
[Hadoop] 1. 시작하면서 (개정 중)

1. Hadoop 이 나오기까지
- 빅데이터: 최소 1TB인 대용량의 데이터를 의미
- 빅데이터를 DB에 저장할 수 없다는 한계점이 발생함
-
때문에 저사양의 컴퓨터 여러 대에 분산 병렬 저장 및 처리해야 될 필요
- 스토리지를 추가하는 방식을 가장 먼저 사용 → 데이터 처리에 한계가 있음
- 대용량 병렬 처리
- 프로그램을 여러 부분으로 나눠 여러 프로세스가 각 부분을 동시에 수행
- 정형데이터 처리에 있어서 성능이 개선 됬지만 폭증하는 데이터의 처리에는 역부족
2. Hadoop의 특징
- 대용량 데이터를 분산처리하기 위한 프레임워크
- 기존의 RDBMS는 한 대의 서버만을 생각해서 제작된 소프트웨어이기 때문에 자원적인 측면에서 Scale Up을 해야되고 이에 대한 비용이 발생
- 하둡의 경우 저사양인 컴퓨터를 여러 대 사용하기 때문에 Scale Out 기법을 사용하며 초기 비용이 발생해도 전체적인 자원측면에서는 효율적이라고 할 수 있다.
- 실시간성은 아님
- HDFS(하둡 분산파일 시스템) 와 MapReduce(분산처리시스템) 으로 구성됨
- 데이터 처리를 위해 NoSQL 계열을 사용한다.
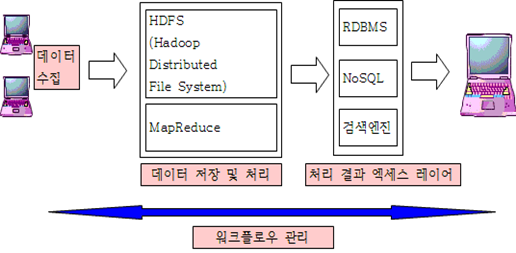
- NoSQL(No Structured Query Language)
- 정형화된 RDBMS의 테이블 분산환경을 위해 설계됨
- 기존의 RDBMS 보다 처리할 수 있는 양이나 트래픽이 거대하다.
- 주로 빅데이터 시스템 처리/분석을 위해 Hadoop과 NoSQL을 사용한다.
- MongoDB, HBase, Cassandra 등이 있다.
3. Hadoop 설치
- 환경: VMware 12 / CentOS 7 / JDK-1.8.x / Eclipse Oxygen / Hadoop-2.7.4
- Namenode는 RAM 2GB 서버-GUI, Datanode는 RAM 1GB 인프라 서버로 설치한다.
-
일반 사용자 계정은 hadoop으로 통일한다.
- 아래 내용은 하둡 바닐라 버전을 설치하는 것이니, 개인적으로 필요한 분은 참고하셔서 사용 부탁드립니다.
1) 가상환경
- VMware에서 CentOS 설치(총 3대 / Namenode 1대 , Datanode 2대)
- Namenode는 한글 키보드로 설치할 것
- VMware tool 설치
- Datanode에서는 yum을 사용해서 wget, vim, openssh-clients, rsync 패키지를 설치한다.
# yum -y install [설치 패키지 명]
## Minimal 에서의 설치 과정
# mkdir /mnt/cdrom
# mount /dev/cdrom /mnt/cdrom
# cp /mnt/cdrom/VMwareTools*.tar.gz /tmp
# umount /dev/cdrom
# cd /tmp
# tar -xf VMwareTools*.tar.gz
# cd vmware-tools-distrib
# ./vmware-install.pl
# ...(설치과정 / 모두 yes 처리)...
# vmware-toolbox-cmd timesync enable
* IP 설정 작업
# dhclient
# ifconfig eth0
...
# vi/etc/sysconfig/network-scripts/ifcfg-eth0
## 다음의 내용 입력
DEVICE=eth0
TYPE=Ethernet
UUID=8ca346d1-a621-433f-b045-36eeb03d7048
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=DHCP -> none 혹은 static 으로 변경
IPADDR=[IP주소]
PREFIX=24(or NETMASK 입력)
GATEWAY=[GATEWAY주소]
DNS1=[DNS 서버 주소]
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
HWADDR=00:0C:29:38:1E:72
LAST_CONNECT=1512857123
# ifconfig eth0 down
# ifconfig eth0 up
2) JDK 설치
(1) Namenode의 경우
- 일반계정으로 http://java.oracle.com 에서 Java SE -> jdk-8u151 kit 를 다운로드 받는다.
$ su -
root's Password:
# cd /usr/local
# tar -xf /home/hadoop/다운로드/jdk-8u151-linux-x64.tar.gz
# ls -l
# chown -R hadoop:hadoop jdk-1.8.0_151/
# rpm -qa | grep openjdk // CentOS에서만 초기 설치 시 같이 설치되어있음
...
# yum remove [openjdk 패키지명] // 총 2개가 존재하며 모두 삭제해준다.
# exit
$ cd ~
$ ls -al .bash_profile
$ vi .bash_profile
export PATH 부분을 지우고 다음 내용을 입력한다.
[vi Script]
export PATH=$PATH:$HOME/bin
export JAVA_HOME=/usr/local/jdk1.8.0_151
export HADOOP_INSTALL=/usr/local/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_INSTALL/bin
$ source .bash_profile //환경변수 적용
$ java -version // 현재 설치한 자바 버전인 1.8.0_151이 나오면 성공!
$ javac -version
(2) Datanode의 경우
- 설치하기 전에 hadoop 계정을 우선 생성한다. ```bash
useradd hadoop
passwd hadoop
…(비밀번호 설정)…
자바 설치
wget –no-check-certificate –header “Cookie: oraclelicense=accept-securebackup-cookie” http://download.oracle.com/otn-pub/java/jdk/8u151-b12/e758a0de34e24606bca991d704f6dcbf/jdk-8u151-linux-x64.tar.gz
cd /usr/local
tar -xf ~/jdk-8u151-linux-x64.tar.gz
chown -R hadoop:hadoop jdk1.8.0_151/
명령어 등록
alternatives –install /usr/bin/java java /usr/local/java/jdk1.8.0_112/bin/java 1
alternatives –install /usr/bin/java javac /usr/local/java/jdk1.8.0_112/bin/javac 1
alternatives –install /usr/bin/java javaws /usr/local/java/jdk1.8.0_112/bin/javaws 1
alternatives –set java /usr/local/java/jdk1.8.0_112/bin/java
alternatives –set javac /usr/local/java/jdk1.8.0_112/bin/javac
alternatives –set javaws /usr/local/java/jdk1.8.0_112/bin/javaws
su hadoop
이 후 내용은 Namenode의 경우와 동일함
## 3) Eclipse
- Namenode 만 설치
- 일반 계정으로 설치 진행
```bash
[hadoop@Namenode ~]$ mkdir jar
# 설치
[hadoop@Namenode ~]$ cd /usr/local/eclipse-installer/
[hadoop@Namenode eclipse-installer]$ ./eclipse-inst
실행
[hadoop@Namenode ~]$ cd eclipse/java-oxygen/eclipse
[hadoop@Namenode ~]$ ./eclipse
Workspace : /home/hadoop/workspace
- 바탕화면에 실행 파일 만들기
eclipse 실행파일 위치에 다음의 내용 작성하기[Desktop Entry] Version=Oxygen Name=eclipse Comment=Eclipse IDE Exec=/home/hadoop/eclipse/java-oxygen/eclipse/eclipse Path=/home/hadoop/eclipse/java-oxygen/eclipse Icon=/home/hadoop/eclipse/java-oxygen/eclipse/icon.xpm Terminal=false Type=Application Categories=Utility;Application;Development;
ln –s [eclipse 실행파일 경로] [hadoop 바탕화면 경로]
4) 도메인 설정
- 모든 노드에 동일하게 설정
# vi /etc/hosts
[Namenode IP주소] Namenode
[Namenode IP주소] backup
[Datanode1 IP주소] Datanode1
[Datanode2 IP주소] Datanode2
# service network restart
# ping Datanode1 // ping test 실시
5) 방화벽 설정
- 모든 노드에 동일하게 설정
[hadoop@Namenode 바탕화면]$ su -
[root@Namenode ~]# vi /etc/sysconfig/iptables
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
//해당 IP를 갖는 장비는 모두 연결할 수 있도록 설정(추가 부분)
-A INPUT -s 192.168.0.0/16 –d 192.168.0.0/16 –j ACCEPT
-A OUTPUT –s 192.168.0.0/16 –d 192.168.0.0/16 –j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
[root@Namenode ~]# service iptables restart
- CentOS 7의 경우 방화벽이 firewalld 이다.
- 또는 yum install iptables-services -> systemctl enable iptables 로 iptable을 설정하는 것도 가능하다.
6) 각 노드별 RSA 공개키 배포 및 공유
(1) 각 노드별 공개키 생성
[hadoop@Namenode ~]$ ssh-keygen -t rsa
[hadoop@Namenode 바탕화면]$ cd /home/hadoop
[hadoop@Namenode ~]$ ls -la (.ssh 만 있나 확인)
.....
drwx------. 2 Namenode Namenode 4096 2017-12-11 00:09 .ssh
......
[hadoop@Namenode ~]$ cd .ssh
[hadoop@Namenode .ssh]$ ls -l
합계 12
-rw-------. 1 hadoop hadoop 1675 2014-12-23 11:46 id_rsa //개인키
-rw-r--r--. 1 hadoop hadoop 394 2014-12-23 11:46 id_rsa.pub //공개키
(2) Namenode 공개키를 authorized_keys에 추가
[hadoop@Namenode .ssh]$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
[hadoop@Namenode .ssh]$ ls -l
합계 16
-rw-r--r--. 1 hadoop hadoop 394 2014-12-23 11:50 authorized_keys
-rw-------. 1 hadoop hadoop 1675 2014-12-23 11:46 id_rsa
-rw-r--r--. 1 hadoop hadoop 394 2014-12-23 11:46 id_rsa.pub
(3) 각 노드별 공개키 재분배 및 공유
[hadoop@Namenode .ssh]$ ssh hadoop@Datanode1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
The authenticity of host 'Datanode1 (192.168.164.131)' can't be established.
RSA key fingerprint is 8e:6b:98:d8:cd:c2:a4:00:25:ea:32:28:02:76:ba:b9.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'Datanode1,192.168.164.131' (RSA) to the list of known hosts.
hadoop@Datanode1's password:
[hadoop@Namenode .ssh]$ ssh hadoop@backup cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@Namenode .ssh]$ ssh hadoop@Datanode2 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(4) 모든 node에 공개키 재분배 한다
- 모든 노드에서 서로의 공개키를 공유한다.
[hadoop@Namenode .ssh]$ scp authorized_keys hadoop@Datanode1:~/.ssh/
[hadoop@Namenode .ssh]$ scp authorized_keys hadoop@backup:~/.ssh/
[hadoop@Namenode .ssh]$ scp authorized_keys hadoop@Datanode2:~/.ssh/
[hadoop@Namenode .ssh]$ ssh-add //Namenode에서만 해주면 된다
Identity added: /home/hadoop/.ssh/id_rsa (/home/hadoop/.ssh/id_rsa)
(5) 권한을 644로 수정
[hadoop@Namenode .ssh]$ ls -la /home/hadoop/
[hadoop@Namenode .ssh]$ chmod 644 ~/.ssh/authorized_keys
[실습]
[hadoop@Namenode .ssh]$ ssh hadoop@Namenode date
[hadoop@Namenode .ssh]$ ssh hadoop@backup date
[hadoop@Namenode .ssh]$ ssh hadoop@Datanode1 date
[hadoop@Namenode .ssh]$ ssh hadoop@Datanode2 date
[hadoop@Datanode1 .ssh]$ ssh hadoop@Namenode date
[hadoop@Datanode1 .ssh]$ ssh hadoop@backup date
[hadoop@Datanode1 .ssh]$ ssh hadoop@Datanode1 date
[hadoop@Datanode1 .ssh]$ ssh hadoop@Datanode2 date
[실습]
※ Namenode에서 Datanode1으로 로그인
[hadoop@Namenode ~]$ ssh Datanode1
Last login: Wed Feb 17 13:57:38 2016 from Namenode
[hadoop@Datanode1 ~]$
※ Datanode1에서 Namenode으로 로그인
[hadoop@Datanode1 ~]$ ssh Namenode
hadoop@Namenode's password:
Last login: Wed Feb 17 14:55:15 2016 from Datanode1
[hadoop@Namenode ~]$
※ could not open a connection to your authentication agent. 에러 발생 시 조치
- eval
ssh-agent -s - ssh-add
7) 하둡 환경 설정 파일 수정
- Namenode에서 진행
- /usr/local/hadoop-2.7.4/etc/hadoop 아래에 위치한 파일들로 다음 순서대로 설정한다.
(1) hadoop-env.sh
- 하둡에게 JDK설치 경로 등록 -> 하둡도 자바에 의해서 컴파일 되기 때문
[hadoop@Namenode hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
...
export HADOOP_PID_DIR=/usr/local/hadoop-2.8.2/pids
- 맨 마지막에 다음의 내용을 추가한다.
export HADOOP_OPTS="$HADOOP_OPTS-Djava.library.path=/usr/local/hadoop-2.7.4/lib/native"
# -> 설치한 os가 64bit 여서 native 에러가 발생하는 것을 막기 위해서 추가하는 것
(2) Namenodes
-보조 네임노드를 실행할 서버 등록하는 파일 -한 대로 하려면 localhost로 지정.
[hadoop@Namenode hadoop]$ vi Namenodes
backup
(3) Datanodes
- 데이터 노드를 실행할 서버 설정
- 한 대로 하려면 localhost 지정. (default로 지정되어 있음)
- 데이터 노드가 여러 개이면 라인단위로 서버이름을 설정하면 된다 ``` [hadoop@Namenode hadoop]$ cat Datanodes localhost->삭제
[hadoop@Namenode hadoop]$ vi Datanodes
Datanode1 Datanode2
### (4) core-site.xml 파일 수정
- 로그파일, 네트워크 튜닝, I/O 튜닝, 파일 시스템 튜닝, 압축 등 하부 시스템 설정파일
- core-site.xml 파일은 HDFS와 맵리듀스에서 공통적으로 사용할 환경정보 설정
- hadoopcore-1.x.x.jar 파일에 포함되어 있는 core-default.xml을 오버라이드 한 파일
- core-site.xml에 설정 값이 없을 경우 core-default.xml에 있는 기본 값을 사용
* 공통 속성들에 대한 자세한 설명은 다음 주소를 참고<br>
→ http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
```bash
[hadoop@Namenode hadoop]$ vi core-site.xml
...
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://Namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.4/tmp</value>
</property>
</configuration>
(5) hdfs-site.xml 수정
- 데이터 저장 경로 변경
- hdfs-site.xml 파일은 HDFS에서 사용할 환경 정보를 설정한다.
- hadoop-core-2.2.0.jar 파일에 포함되어 있는 hdfs-default.xml을 오버라이드 한 파일
-
hdfs-site.xml에 설정 값이 없을 경우 hdfs-default.xml에 있는 기본 값을 사용
- HDFS 속성들에 대한 자세한 설명은 다음 주소를 참고.
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
[hadoop@Namenode hadoop]$ vi hdfs-site.xml
...
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>Namenode:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>backup:50090</value>
</property>
</configuration>
(6) mapred-site.xml 파일 수정
- mapred-site.xml 파일은 맵리듀스에서 사용할 환경정보를 설정한다.
- hadoop-core-x.x.x.jar 파일에 포함되어 있는 mapred-default.xml을 오버라이드 한 파일
- mapred-site.xml에 설정 값이 없을 경우 mapred-default.xml에 있는 기본 값을 사용
만약 mapred-site.xml이 존재하지 않을 경우 mapred-site.xml.template를 복사하여 사용
[hadoop@Namenode hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@Namenode hadoop]$ vi mapred-site.xml
...
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>Namenode:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(7) yarn-site.xml
- 수정 안함, default설정 따름, 그런데 mapred-site.xml에서 yarn을 선택했을 경우 내용 추가
- 맵리듀스 프레임워크에서 사용하는 셔플 서비스를 지정한다
- yarn: spark 등의 프레임워크가 동작할 수 있도록 만들어주는 일종의 마더보드 역할을 수행
[hadoop@Namenode hadoop]$ vi yarn-site.xml
...
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>[Namenode의 IP]</value>
</property>
</configuration>
8) Namenode 에서 배포
- Datanode 에서는 root 계정으로 로그인 후 /usr/local의 위치에 hadoop-2.7.4 폴더 생성
-
Namenode의 경우 다음의 과정을 진행한다.
- rsync : 지정한 폴더 아래의 모든 파일을 네트워크를 통해 전송시키는 원격접속 서비스
# cd /usr/local/hadoop-2.7.4
# rsync -av . hadoop@backup:/usr/local/hadoop-2.7.4/
# rsync -av . hadoop@Datanode1:/usr/local/hadoop-2.7.4/
# rsync -av . hadoop@Datanode2:/usr/local/hadoop-2.7.4/
9) NameNode 초기화
- Hadoop을 구성할 시 초기에 format 해주는 과정
- 네임노드는 최초 한 번만 실행하면 되며 만약 에러메세지가 있을 경우 환경설정파일이 잘못된 것이므로 수정후에 다시 실행해야된다.
[hadoop@Namenode ~]$ cd /usr/local/hadoop-2.7.4/bin
[hadoop@Namenode bin]$
[hadoop@Namenode bin]$ ./hdfs namenode -format
(1) 프로세스 실행
[hadoop@Namenode sbin]$ pwd
/usr/local/hadoop-2.7.3/sbin
[hadoop@Namenode sbin]$ ./start-dfs.sh
[hadoop@Namenode sbin]$ ./start-yarn.sh
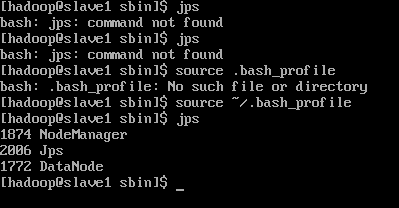
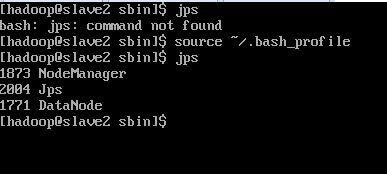
[hadoop@Namenode sbin]$ jps
4147 DataNode -----------------------> backup(Datanodes 에 설정된 backup)
12373 NameNode
12703 SecondaryNameNode ----------> backup(Namenodes 에 설정된 backup)
12851 ResourceManager
13451 Jps
9590 NodeManager
13392 JobHistoryServer
[hadoop@Datanode1 sbin]$ jps
6001 DataNode
6103 NodeManager
6350 Jps
- 브라우저에서도 확인
- http://Namenode:50070 또는 http://Namenode:50070/dfshealth.html 실행후 파일 시스템 상태 보여야 함
- 1.x의 JobTracker는 http://Namenode:8088/cluster 에서 확인할 수 있음
- 콘솔에서도 확인
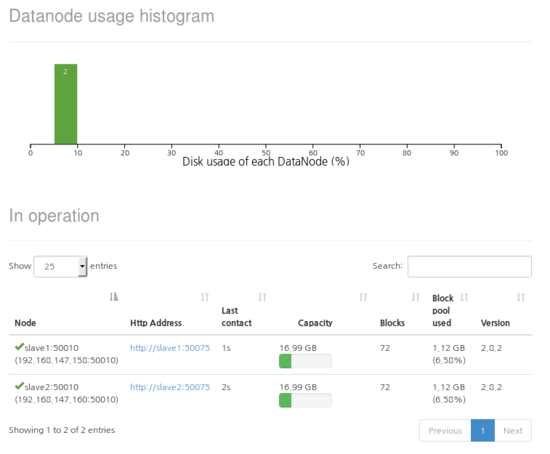
[hadoop@Namenode hadoop]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[hadoop@Namenode sbin]$ hdfs dfsadmin –report
[결과]

댓글남기기