding="same")(x)
x = BatchNormalization()(x)
if strides == 2:
channels = channels - y.shape[-1]
x = Conv2D(channels, kernel_size=1, strides=1, padding="same", groups=groups)(x)
if strides == 1:
x = Add()([x, y])
elif strides >= 2:
y = AvgPool2D(pool_size=3, strides=strides, padding="same")(y)
x = Concatenate([x, y])
x = Activation('relu')(x)
return x
맨 마지막을 if 문은 stride 값이 1인 경우와 1보다 큰 경우를 구현한 것이며, 1보다 큰 경우라면, Skip Connection 부분에 동일한 크기의 Stride 만큼 AveragePooling 을 해서 채널을 맞춰주기 위함이다.
이제 모든 준비가 마무리됬다. 끝으로 ShuffleNet을 구현해보도록 하자. 코드는 다음과 같다.
[Python Code]
def shufflenet(n_classes, start_channels, input_shape=(224, 224, 3)):
groups = 2 # 그룹 수 설정
# Image
input = Input(input_shape)
# Conv1 ~ MaxPool
x = Conv2D(kernel_size=3, strides=2, padding="same", use_bias=True)(input)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = MaxPool2D(pool_size=3, strides=2, padding="same")(x)
# Stage 2 ~ 4
repetitions = [3, 7, 3] # 구조표 중 repeat 에 해당하는 내용
for i, repetition in enumerate(repetitions):
channels = start_channels * (2 ** i) # output size 조절
x = unit(x, groups, channels, strides=2)
for i in range(repetition):
x = unit(x, groups, channels, strides=1)
# GlobalPool
x = GlobalAvgPool2D()(x)
# Fully-Connected layer
output = Dense(n_classes, activation="softmax")(x)
model = Model(input, output)
return model
댓글남기기