
[Python Deep Learning] 11. Modern CNN Ⅲ : Xception

1. 개요
이번 장에서는 이전에 배운 Inception 모델의 발전형인 Xception 모델에 대해서 살펴보도록하자. 모델에 대한 논문은 “Xception: Deep Learning with Depthwise Separable Convolutions” 에서 확인할 수 있다. 방금 말한 것처럼 Xception 모델은 Inception을 기반으로 만들어졌기 때문에, 먼저 Inception 모듈을 다시 한 번 간략하게 살펴보고 Xception 모델과는 어떤 차이가 있는지 알아보도록하자.
2. Overview : Inception
이전에 다뤘었던 Inception 모델의 내용을 잠깐 떠올려보자. Inception 모듈의 아이디어는 NIN(Network In Network) 구조에서 영감을 받았고, 주어진 입력에 대해 4개의 부분을 병렬적으로 구성해서, 컨볼루션 연산을 통해 각각 특징을 추출한 후, 결과를 합쳐 하나의 최종적인 출력을 만드는 과정이 있다. 그림으로 보면 아래와 같다.<br
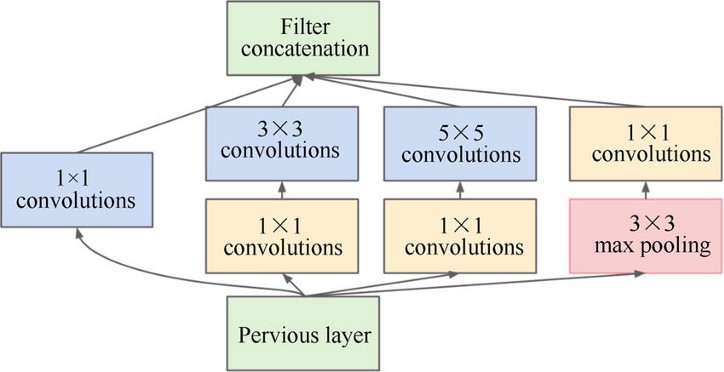
이후 5x5 컨볼루션 연산을 하는 것보다, 3x3 컨볼루션 연산 2번을 하는 것이 효과적이기 때문에, 변형이 되어 V2, V3 모듈까지 생성되었고, ResNet 과 결합하여 Inception-ResNet 이라는 모델을 탄생시키기도 했다.
이처럼 하나의 커널(필터) 만으로 cross-channel correlation과 spatial correlation을 동시에 mapping 해야 했는데, Inception 은 이 두가지 역할을 독립적으로 살펴 볼 수 있도록 잘 분산해주었다.
3. Xception
1) Inception 모듈의 가설
위에서 본 Inception 모듈에 대해서, 논문의 저자는 1x1 conv 연산 후에 3x3 conv 연산을 수행하는 구조를 통해, cross-channel correlation과 spatial correlation 이 독립적으로 수행된다고 한다. 정확하게는 논문에 나온 Incetption-V3 와의 비교한 내용이기 때문에 먼저 아래 그림을 통해 Inception-V3 모듈을 살펴보자.
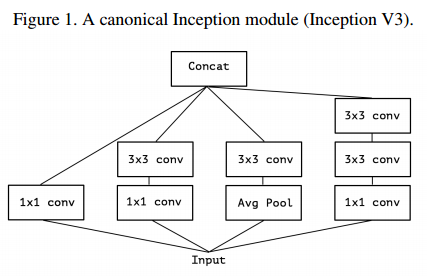
앞서 말한 것처럼 1x1 conv 연산 후에 3x3 conv 연산을 수행하는 구조를 통해, cross-channel correlation과 spatial correlation 이 독립적으로 수행된다라고 했는데, 그 이유는 1x1 conv 연산에서는 cross-channel correlation 을 계산하고, 3x3 conv 연산에서는 spatial correlation을 수행할 수 있었고, 이 두가지를 동시에 고려하는 것은 제약이 많지만, Inception 모듈의 구조상 bottleneck 기법으로 채널만 먼저 계산 후, 이후에 가로, 세로 연산이 가능했기 때문이다. 하지만, 완벽하게 수행하는 것이 Inception-V3에서는 어려웠기 때문에, 해당 사항을 개선하여 완벽하게 cross-channel correlation과 spatial correlation 을 독립적으로 계산하고 매핑하기 위한 모델로 Xception 을 개발한 것이다.
2) Depthwise Separable Convolution
Xception 모듈의 동작 방식과 비슷한 연산인 Depthwise Separable Convolution 연산을 먼저 알아보도록 하자.
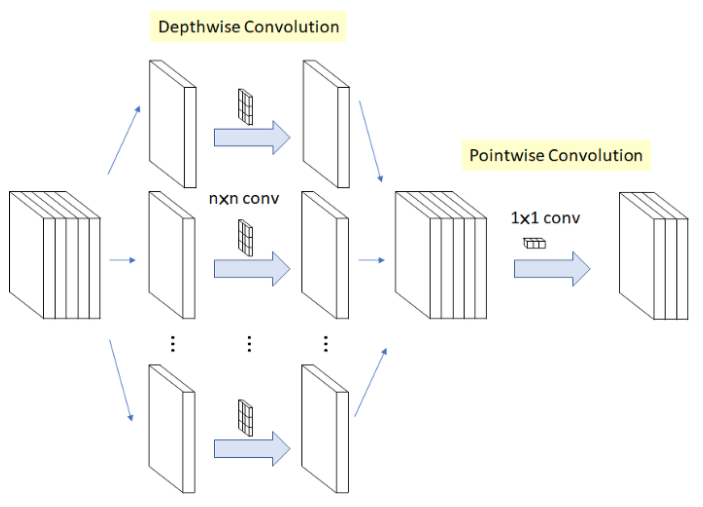
연산과정은 아래 그림에서처럼 Depthwise Convolution 을 먼저 수행하고, Pointwise Convolution 을 다음으로 수행한다.
먼저, Depthwise Convolution 연산부터 살펴보도록 하자. 이 연산은 아래 그림에 있는 것처럼, 입력 채널 각각에 독립적으로 3x3 conv 연산을 수행하는 것이다.
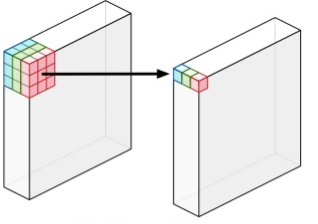
예를 들어, 그림에서처럼 3개의 채널을 갖고 있다면, 3개의 3x3 conv 연산을 수행해서 3개의 결과(정확히는 입력 채널 수만큼의 결과)를 만들어 낸다.
이어서 수행되는 Pointwise Convolution 은 모든 채널에 대해 1x1 conv 연산을 수행해서 채널 수를 조절하며, 결과적으로 신경망 전체의 연산량을 줄여주는 효과가 있다.
위의 2가지 연산을 합친 것이 Depthwise Separable Convolution 연산이며, Xception 에서는 이를 아래 내용과 같이 수정하였다. 어떻게 바꿨는지 그림과 함께 살펴보도록 하자.
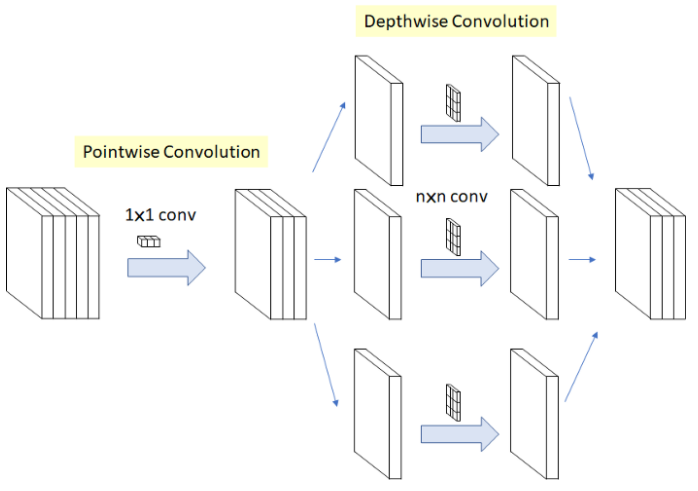
위의 그림을 보면 알 수 있듯이, Pointwise Convolution 연산을 먼저 하고, 결과를 Depthwise Convolution 연산을 해줌으로써, 최종 결과를 만들어 낸다. 위의 구조로 연산을 하게 되면, 기존 Inception 모듈보다 효과적으로 cross-channel correlation과 spatial correlation 을 독립적으로 계산할 수 있다.
일반적으로 신경망이 깊어지게 되면, 비선형함수를 사용하는 것이 효과적이지만, Xception 의 경우에는 반대로 비선형함수를 사용하지 않은 경우에 성능이 더 좋다.
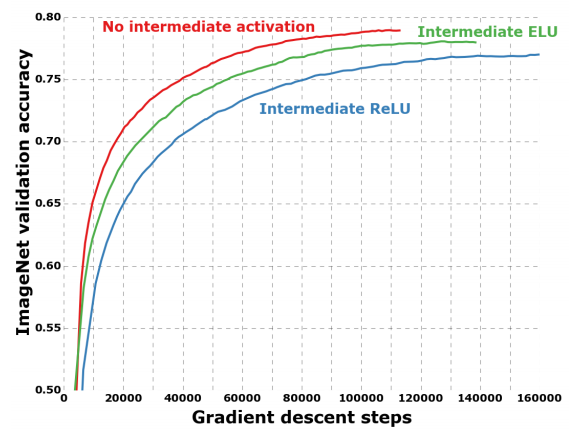
위의 그림은 비선형함수를 적용했을 때와 적용하지 않을 경우의 모델 성능을 보여준다. 앞서 언급한 것처럼 일반적이라면 ReLU 함수를 사용했을 때의 성능이 사용하지 않을 때보다 높아야 되지만, Xception 에서는 오히려 사용하지 않은 경우가 가장 높은 성능을 보여준다. 저자의 의견으로는 Depthwise Convolution 연산을 수행할 때 비선형함수를 사용하면, 정보의 손실을 가져올 수 있기 때문이라고 설명한다.
3) 구조
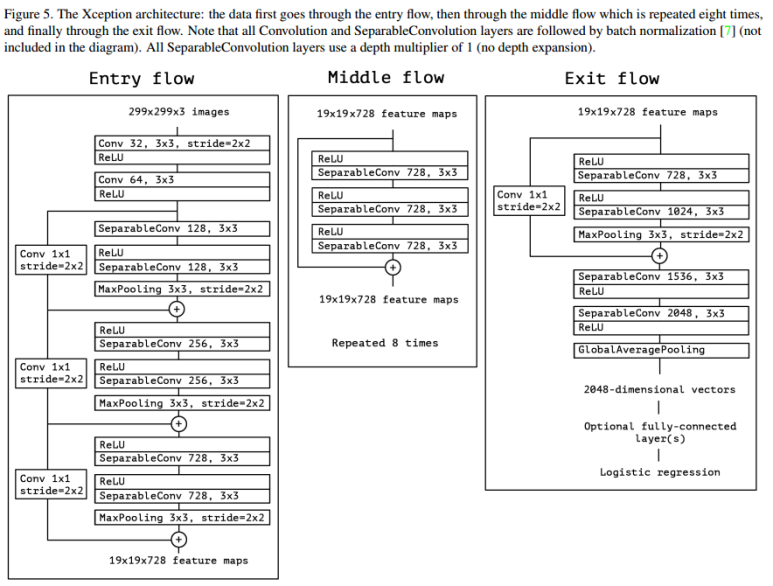
그렇다면 Xception 모델의 구조와 특징을 알아보도록 하자. Xception 은 아래 그림에서처럼 Entry flow, Middle flow, Exit flow 인 총 3개 단계로 구성된다. 총 14개의 모듈로 이뤄져있고, 36개의 컨볼루션 레이어가 존재한다. 그리고 각 모듈 간에는 Residual Connection 을 사용하여 선형적으로 쌓인 구조이다.
[참고자료]
arxiv.org/abs/1610.02357
https://deep-learning-study.tistory.com/529
https://wikidocs.net/122179
댓글남기기