
[Java] 5. 참조 타입

1. 참조타입
Java에 객체(Object)의 번지를 참조하는 타입으로 배열, 열거, 클래스, 인터페이스 타입을 의미한다. 선언된 변수는 메모리의 번지를 값으로 갖는다.
일반적으로, 변수는 스택(stack) 영역에, 객체는 힙(heap) 영역에 생성된다.
2. 메모리 사용 영역
JVM은 운영체제에서 할당받은 메모리 영역(Runtime Data Area)을 아래 그림과 같이 세부 영역으로 구분해서 사용한다.
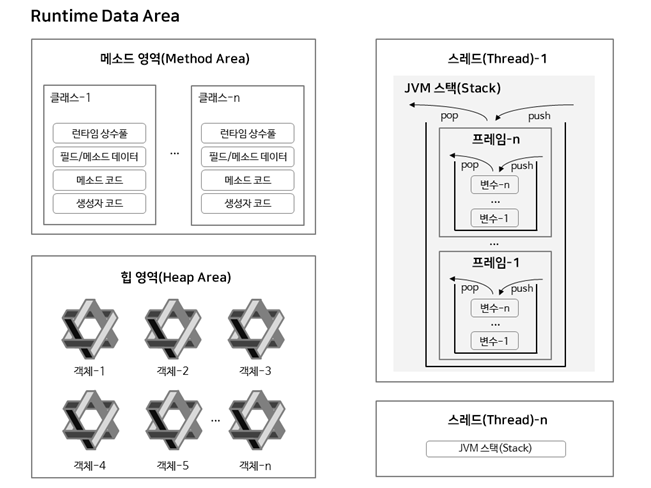
1) 메소드 영역
코드에서 사용되는 클래스(.class) 들을 클래스 로더로 읽어 클래스별로 런타임 상수 풀, 필드 데이터, 메소드 데이터, 메소드 코드, 생성자 코드 등을 분류해서 저장한다. 해당 영역은 JVM이 시작할 때 생성되어 모든 스레드가 공유하는 영역이기도 하다.
2) 힙 영억
객체와 배열이 생성되는 영역으로 생성된 객체와 배열은 JVM 스택 영역의 변수나 다른 객체의 필드에서 참조한다. 참조되는 변수나 필드가 없는 경우, 의미없는 변수가 되기 때문에 쓰레기 수집기(Garbage Collector)를 실행해 자동으로 제거한다.
3) JVM 스택 영역
각 스레드마다 하나씩 존재하며 스레드가 시작될 때 할당된다. 스택은 메소드를 호출할 때마다 프레임을 추가하고 메소드가 종료되면 해당 프레임을 제거하는 동작을 수행한다. 만약 예외 발생 시 printStackTrace() 메소드를 사용해 Stack Trace의 각 라인을 하나의 프레임으로 표현한다. 프레임 내부에는 로컬변수 스택이 있는데, 기본 타입 변수와 참조 타입 변수가 추가되거나 제거되는 부분이다. 변수가 스택 영역에 최초로 생성되는 시점은 초기화, 즉, 최초로 변수에 값이 저장될 때이다.
3. 참조 변수의 연산
기본 타입 변수에서 == 과 != 연산은 변수 값이 같은지의 여부를 확인하지만, 참조 타입 변수들 간에 ==, != 연산은 동일한 객체를 참조하는 지를 알아볼 때 사용된다. 앞서 언급한 것처럼 참조 타입 변수의 값은 힙 영역의 객체 주소이기 때문에, == 과 != 연산은 결과적으로 주소 값이 같은지를 보는 것으로 된다는 의미이다. 따라서 동일한 객체를 참조한다면 True, 아니면 False 를 반환한다.
4. NULL 과 NullPointerException
참조 타입 변수는 힙 영역의 객체를 참조하지 않는다는 의미로 NULL 을 사용한다. 초기값으로도 사용할 수 있기 때문에 NULL 로 초기화된 참조 변수들의 경우에는 스택 영역에 생성된다. NullPointerException 은 실행도중 발생하는 에러인 예외(Exception)의 한 종류이다. 여기서의 예외는 사용자가 입력값을 잘못 넣은 경우나, 프로그래머가 코드를 잘못 작성해서 발생할 수 있다. 그 중 NullPointerException은 참조 타입 변수가 잘못 사용되면 발생하는 예외이며, 참조 타입 변수가 null을 갖고 있는 경우, 참조 타입 변수는 사용할 수 없다. 참조 타입 변수를 사용한다는 의미는 객체를 사용한다는 의미인데, 참조할 객체가 없기 때문에 사용할 수 없다는 예외가 발생한 것이다.
5. String 타입
Java 에서 문자열을 저장하기 위해서는 String 변수를 먼저 선언해야된다. 문자열을 변수에 저장하기 위해서는 큰 따옴표(“ “)로 감싼 문자열 리터럴을 대입하면 된다. 다른 변수 타입과 유사하게 문자열 역시 변수 선언과 문자열 저장을 동시에 할 수 있다.
// 선언과 문자열 저장을 각각하는 경우
String var1;
var1 = "Kim";
// 선언과 문자열 저장을 동시에 저장
String var2 = "Kim";
하지만 구체적으로 저장되는 과정을 살펴보면, 변수에 저장된다기 보단, 문자열은 String 객체로 생성되고, 변수는 String 객체를 참조한다.
일반적으로 변수에 문자열을 저장하는 경우에는 문자열 리터럴을 사용하지만 new 연산자를 사용해서 직접 String 객체를 생성할 수도 있다.
String name1 = new String("Kim");
String name2 = new String("Kim");
위의 경우에는 서로 다른 String 객체를 참고한다. 하지만 문자열 리터럴로 생성되는 경우 동일한 객체를 참고하게 된다. 앞서 본 == 연산으로 비교해보면 String 객체를 직접 생성했을 때의 결과는 서로 주소 값이 다르지만, 문자열 리터럴로 생성된 주소는 모두 동일하다.
또한, 객체의 주소가 아닌, 문자열의 내용을 비교하고 싶은 경우에는 == 연산이 아니라, equals() 메소드를 사용해야한다. equals() 는 원본 문자열과 배개값으로 주어진 비교 문자열이 동일한지 비교한 후 true 또는 false를 반환한다. 사용법은 아래와 같다.
boolean result = name1.equals("Kim");
참조되지 않은 객체를 쓰레기 객체로 취급하고 쓰레기 수집기(Garbage Collector) 를 실행시켜 제거한다.
6. 배열 타입
같은 형식의 데이터를 여러 개 저장해야되는 경우에 사용하는 자료구조로, 같은 데이터 타입을 연속된 공간에 나열시키고, 각 데이터에 인덱스를 부여한 자료구조이다. 앞서 언급한 것처럼 같은 타입의 데이터만 저장할 수 있기 때문에, int 형이면 int 값만 가능하고, String 이라면 문자열 형식만 저장이 가능하다. 만약 다른 타입의 값을 저장하려고 하면, 타입 불일치(TypeMismatch) 컴파일 오류가 발생한다.
1) 선언
배열을 사용하기 위해서는 아래와 같이 크게 2가지 방식으로 선언할 수 있다.
[형식]
타입[] 변수명;
타입 변수명[];
int[] intArray1;
int intArray2[];
배열 역시 참조변수에 속하기 때문에 객체를 생성하면, 힙(Heap) 영역에 생성되고, 배열 변수는 힙 영역의 배열 객체를 참조하게 된다. 참조할 배열 객체가 없다면 NULL로 초기화 할 수 있다. 또한 다른 변수들과 동일하게 NULL을 가진 상태에서 변수명[인덱스] 형식으로 값을 읽거나 저장하게 되면 NullPointerException 이 발생한다.
다음으로 값을 대입할 경우를 살펴보자. 대입에 대한 것도 다른 변수들과 동일하게 변수 선언 후에 대입을 해도 되고, 선언과 동시에 값을 대입할 수 있다.
단, 한 가지 주의사항으로 변수 선언 후 중괄호를 사용한 배열의 생성은 서용되지 않는다. 대신 new 연산자를 사용해서 “new 타입[] {val1, val2, …}; “ 으로 사용하는 것은 가능하다.
int numArr[];
// numArr = {1, 2, 3, 4, 5}; (x)
numArr = new int[] {1, 2, 3, 4, 5}; (O)
만약, 값의 목록을 갖고 있지 않지만, 이 후에 값을 저장하기 위한 배열을 생성하려는 경우에는 new 연산자를 사용해서 아래와 같이 배열 객체를 생성한다.
타입[] 변수명 = new 타입[길이];
int[] numArr = new int[5];
new 연산자를 사용하여 배열을 생성하게 되면, 해당배열은 기본값으로 자동 초기화 된다. 위의 예시에서는 길이가 5인 int 형 배열을 선언했기 때문에, numArr[0] ~ numArr[5] 까지 전부 int 형의 기본값인 0으로 초기화된다.
참고사항으로 각 타입별 초기값은 아래의 표와 같다.
| 분류 | 데이터 타입 | 초기값 |
|---|---|---|
| 정수 | byte[] char[] short[] int[] long[] |
0 “\u0000” 0 0 0 |
2) 배열 길이
배열의 길이는 배열에 저장할 수 있는 값의 개수와 동일하다. 배열의 경우 length 필드에 길이를 저장하고 있으며, 객체 내부 데이터인 필드이기 때문에 객체.length 로 길이 값을 가져올 수 있다.
int numArr = {1, 2, 3, 4, 5};
System.out.println(numArr.length);
5
활용할 수 있는 부분은 주로 반복문, 특히 for 문과 같이 사용되는 경우가 많다.
public class ArrayTest {
public static void main(String[] args)
{
int[] arr1 = {1, 2, 3};
int sum = 0;
for(int i = 0; i < arr1.length; i++)
{
sum += arr1[i];
}
System.out.println("총합 : " + sum);
}
}
[실행결과]
총합 : 6
for 조건식에서 배열 길이 미만으로 조건을 잡은 이유는 배열의 인덱스 시작 값이 0 이기 때문에 마지막 인덱스 값은 실제 길이 보다 1 작은 값이 된다. 만약 인덱스를 초과해서 사용하게 되면, ArrayIndexOutOfBoundsException 이 발생한다.
3) 커멘드 라인 입력
main 함수를 선언할 때, 매개변수 부분을 살펴보면 String[] args 로 선언하는 것을 확인할 수 있다. 해당 클래스명으로 프로그램을 실행하게되면, JVM은 길이가 0인 문자열 배열을 먼저 생성하고 main() 메소드를 호출할 때 매개값으로 전달한다.
만약 main 함수 선언 전에 전역변수로 String[] args를 선언해주고 실행할 경우, 문자열 목록으로 구성된 String[] 배열이 생성되고 main() 메소드를 호출할 때 매개값으로 전달된다.
main 메소드는 String[] args를 통해 커맨드 라인에서 입력된 데이터의 수와 입력된 데이터를 알 수 있게 된다.
예시로 아래 코드를 실행해보자.
public class ArrayArgument {
public static void main(String[] args)
{
if(args.length != 2)
{
System.out.println("프로그램 사용법");
System.out.println("java ArrayArgument num1 num2");
System.exit(0);
}
String strNum1 = args[0];
String strNum2 = args[1];
int num1 = Integer.parseInt(strNum1);
int num2 = Integer.parseInt(strNum2);
int result = num1 + num2;
System.out.println(num1 + " + " + num2 + " = " + result);
}
}
[실행결과]
10 + 20 = 30
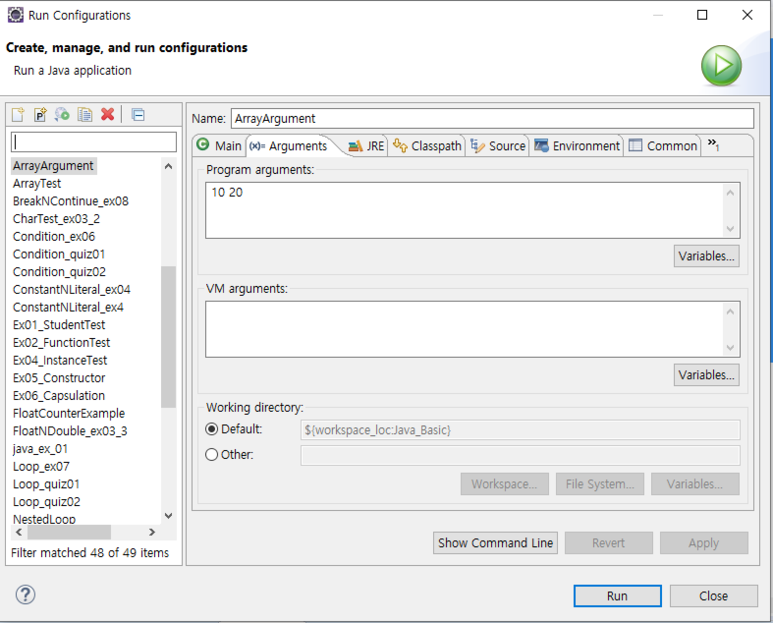
cmd로 실행하는 경우에는 java ArrayArgument 10 20 으로 실행하면되고, 이클립스 내에서 실행할 경우, Run - Run Configuration 의 Argument 탭에 10 20 으로 매개값을 넣어 준 후에 실행하면 된다.
위에서 배운 내용을 이용해 아래에 준비한 간단한 퀴즈를 풀어보자. 문제는 다음과 같다.
[Quiz]
1. 대문자를 A-Z까지 배열에 저장하고 이를 다시 출력하는 프로그램을 생성하시오.
2. 아래의 내용을 프로그래밍 하시오
- Lee 학생은 국어, 수학 2과목을 수강하고, Kim 학생은 국어, 수학, 영어 3과목을 수강한다.
- Lee 는 국어 100점, 수학 90점을 맞혔고, Kim 은 국어 100점, 수학 90점, 영어 80점을 맞혔다.
이 때, 위의 내용을 ArrayList 멤버변수 1개로 구현하고 결과를 출력하시오.
4) 배열 복사
말 그대로 특정 배열에 존재하는 내용을 다른 배열에도 동일한 길이와 동일한 값을 갖도록 대입하는 것을 의미한다.
Java 에서는 객체를 복사하는 유형으로 앝은 복사와 깊은 복사가 있다.
먼저, 얕은 복사란, 단순히 객체의 주소 값만 복사하는 방식을 의미하며, 복사된 배열이나 원본배열이 변경될 때
서로 간의 값의 위치는 변경된다. 반면, 깊은 복사란 객체의 실제값을 새로운 객체로 복사하는 것을 의미하며, 복사된 배열이나 원본배열이 변경되더라도, 서로의 값은 바뀌지 않는다.
배열을 복사할 때는 배열객체에 존재하는 arraycopy() 메소드를 사용한다. 해당 메소드에 대한 구성은 아래와 같다.
System.arraycopy(원본배열객체, scope1, 복사대상객체, scope2, step)
// 원본배열객체의 scope1 번째 부터 step 개의 요소를 복사대상객체의 scope2 번째 위치부터 step 개만큼 복사함
내용에 대한 이해를 돕기 위해 아래의 코드를 살펴보자.
public class ex09_3_ArrayCopy {
public static void main(String[] args)
{
int[] arr1 = {1, 2, 3, 4, 5};
int[] arr2 = {10, 20, 30, 40, 50};
for(int i = 0; i < arr2.length; i++)
{
System.out.println(arr2[i]);
}
System.out.println();
System.arraycopy(arr1, 0, arr2, 1, 3);
// 결과 확인
for(int i = 0; i < arr2.length; i++)
{
System.out.println(arr2[i]);
}
}
}
[실행 결과]
10
20
30
40
50
10
1
2
3
50
위의 코드를 살펴보면, 본래 arr2 배열 객체는 10~50까지 5개의 요소를 갖고있다.
하지만, arraycopy() 메소드를 통해 arr1 의 0~2 번 인덱스의 값을 arr2 의 1~3번까지의 인덱스에 복사했기 때문에 arraycopy() 가 수행된 이후에는 1~3번 인덱스에는 각각 1, 2, 3이 채워진 것이다.
위의 내용과 비슷하게 아래의 코드도 한번 살펴보자.
public class ex09_4_ObjectArrayCopy {
public static void main(String[] args)
{
Book[] library = new Book[5];
Book[] copyLib = new Book[5];
// 반드시 assign 을 해줘야 한다.
library[0] = new Book("Harry Potter1", "J.K Rolling");
library[1] = new Book("Harry Potter2", "J.K Rolling");
library[2] = new Book("Harry Potter3", "J.K Rolling");
library[3] = new Book("Harry Potter4", "J.K Rolling");
library[4] = new Book("Harry Potter5", "J.K Rolling");
System.arraycopy(library, 0, copyLib, 0, 5);
for (int i = 0; i < copyLib.length; i++)
{
System.out.println(library[i]);
}
System.out.println();
for (int i = 0; i < copyLib.length; i++)
{
System.out.println(copyLib[i]);
}
System.out.println();
// 향상된 for 문
for (Book book : copyLib)
{
book.showBookInfo();
}
System.out.println();
// 얖은 복사
library[0].setAuthor("조정래");
library[0].setTitle("태백산맥");
for (Book book : copyLib)
{
book.showBookInfo();
}
System.out.println();
// 깊은 복사
for(int i = 0; i < copyLib.length; i++)
{
if(i == 0)
{
copyLib[0] = new Book("Sherlock", "Auther Conan Doyle");
}
else
{
copyLib[i] = new Book(library[i].getTitle(), library[i].getAuthor());
}
}
for (Book book : copyLib)
{
book.showBookInfo();
}
}
}
[실행결과]
com.java.kilhyun.OOP.Book@1b6d3586
com.java.kilhyun.OOP.Book@4554617c
com.java.kilhyun.OOP.Book@74a14482
com.java.kilhyun.OOP.Book@1540e19d
com.java.kilhyun.OOP.Book@677327b6
com.java.kilhyun.OOP.Book@1b6d3586
com.java.kilhyun.OOP.Book@4554617c
com.java.kilhyun.OOP.Book@74a14482
com.java.kilhyun.OOP.Book@1540e19d
com.java.kilhyun.OOP.Book@677327b6
Harry Potter1, J.K Rolling
Harry Potter2, J.K Rolling
Harry Potter3, J.K Rolling
Harry Potter4, J.K Rolling
Harry Potter5, J.K Rolling
태백산맥, 조정래
Harry Potter2, J.K Rolling
Harry Potter3, J.K Rolling
Harry Potter4, J.K Rolling
Harry Potter5, J.K Rolling
Sherlock, Auther Conan Doyle
Harry Potter2, J.K Rolling
Harry Potter3, J.K Rolling
Harry Potter4, J.K Rolling
Harry Potter5, J.K Rolling
위의 내용을 보면 저자와 저자에 대한 책을 관리하기 위한 코드라고 볼 수 있다. 가장 먼저 해리포터 1~5권과 저자인 J.K 롤링에 대한 정보를 library 배열객체에 넣어 생성하였다. 이를 copyLib 배열에 복사를 하고서 원본배열인 library 에 존재하는 객체의 주소와 copyLib 에 존재하는 객체의 주소를 출력해 비교해본다. 이는 실행결과를 통해서 알 수 있듯이, 얕은 복사이며, 이유는 5개의 객체에 대한 주소가 원본과 복사본 모두 동일한 것을 알 수 있기 때문이다.
반면 깊은 복사의 경우에는 객체의 값을 직접 다른 객체에 입력하는 방식이며, 이를 확인하기 위해 sherlock 과 저자인 아서 코난 도일을 복사 배열의 0번째 인덱스에 새로 할당하였다. 앞서 주소를 비교한 것처럼 수정 후 확인해보면 아래와 같이 0번째 인덱스의 주소가 바뀐것을 확인할 수 있다.
[실행결과]
com.java.kilhyun.OOP.Book@1b6d3586
com.java.kilhyun.OOP.Book@4554617c
com.java.kilhyun.OOP.Book@74a14482
com.java.kilhyun.OOP.Book@1540e19d
com.java.kilhyun.OOP.Book@677327b6
com.java.kilhyun.OOP.Book@14ae5a5
com.java.kilhyun.OOP.Book@7f31245a
com.java.kilhyun.OOP.Book@6d6f6e28
com.java.kilhyun.OOP.Book@135fbaa4
com.java.kilhyun.OOP.Book@45ee12a7
5) 다차원 배열
지금까지 살펴본 배열의 내용은 모두 1차원 배열에 대한 내용이다. 이와 달리 값을 행, 열의 형태로 구성된 배열을 2차원, 정확히는 다차원 배열이라고 부른다. 다차원 배열을 사용하는 주요 목적은 공간을 구현하기 위해서 사용할 배열이 필요했기 때문이다.
선언 방식은 1차원일때와 비슷한데, 차이점은 반드시 행, 열 순서로 인덱스를 사용해야한다. 자바의 경우 다차원 배열을 구현할 때는 중첩배열방식으로 구현된다. 예를 들어 2차원 배열을 생성한다라고 하면, 아래 코드와 같이 생성하면 된다.
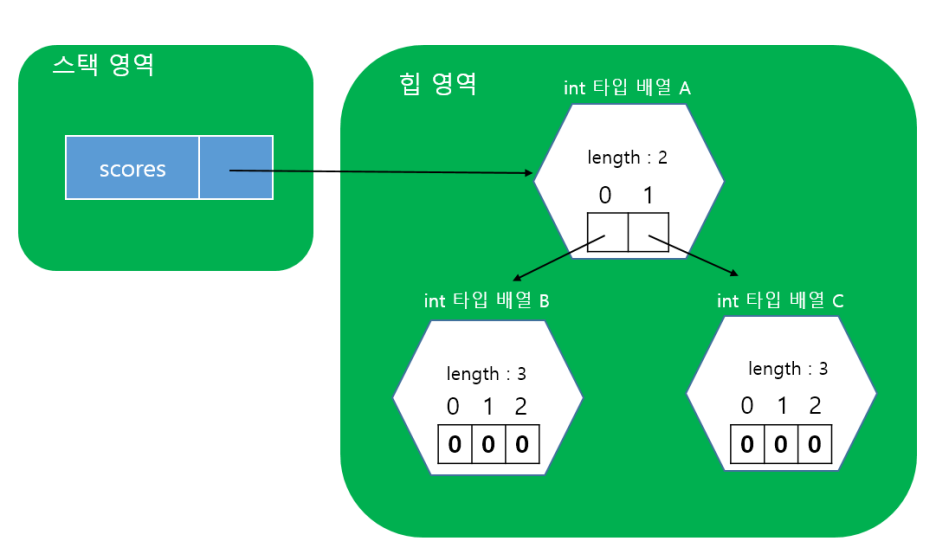
int[][] score = new int[2][3];
위의 코드를 메모리상으로 보게 되면 스택 영역에는 score 라는 변수와 그에 대한 주소값이 저장되고, 저장되는 주소값은 실제 힙영역에 생성된 배열인데, 이 배열에는 다시 행별로 1차원 배열의 주소값이 저장된다.
위의 코드를 예로 들자면, 아래 그림과 같이 총 3개의 배열이 생성되며, 스택영역의 score에 저장되는 주소값은 힙영역에 생성된 배열 A의 주소값이 저장된다. 다시 힙영역의 배열 A에는 각 행에 대한 인덱스에 주소값이 저장되며, 0번째 인덱스에는 0번 행에 대응되는 배열 B의 주소값이, 1번째 인덱스에는 1번 행에 대응되는 배열 C의 주소값이 각각 대입되는 것이다.
앞서 1차원 배열도 마찬가지이지만, 배열을 사용할 때에는 반드시 정확한 배열의 길이를 알고 인덱스를 사용해야하며, 이를 어길 경우, ArrayIndexOutOfBoundsException 을 발생시킨다. 다차원 배열의 내용을 확인하기 위해 대표적으로 사용되는 2차원 배열을 생성하고 사용하는 방법에 대한 코드를 확인해보자.
public class ex09_5_NDimArray {
public static void main(String[] args)
{
int[][] arr = new int[2][3];
// 선언과 동시에 초기화하기
int[][] arr2 = {
{1,2,3},
{4,5,6}
};
System.out.println(arr2.length); // 행의 개수를 출력함
System.out.println(arr2[0].length); // 1번째 행의 개수를 출력함
System.out.println();
for(int i = 0; i < arr2.length; i++)
{
for(int j = 0; j < arr2[i].length; j++)
System.out.println(arr2[i][j] + " ");
System.out.println();
}
}
}
[실행 결과]
2
3
1
2
3
4
5
6
6) ArrayList
ArrayList 는 List 인터페이스를 상속받은 클래스로, 크기가 가변적으로 변하는 선형리스트이다. 일반적인 배열과 같은 순차형 리스트이고, 인덱스를 이용해서 내부의 객체를 관리한다는 점이 유사하지만, 배열과 달리 객체들이 추가되어 저장용량을 초과하면 자동으로 부족한 크기만큼 저장용량이 증가하는 특징을 갖는다. 사용할 때는 java.util.ArrayList 패키지를 import 해서 사용한다. 해당 패키지안에는 객체 배열을 사용하는데 필요한 여러 메소드들이 구현되어있으며, 가장 많이 접하게 될 메소드는 아래와 같다.
- add()
- size()
- get()
- remove()
- isEmpty()
더 자세한 내용은 컬렉션에서 다시 한 번 언급할 예정이므로 우선 이정도만 알고 넘어가자. 사용은 아래와 같이 사용하면된다.
public class ex09_6_ArrayListTest {
public static void main(String[] args)
{
ArrayList<String> list = new ArrayList<String>();
// 제너릭 (<> 안의 내용) 을 선언하지 않으면, 모든 형식의 데이터를 사용할 수 있으나
// 이 후 요소를 사용하는 과정에서 반드시 형변환을 해줘야하는 번거로움이 존재함
list.add("ghKim"); // 객체 추가 시 사용
list.add("slykid");
for(int i = 0; i < list.size(); i++)
System.out.println(list.get(i)); // ArrayList에 저장된 객체를 가져올 때 사용
System.out.println();
// 향상된 for 문
for(String s : list)
{
System.out.println(s);
}
System.out.println();
}
}
[실행 결과]
ghKim
slykid
ghKim
slykid
7. 열거 타입
데이터 중 한정된 몇 개의 값만을 갖는 데이터 타입을 의미하며, 몇 개의 열거 상수 중에서 하나의 상수를 저장하는 데이터 타입이다.
1) 열거 타입 선언
열거 타입 선언을 위해 타입의 이름과 동일한 이름의 .java 파일을 생성해 줘야 한다. 관례적으로 첫 문자는 대문자로 하고 나머지는 소문자로 구성한다. 복수의 단어 조합인 경우 각 단어의 첫 문자는 대문자, 나머지는 소문자로 작성한다.
열거 타입은 public enum [열거타입명] 으로 작성한다. 이 때 열거타입명은 반드시 파일명과 동일한 이름으로 작성한다. 선언부 내에는 모두 대문자로 표기하는 것이 관례이다.
public enum Week
{
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY
}
만약 열거 상수가 복수 개의 단어 조합으로 구성된다면, 단어 사이에 _ (밑줄)을 그어 연결하는 방식으로 작성한다.
2) 열거형 변수
열거 타입도 하나의 데이터 타입이기 때문에, 다른 변수들의 생성방법과 동일하게 선언 후에 사용이 가능하다.
선언 방식은 아래와 같다.
Week today;
열거 타입 또한 참조 타입의 변수에 속하기 때문에, NULL을 저장할 수 있다.
Week birthday = null;
3) 열거 객체의 메소드
앞서 언급한 대로 열거 객체는 열거상수의 문자열을 필드(내부 데이터)로서 가지고 있다. 해당 클래스는 java.lang.Enum 클래스를 상속하기 때문에 Enum 에 속해있는 모든 메소드 역시 사용가능하다.
메소드에 대한 내용은 다음과 같다,
(1) name()
열거 객체가 갖고 있는 문자열을 리턴한다. 이 때 반환되는 문자열은 열거 타입을 정의할 때 사용한 상수 명과 동일하다.
Week today = Week.SUNDAY;
String dayName = today.name();
(2) ordinal()
전체 열거 객체 중 몇 번째 열거 객체인지를 반환해준다. 열거 객체의 순번은 열거타입을 정의할 때 주어진 순번을 의미하며, 0번 부터 시작된다.
Week today = Week.SUNDAY;
int ordinalNum = today.ordinal();
(3) compareTo()
매개값으로 주어진 열거 객체를 기준으로 전후로 몇 번째에 위치하는 지를 비교한다. 만약, 열거 객체가 매개값의 열거 객체보다 앞쪽에 위치하면 음수를, 뒤쪽에 위치하면 양수를 반환한다.
Week day1 = Week.SUNDAY;
Week day2 = Week.MONDAY;
int res1 = day1.compareTo(day2);
int res2 = day2.compareTo(day1);
(4) values()
열거 타입의 모든 열거 객체들을 배열로 반환해준다.
Week[] days = Week.values()
for(Week day : days)
{
System.out.println(day);
}
(5) valueOf()
매개값으로 주어지는 문자열과 동일한 문자열을 가지는 열거 객체를 반환한다. 주로 외부 문자열을 입력으로 받아 열거 객체로 변환하는 경우에 많이 사용된다.
Week weekDay = Week.valueOf("SATURDAY");
위에서 살펴본 메소드를 실제로 사용해보자.
[Java Code - Week.java]
public enum Week
{
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY
}
[Java Code - EnumMethodExmaple.java]
public class EnumMethodExample
{
public static void main(String[] args)
{
Week today = Week.SUNDAY;
// name()
String name = today.name();
System.out.println(name);
// ordinal()
int ordinal = today.ordinal();
System.out.println(ordinal);
// compareTo()
Week day1 = Week.MONDAY;
Week day2 = Week.TUESDAY;
int result1 = day1.compareTo(day2);
int result2 = day2.compareTo(day1);
System.out.println(result1);
System.out.println(result2);
// valueOf()
if(args.length == 1)
{
String strDay = args[0];
Week weekDay = Week.valueOf(strDay);
if(weekDay == Week.SATURDAY || weekDay == Week.SUNDAY)
{
System.out.println("주말 입니다.");
}
else
{
System.out.println("평일 입니다.");
}
}
// values()
Week[] days = Week.values();
for(Week day : days)
{
System.out.println(day);
}
}
}
댓글남기기