
[Java] 33. 병렬 처리 (Parallel Operation)

1. 병렬처리
병렬처리 (Parallel Operation) 란, 멀티코어 CPU 환경에서 하나의 작업을 분할해 각각의 코어가 병렬적으로 처리하는 것을 의미한다. 병렬처리를 해주는 이유는 주로 작업 처리시간을 줄이는 것이 목표이며, 자바 8 부터는 요소를 병렬처리할 수 있도록 병렬 스트림을 제공하기 때문에 컬렉션(배열) 의 전체적인 요소 처리 시간을 단축시켜준다.
1) 동시성과 병렬성 (Concurrency & Parallelism)
병렬처리는 기본적으로 멀티 스레드로 실행되기 때문에, 위의 용어들에 대해서는 정확히 알아야한다. 참고로 스레드에 대해서는 다음장에서 다룰 예정이므로, 이번장에서는 일종의 작업 흐름 정도로 이해하면 될 것이다.
다시 돌아와서 설명하자면, 위의 2가지 특성은 멀티 스레드의 동작 방식이라는 점에서 동일하지만, 서로 다른 목적을 갖는다.
먼저 동시성은 멀티 작업을 위해 멀티 스레드가 교차하면서 실행하는 성질을 의미하고, 병렬성은 멀티 작업을 위해 멀티 코어를 이용해 동시에 실행하는 성질임을 의미한다. 이해를 돕기 위해 아래 그림과 같이 표현할 수 있다.
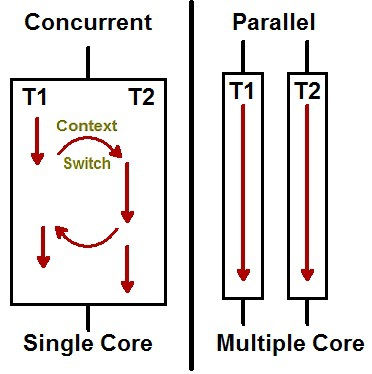
위의 그림에서처럼 싱글코어 CPU를 이용한 멀티작업에서는 병렬적으로 실행되는 것처럼 보여도, 실제론 매우 빠른 속도로 번갈아가면서 실행되는 작업이기 때문에 병렬성으로 보일 수 있지만, 위에서 설명한 것처럼 병렬성은 서로 다른 작업이 동시에 실행되는 것을 의미한다.
병렬성은 다시 데이터 병렬성과 작업 병렬성으로 나눌 수 있으며, 데이터 병렬성은 전체 데이터를 쪼개서 서브 데이터셋들로 만들고, 서브 데이터들을 병렬처리로 빠르게 작업 완료하는 것을 의미한다. 예를 들면, 쿼드 코어의 CPU를 사용할 경우, 4개의 서브요소들로 나눠서 4개의 스레드가 각각의 서브요소를 처리하는 작업이 있다.
반면, 작업 병렬성은 서로 완전히 다른 작업을 병렬로 처리하는 것을 의미한다. 대표적인 예로는 웹 서버와 같이 각 브라우저에서 요청한 내용을 개별 스레드에서 병렬적으로 처리하는 작업을 들 수 있다.
2) 포크/조인 프레임워크(Fork/Join Framework)
앞서 설명했듯이, 병렬 처리를 하기 위해서는 병렬로 스트림을 실행하게 되는데, 이를 수행하기 위해서 포크/조인 프레임워크라는 것을 사용한다.
크게 포크 단계와 조인 단계로 나눠져서 동작하는 프레임워크이며, 포크 단계는 전체 데이터를 여러 개의 서브 데이터들로 분리한 후, 서브 데이터를 멀티 코어에서 병렬로 처리한다. 조인 단계에서는 서브 결과를 결합 해 최종적인 결과를 생성하는 것으로 작업이 마무리된다.
만약 멀티 코어 CPU에서 병렬 스트림으로 작업을 처리한다고 가정해보자. 이 때, 스트림의 요소를 N개라고 했을 때, 포크 단계에서는 CPU의 코어 수 만큼 전체 요소를 분할한다. 그리고 1등분 씩 개별 코어에서 처리하고 조인 단계에서는 (코어 수 - 1) 번의 결합과정을 거쳐 최종 결과를 산출한다.

위의 그림에서처럼 병렬처리 스트림은 실제로 포크 단계에서 차례대로 요소를 4등분하지 않는다. 내부적으로 서브요소를 나눈 알고리즘이 있기 때문이며, 포크조인 프레임워크에서는 포크와 조인 기능 이외에 스레드풀인 ForkJoinPool 을 제공한다. 각 코어에서 서브 요소를 처리하는 것은 개별 스레드가 해야하므로 스레드 관리가 필요하다. 포크/조인 프레임워크는 ExecutorService의 구현객체인 ForkJoinPool을 사용해서 작업 스레드를 관리한다.
3) 병렬스트림 생성
그렇다면 병렬스트림을 직접 생성해보도록 하자. 병렬 처리를 위해 코드에소 포크/조인 프레임워크를 직접 사용할 수는 있지만, 병렬 스트림을 이용할 경우에는 백그라운드에서 포크/조인 프레임워크가 사용되기 때문에 쉽게 병렬처리를 구현할 수 있다. 생성은 다음과 같이 2가지 메소드를 이용해서 할 수 있다.
| 인터페이스 | 반환타입 | 메소드(매개변수) |
|---|---|---|
| java.util.Collection | Stream | parallelStream() |
| java.util.Stream.Stream java.util.Stream.IntStream java.util.Stream.LongStream java.util.Stream.DoubleStream |
Stream IntStream LongStream DoubleStream |
parallel() |
먼저 parallelStream() 메소드는 컬렉션으로부터 병렬 스트림을 바로 생성한다. 이에 반해 parallel() 메소드는 순차 처리 스트림을 병렬 처리 스트림으로 변환해서 반환한다.
위의 2가지 중 어떤 것을 사용하더라도 요소 처리 과정은 병렬로 처리한다. 내부적으로 전체 요소를 서브 요소들로 나누고, 각 서브요소들을 개별 스레드가 처리한다. 끝으로 서브 처리 결과가 나오면 결합해서 최종 처리 결과를 반환해준다.
동작원리를 확인하기 위해 앞선 장에서 만들었던 사용자 정의 컨테이너 예제를 병렬 스트림으로 수정해보자. 변경할 부분은 다음과 같다.
[Java Code - 변경 전]
MaleStudent maleStudent = totalList.stream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);
[Java Code - 변경 후]
MaleStudent maleStudent = totalList.parallelStream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);
위의 코드에서처럼 totalList.stream() 을 totalList.parallelStream() 과 같이 병렬스트림을 생성한다. 순차스트림으로 생성했을 때는 MaleStudent 객체는 하나만 생성되고 남학생만 수집하기 위해서 accumulate() 가 호출된다.
이를 병렬 스트림으로 생성하면 내부동작은 아래 순서와 같이 실행된다. (CPU는 쿼드 코어라고 가정한다.)
[병렬 스트림 실행 순서]
1. 전체 요소는 4개의 서브요소로 나눠지고 4개의 스레드가 생성되어 각각 병렬 처리한다.
이 때, 각 스레드는 서브 요소를 수집해야하므로 4개의 MaleStudent 객체를 생성하기 위해
collect() 메소드의 첫번째 메소드 참조인 MaleStudent :: new 를 4번 실행한다.
2. 각 스레드는 MaleStudent 객체에 남학생 요소를 수집하기 위해 MaleStudent :: accumulate 를
매번 실행한다.
3. 수집이 완료된 5개의 MaleStudent 객체에 4번의 결헙으로 최종 MaleStudent가 만들어지기 때문에
4번의 MaleStudent :: combine 이 실행된다.
전체 코드는 아래와 같다.
[Java Code]
import java.util.Arrays;
import java.util.List;
public class ParallelStreamTest {
public static void main(String[] args)
{
List<Student> totalList = Arrays.asList(
new Student("홍길동", 90, Student.Sex.MALE),
new Student("유재석", 100, Student.Sex.MALE),
new Student("송지효", 93, Student.Sex.FEMALE),
new Student("하동훈", 85, Student.Sex.MALE),
new Student("전소민", 85, Student.Sex.FEMALE)
);
MaleStudent maleStudent = totalList.parallelStream()
.filter(s -> s.getSex() == Student.Sex.MALE)
.collect(MaleStudent::new, MaleStudent::accumulate, MaleStudent::combine);
maleStudent.getList().stream()
.forEach(s -> System.out.println(s.getName()));
}
}
[실행 결과]
[ForkJoinPool.commonPool-worker-1] MaleStudent()
[ForkJoinPool.commonPool-worker-1] accumulate()
[ForkJoinPool.commonPool-worker-1] MaleStudent()
[ForkJoinPool.commonPool-worker-1] accumulate()
[ForkJoinPool.commonPool-worker-1] combine()
[ForkJoinPool.commonPool-worker-1] MaleStudent()
[ForkJoinPool.commonPool-worker-1] MaleStudent()
[ForkJoinPool.commonPool-worker-1] accumulate()
[ForkJoinPool.commonPool-worker-1] combine()
[main] MaleStudent()
[main] combine()
[main] combine()
홍길동
유재석
하동훈
위의 실행 결과에서는 main 스레드와 Fork/JoinPool 이 1개 스레드만 사용되어 총 2개의 스레드로 동작했다는 것을 알 수 있다. 만약 쿼드 코어의 CPU라면 main 스레드와 Fork/JoinPool스레드가 3개 사용되어 총 4개의 스레드로 동작할 것이다.
각각의 스레드가 하나의 서브작업이라고 했을 때, 위의 결과는 총 2개의 서브작업으로 분리되었다고 할 수 있다. 각 서브 작업은 남핵생을 누적시킬 MaleStudent 객체를 별도로 생성하기 때문에, MaleStudent 생성자가 총 5번 실행되었고, 이 중 남학생은 3명이였기 때문에 accumulate() 메소드는 총 3번 실행된다. 끝으로 누적이 완료된 MaleStudent 객체는 4번의 결합으로 이뤄져야하므로 combine() 메소드는 총 4번 실행된다.
댓글남기기