
[Python] 7. 텍스트 처리

1.문자열
1) 유니코드
프로그래밍을 시작한 사람이라면 가장 먼저 만나게 되는 문자열 포맷은 아스키 코드(ASCII Code) 일 것이다.
아스키코드는 1960년대에 정의되었으며, 7비트를 사용하는 문자열이며, 128개의 고유한 값 만을 사용한다.
영어 대소문자 각 26개, 숫자 10개, 구두 문자, 공백 문자, 비인쇄 제어 코드로 구성된다.
하지만 시간이 지남에 따라, 아스키코드로 표현할 수 있는 범위 외에 다른 문자들을 표현하고자, 전 세계 언어의 문자를 정의하기 위한 국제 표준 코드가 정의되는 데, 이것이 바로 유니코드(Unicode) 다. 유니코드는 플랫폼, 프로그램, 언어에 상관없이 문자마다 고유한 코드값을 제공하며, 언어 이외에 수학기호 및 기타 문자 기호들도 포함하고 있다.
파이썬 3에서의 문자열은 유니코드 문자열을 사용한다. 이는 파이썬 2와 비교했을 때, 크게 변화한 부분중 하나이며, 일반적인 바이트 문자열과 유니코드 문자를 구별해서 사용할 수 있다.
유니코드 식별자 및 이름을 검색하기 위해서 파이썬3에서는 unicodedata 모듈을 제공하며, 해당 모듈에는 아래와 같이 2개의 함수를 제공한다.
(1) lookup()
대/소문자를 구분하지 않는 인자를 취하고, 결과로 유니코드 문자를 반환한다.
(2) name()
인자로 유니코드 문자를 받고, 대문자로 반환해준다.
예시를 통해 위의 2개 함수에 대한 사용법을 살펴보자.
[Python Code]
def unicode_test(value):
import unicodedata
name = unicodedata.name(value)
value2 = unicodedata.lookup(name)
print("value {}, name={}, value2={}".format(value, name, value2))
unicode_test('A')
unicode_test('$')
unicode_test('\u20ac')
[실행결과]
value A, name=LATIN CAPITAL LETTER A, value2=A
value $, name=DOLLAR SIGN, value2=$
value €, name=EURO SIGN, value2=€
2) 포맷
파이썬에서 포맷은 데이터 값을 문자열 사이에 끼워넣는 작업을 의미한다. 이를 포맷팅(formatting)이라고도 하며, 주로 print() 문과 함께 많이 사용된다. 방식으로는 크게 2가지로 포맷팅을 할 수 있다.
(1) 옛 스타일: %
문자열 포맷팅 중 옛 스타일이라고 하는 것은 “String % data” 와 같은 형태이다. 즉, 문자열 안에 끼워넣을 데이터를 표시하는 형식으로 보간 시퀀스(Interpolation Sequence) 라고 한다. 사용할 수 잇는 타입들은 아래 표와 같다.
| 포맷(Format) | 변환 타입 |
|---|---|
| %s | 문자열 |
| %d | 10진 정수 |
| %x | 16진 정수 |
| %o | 8진 정수 |
| %f | 10진 부동소수점 수 |
| %e | 지수 부동소수점 수 |
| %g | 10진 또는 지수 부동소수점 |
| %% | 리터럴 % |
아래 예시를 통해 코드 실행 후 결과를 비교해보자.
[Python Code]
print("1. 정수"+"\n")
print('%s' % 42)
print('%d' % 42)
print('%x' % 42)
print('%o' % 42)
print("2. 부동소수점수" + "\n")
print('%s' % 10.8)
print('%f' % 10.8)
print('%e' % 10.8)
print('%g' % 10.8)
print("3. 문자열 + 정수")
actor = "Richard Gere"
cat = "Chester"
weight = 28
print("My wife's favorite actor is %s" % actor)
print("Our cat %s weights %s pound" % (cat, weight))
[실행결과]
1. 정수
42
42
2a
52
2. 부동소수점수
10.8
10.800000
1.080000e+01
10.8
3. 문자열 + 정수
My wife's favorite actor is Richard Gere
Our cat Chester weights 28 pound
위의 예제에서처럼 %s 는 문자열 중간에 다른 문자열을 끼워 넣겠다는 의미로 사용되었고, 끼워 넣는 문자는 문자열 다음 % 뒤의 데이터 항목이며, 문자열에서 중간에 들어오는 변수의 개수만큼 % 뒤의 데이터 항목 개수도 맞춰줘야한다.
다음으로 문자열을 특정 길이 만큼 정렬해주는 방법을 알아보자. 해당방법은 최소 및 최대 길이 조절과 정렬 및 문자를 채우기 위해 %와 타입 지정자 사이에 다른 값을 추가해줘야한다. 아래 예시를 통해 방법을 살펴보자.
[Python Code]
print("4. 문자열 길이 조정")
n = 100
f = 10.8
s = "String cheese"
print("%d %f %s" % (n, f, s))
print("%10d %10f %10s" % (n, f, s))
[실행결과]
4. 문자열 길이 조정
100 10.800000 String cheese
100 10.800000 String cheese
위의 예시에서처럼 전체 자릿수를 같이 표시해 줌을써 포멧팅 문자열의 길이를 지정해줄 수 있다.
(2) 새로운 스타일의 포맷팅: {} & format()
옛 스타일의 포맷팅은 주로 파이썬 2 버전에서만 지원되는 형식이지만, 파이썬 3를 사용한다면 지금부터 다룰 포맷팅 형식 사용을 권장한다. 설명에 앞서 먼저 예시를 통해 어떤 방식인지부터 보도록 하자.
[Python Code]
print("1. {} 사용법")
n = 100
f = 10.8
s = "String cheese"
print("{} {} {}".format(n, f, s))
[실행결과]
1. {} 사용법
100 10.8 String cheese
앞서 살펴봤던 예제와 동일한 결과를 반환하는 예제인데, 코드 상으로 보면 지금의 예제가 좀더 간결해보인다.
차이점은 옛 스타일의 경우 문자열에 %가 나타난 순서대로 데이터를 제공되는 데에 반해, 위의 예시는 아래와 같이 순서를 지정해줄 수 있다.
[Python Code]
print("2. {} 사용 시 순서 정하기")
n = 100
f = 10.8
s = "String cheese"
print("{2} {0} {1}".format(n, f, s))
[실행결과]
2. {} 사용 시 순서 정하기
String cheese 100 10.8
바로 직전 예제와 비교했을 때, {} 사이에 변수의 순번을 넣어주면 .format() 메소드에 등장하는 순번의 변수 값을 대입해준다.
이번에는 좀 더 색다르게 자료구조를 사용해서 문자열 포맷팅하는 것을 살펴보자. 예를 들어 아래와 같은 사전이 정의되었다고 가정해보자.
[Python Code]
dict_a = {'n': 100, 'f': 10.8, 's': "String cheese"}
그리고 아래와 같은 예시를 수행한다할 때 어떠한 값이 출력되는지를 살펴보자.
[Python Code]
print("3. 자료구조를 활용한 포맷팅")
dict_a = {'n': 100, 'f': 10.8, 's': "String cheese"}
print("{0[n]} {0[f]} {0[s]} {1}".format(dict_a, "other"))
[실행결과]
3. 자료구조를 활용한 포맷팅
100 10.8 String cheese other
위의 예시에서처럼 사전 혹은 다른 자료구조들을 사용할 때, {0[n]} 과 같이 자료구조의 특징을 활용해서 문자열 포맷팅을 수행할 수도 있다.
그렇다면 문자열 길이 조절은 어떻게 할까? 방식은 기존과 비슷하지만, 아래 예시에서 보여지듯 : 다음에 타입 지정자를 입력한다.
[Python Code]
print("4. 문자열 길이 조절하기")
n = 100
f = 10.8
s = "String cheese"
print("{0:d} {1:f} {2:s}".format(n, f, s))
[실행결과]
4. 문자열 길이 조절하기
100 10.800000 String cheese
추가적으로 각 필드 값의 최소, 최대 길이와 정렬 방식을 설정할 수도 있다.
[Python Code]
print("5. 문자열 길이 지정")
n = 100
f = 10.8
s = "String cheese"
print("{0:>10d} {1:^10f} {2:<10s}".format(n, f, s))
[실행결과]
5. 문자열 길이 지정
100 10.800000 String cheese
위의 예시에서처럼 최소 길이 및 최대 길이는 숫자로 표현하고, < 는 왼쪽정렬, ^ 는 가운데 정렬, > 는 오른쪽 정렬을 의미한다.
2. 정규 표현식
1) 정규표현식이란?
정규표현식이란, 사전적으로는 특정 규칙을 가진 문자열의 집합을 표현하기 위해서 사용하는 형식 언어라고 할 수 있다. 주로 문자열의 검색 및 치환을 위한 용도로 많이 사용된다. 정규표현식을 사용하게 되면, 기존에 조건문으로 길게 작성해야만 처리 가능한 문자를 매우 간단하게 표현할 수 있다는 장점이 있지만, 코드가 간단해지는 만큼 가독성이 떨어지는 것도 있으므로 표현식의 의미를 숙지하지 않으면 이해하기 어렵다.
정규표현식에는 표준인 POSIX 방법과, 이의 확장판인 PCRE가 대표적이다. 또한 정규표현식에서 사용하는 기호는 Meta문자라고 하며, 공통적인 문자들로는 다음과 같다.
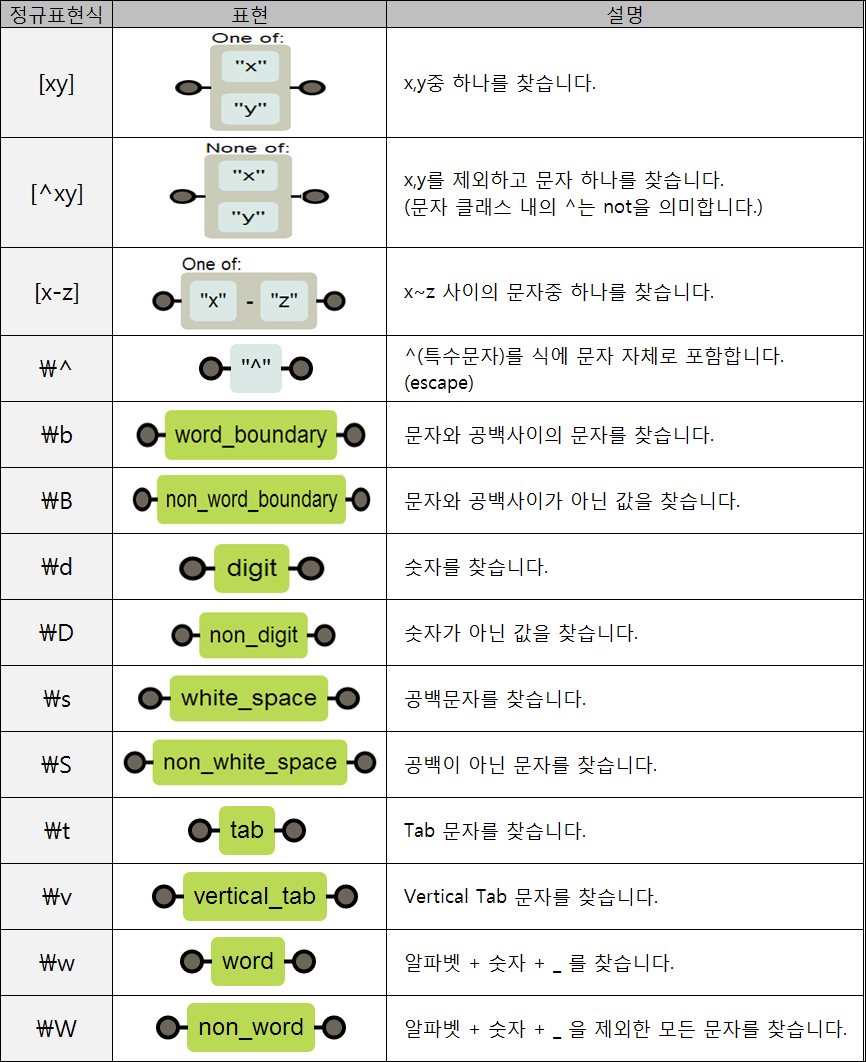
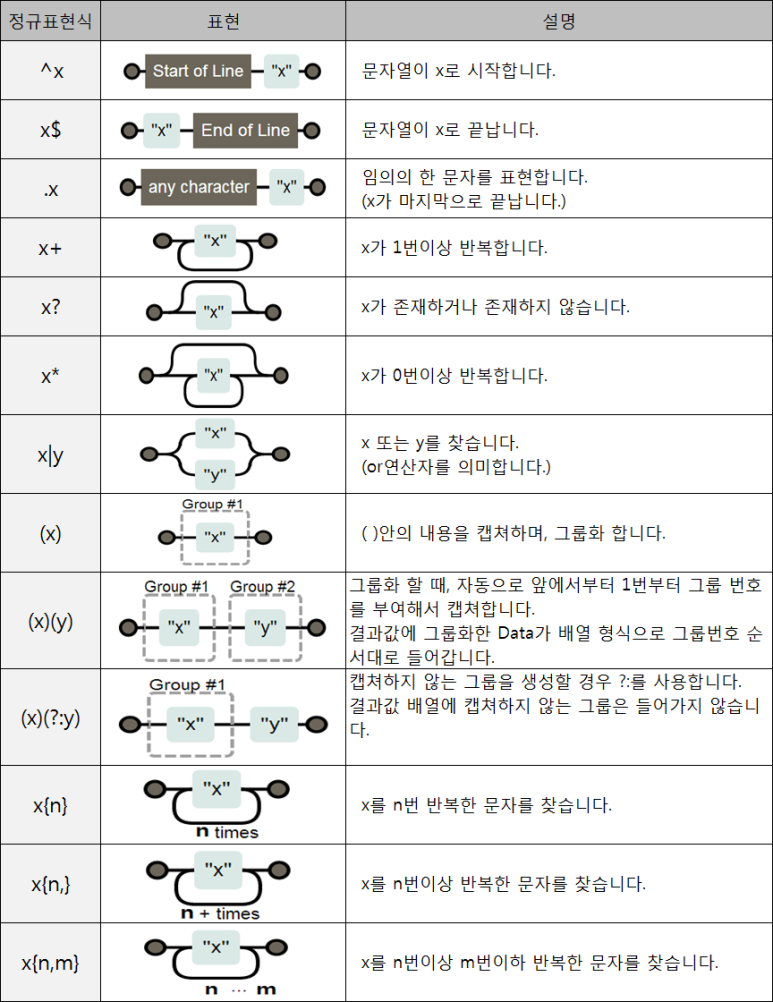
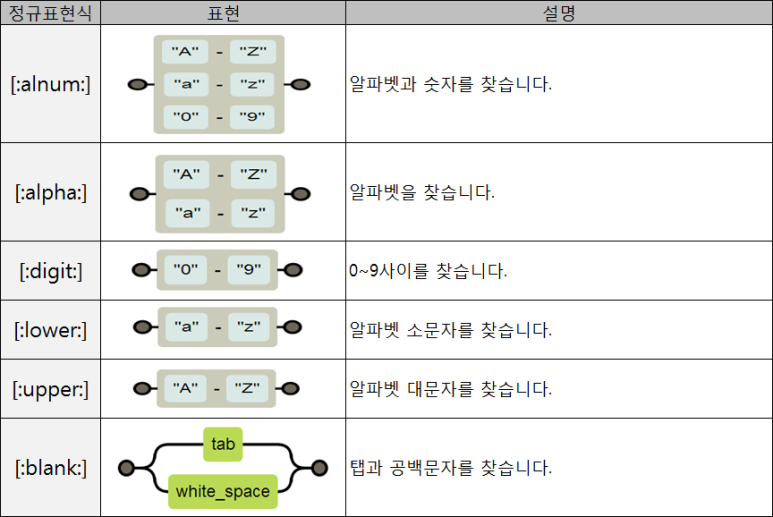
반면, POSIX에서만 사용하는 문자클래스는 아래와 같으며, 붙어있는 모양 자체가 표현식이기 때문에 실제로 문자클래스로 사용할 때에는 대괄호를 씌워서 사용해한다.
파이썬에서 정규표현식을 쓰기 위해서는 re 모듈을 임포트해서 사용해야한다. 예시로 아래의 예제를 실행해보자.
[Python Code]
import re
result = re.match('You', 'Young Frankenstein')
print(result)
[실행결과]
<re.Match object; span=(0, 3), match='You'>
위의 코드에서 ‘You’ 문자열이 패턴이고, ‘Young Frankenstein’ 이 입력으로 사용된 문자열이다. 만약 찾고자 하는 패턴의 문자열이 입력 문자열 내에 존재한다면, 사용된 함수의 반환값을 반환해준다.
위의 예제에서 사용된 match() 함수는 패턴이 정확하게 일치하는 지, 일치하면 패턴이 포함된 문자열의 시작부분과 패턴이 존재하는 부분까지의 인덱스를 반환해준다.
추가적으로 패턴 확인을 빠르게 할 수 있도록, 찾으려는 패턴을 먼저 컴파일 할 수도 있다.
[Python Code]
pattern = re.compile("You")
result = re.match(pattern, 'Young Frankenstein')
print(result)
[실행결과]
<re.Match object; span=(0, 3), match='You'>
2) 관련 함수
이번에는 정규표현식을 사용하기 위한 함수들을 살펴보자. 주요 함수들은 다음과 같다.
(1) match()
앞선 예제에서도 등장했던 함수로, 시작부터 완벽하게 일치하는 패턴을 찾고자 할 때 사용하는 함수이다. 만약 찾으려는 패턴이 입력 문자열 내에 존재한다면, 시작위치에서 패턴까지의 인덱스를 반환해준다. 만약 시작위치부터 패턴이 존재하지 않는다면 아무것도 반환하지 않는다.
[Python Code]
result = re.match("Frank", 'Young Frankenstein')
print(result)
[실행결과]
None
(2) search()
앞서 본 match() 와 유사하게 주어진 패턴을 찾는 함수지만, 차이점이 있다면, match() 함수의 경우, 처음부터 패턴이 존재해야만 결과를 반환해주는 데 비해, search() 함수는 시작위치에 상관없이 주어진 입력 문자열 내에 찾으려는 패턴이 존재하면, 해당 패턴의 시작 인덱스와 종료 인덱스를 반환해준다.
[Python Code]
result = re.search("Frank", 'Young Frankenstein')
print(result)
[실행결과]
<re.Match object; span=(6, 11), match='Frank'>
(3) findall()
만약 찾아야 되는 패턴을 여러 개 찾는 경우라면 어떨까? match() 나 search() 함수는 1개만 찾아주기 때문에, 여러 개를 찾는 것은 무리가 있다. 이러한 문제에서 사용할 수 있는 함수가 findall() 함수다. findall() 은 일치하는 패턴을 입력문자열에 여러 개 존재한다면, 모두 반환해준다. 구체적으로 확인하기 위해 아래의 예제를 실행해보자.
[Python Code]
result = re.findall('n', 'Young Frankenstein')
print(result)
[실행결과]
['n', 'n', 'n', 'n']
(4) split()
입력 문자열을 특정 패턴으로 나누고 싶을 때 사용하는 함수이며, 패턴이 존재하는 위치를 기점으로 문자열을 리스트로 나눈다.
[Python Code]
result = re.split('n', 'Young Frankenstein')
print(result)
[실행결과]
['You', 'g Fra', 'ke', 'stei', '']
(5) sub()
입력 문자열에서 패턴에 해당하는 부분을 다른 문자열로 치환하고자 할 때 사용하는 함수이며, replace() 메소드와 비슷하지만, 문자열이 아닌 패턴을 사용한다는 점에서 차이가 있다.
[Python Code]
result = re.sub('n', 'N', 'Young Frankenstein')
print(result)
[실행결과]
YouNg FraNkeNsteiN
3. 이진 데이터
이진 데이터는 0과 1로 구성된 데이터이며, 텍스트 데이터 보다 다루기 어려울 수 있다. 우선 이진 데이터를 알려면, 먼저 엔디안 과 정수에 대한 사인 비트 등의 개념과 데이터를 추출, 변경하는 바이너리 파일 형식, 네트워크 패킷 등에 대한 지식도 필요하다.
1) 바이트와 바이트 배열
파이썬 3에서 제공되는 이진데이터 형태는 바이트와 바이트 배열 2가지가 존재하며, 0 ~ 255 범위에서 사용할 수 있는 8비트 정수 시퀀스이다. 둘의 차이점으로는, 바이트 형은 튜플과 같이 불변이지만, 바이트 배열은 리스트와 같이 변경 가능하다는 점이다. 위의 내용을 확인하기 위해서 아래 예제를 같이 살펴보자.
[Python Code]
input = [1, 2, 3, 255]
i_bytes = bytes(input)
print(i_bytes)
array_bytes = bytearray(input)
array_bytes
[실행결과]
b'\x01\x02\x03\xff'
bytearray(b'\x01\x02\x03\xff')
위의 예제를 보면 입력데이터에 대해 바이트형으로 만들고 싶다면, bytes() 함수를 사용하면 되고, 바이트 배열을 만들고 싶다면, bytearray() 함수를 사용하면 된다. 다음으로 바이트 타입과 바이트 배열 타입의 값 수정 여부를 확인해보자.
[Python Code]
i_bytes[1] = 127 # 에러
array_bytes[1] = 127
array_bytes
[실행결과]
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'bytes' object does not support item assignment
bytearray(b'\x01\x7f\x03\xff')
두번째 예제에서처럼 바이트 형은 변경하려 했을 때, 변경이 불가하다는 에러 메세지가 출력됬지만, 바이트 배열의 경우에는 배열 값을 변경할 수 있다.
세번째로 확인할 것은 값의 표현 범위이다. 앞서 언급한 것처럼 0~255까지 표현 가능한지를 아래 예제로 확인해보자.
[Python Code]
i_bytes = bytes(range(0, 256))
array_bytes = bytearray(range(0, 256))
i_bytes
array_bytes
[실행결과]
b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff'
bytearray(b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff')
2) 이진 데이터 변환하기 : struct
지금부터 볼 struct 는 C 나 C++의 구조체와 유사하게 데이터를 처리하는 모듈이다. struct를 사용하ㅓ면 이진 데이터를 파이썬 데이터 구조로 바꾸거나 파이썬 데이터 구조를 이진 데이터로 바꿀 수 있다.
예제를 위해 아래에 나온 바이트 데이터를 읽어서 이미지에 대한 정보를 출력하는 코드를 구현해보자.
[Python Code]
import struct
valid_png_header = b'\x89PNG\r\n\x1a\n'
data = b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR' + \
b'\x00\x00\x00\x9a\x00\x00\x00\x8d\x08\x02\x00\x00\x00\xc0'
if data[:8] == valid_png_header:
width, height = struct.unpack('>LL', data[16:24])
print('Valid PNG, width', width, 'height', height)
else:
print('Not a valid PNG')
[실행결과]
Valid PNG, width 154 height 141
위의 코드를 살펴보면, 먼저 data 변수에 할당되는 값은 예제 이미지 파일의 첫 30 바이트를 표현한 것이다.
두번째로 valid_png_header 는 png 파일의 시작을 표시하는 8바이트 시퀀스를 의미한다. 세번째로 주목할 점은 unpack() 함수인데, 앞서 본 pack() 함수가 파이썬 데이터를 바이트로 변환하는 함수라면, 이와 반대로, 바이트 데이터를 파이썬에서 읽을 수 있는 데이터로 변환하는 함수라고 할 수 있다.
위의 코드 상에서는 >LL 은 입력한 바이트 시퀀스를 해석하고, 파이썬의 데이터 형식으로 변환해주는 형식 문자열이다.
우선 > 는 정수를 빅엔디안 형식으로 저장한다는 의미이며, L 은 4바이트의 부호 없는 긴 정수 (unsigned long integer) 를 지정한다는 뜻이다. 이해를 돕기 위해 각 4바이트 값을 직접 살펴보자.
[Python Code]
data[16:20]
data[20:24]
0x9a
0x8d
struct.unpack('>2L', data[16:24])
struct.unpack('>L', data[16:20])
struct.unpack('>L', data[20:24])
[실행 결과]
b'\x00\x00\x00\x9a'
b'\x00\x00\x00\x8d'
154
141
(154, 141)
(154,)
(141,)
추가적으로 형식지정자에 대해 궁금한 사람을 위해 아래의 표와 같이 정리해보았다.
| 지정자 | 설명 | 바이트 |
|---|---|---|
| < | 리틀엔디안 | - |
| > | 빅엔디안 | - |
| x | 1 바이트 건너뜀 | 1 |
| b | 부호 있는 바이트 | 1 |
| B | 부호 없는 바이트 | 1 |
| h | 부호 있는 짧은 정수 | 2 |
| H | 부호 없는 짧은 정수 | 2 |
| i | 부호 있는 정수 | 4 |
| I | 부호 없는 정수 | 4 |
| l | 부호 있는 긴 정수 | 4 |
| L | 부호 없는 긴 정수 | 4 |
| Q | 부호 없는 아주 긴 정수 | 8 |
| f | 단정도 부동소수점 | 4 |
| d | 배정도 부동소수점 | 8 |
| p | 문자수(count) 와 문자 | 1 + count |
| s | 문자 | count |
댓글남기기